Release Notes
July 2026
We now capture deletes for the ASSET_OBJECT table using the _fivetran_deleted column. Perform a resync to backfill historical data.
May 2026
You can now authenticate your Jira connection using a service account. For more information, see our setup instructions.
We now sync archived projects for Jira Cloud connections. This feature is not available for Jira on-premise. Archived projects are included in the PROJECT table alongside active projects.
We have added three new columns to the PROJECT table:
archivedarchived_datearchived_by_id.
We have added a new column, _fivetran_deleted, to the PROJECT_ROLE and PROJECT_ROLE_ACTOR tables.
April 2026
We now support Unstructured File Replication for our Jira connector. To support this enhancement, we have added a new toggle, Sync Jira files to your destination's object storage, to the connection setup form. This feature is available only for Jira Cloud connections. For more information, see our setup instructions. We are gradually rolling out this enhancement to all existing connections.
We have added a new column, _fivetran_file_path, to the ATTACHMENT table to store the file path used for unstructured file replication and is constructed from the attachment ID and filename.
March 2026
We've added the following columns to the ATTACHMENT_METADATA table:
content_urlthumbnail_urlfilenameauthor_idcreatedmime_typefile_size
The connector now processes all attachment types from issues, not just ZIP files. For non-ZIP attachments, the table stores standard attachment metadata including download URLs, file information, and author details from the issue's attachment field.
January 2026
We've added a new table, ISSUE_FORM.
We have added a new column, group_id, to the USER_GROUP table.
November 2025
We have added a new column activatedDate to the SPRINT table.
Row filtering is now supported for the following connectors:
To learn how to use row filtering and see the list of supported connectors, see our row filtering documentation.
October 2025
We unified each connector’s pre-built dbt Core–compatible data models into a single model. It standardizes and documents the Fivetran schemas created in your destination and outputs analytics-ready tables. Previously, most connectors used distinct source and transform models.
September 2025
We've changed the data type of the id column in the ASSET_REFERENCE_TYPE table from INTEGER to STRING.
July 2025
We have added the following columns to the COMMENT table:
visibility_typevisibility_identifiervisibility_value
These columns allow you to understand which comments are restricted to specific groups or roles in your Jira instance. Comments without visibility restrictions will have null values in these columns, meaning they are visible to all users with access to the issue.
We have added a new table, REQUEST_COMMENT, to store the comments associated with requests. We are gradually rolling out this change to all existing connections.
Our Jira connector now supports OAuth 2.0 3LO authorization. We are gradually rolling out this change to all existing connections. See the connector's setup guide for more details.
January 2025
We have added a new column, driver, to the VERSION table.
We have added a new column, simplified, to the PROJECT table.
We have added a new table, ISSUE_PROPERTY, with the following columns:
issue_idkeyselfvalue
We have added a new table, WORKLOG_PROPERTY, with the following columns:
worklog_idkeyselfvalue
We have added a new table, ATTACHMENT_METADATA, with the following columns:
attachment_idindexlabelmedia_typepathsize
November 2024
We have added two new tables, FIELD_PROJECT and ISSUE_USER_VOTE.
- The
FIELD_PROJECTtable is only available for Jira Cloud instances. You must grant Fivetran theAdminister Jiraglobal permission to fetch the custom fields project's mapping data. - To capture
ISSUE_USER_VOTEdata, you must set the Allow users to vote on issues option to ON in your Jira account's general configurations.
We are gradually rolling out these changes to all existing connections. Perform a re-sync to fetch the historical data of the new tables.
October 2024
You can now exclude the following tables from your syncs:
USERUSER_GROUPPROJECT_ROLEPROJECT_ROLE_ACTOR
On your connector details page, go to the Schema tab and deselect the tables you want to exclude.
We now sync the description column in the FIELD table. The description of the following fields are available:
systemandcustomfor Jira Cloud instancescustomfor Jira On-Premises instances
We are gradually rolling out this feature to all connections.
To fetch field description data, Fivetran needs the Administer Jira global permission granted.
We have added support for the following tables:
ASSET_OBJECTASSET_OBJECT_SCHEMAASSET_OBJECT_ISSUEASSET_OBJECT_TYPEASSET_OBJECT_TYPE_ATTRIBUTEASSET_OBJECT_TYPE_ATTRIBUTE_OBJECTASSET_SCHEMA_STATUSASSET_REFERENCE_TYPEThe tables sync Assets data. We are gradually rolling out this change to all connections.
Fivetran has created a dbt Core-compatible app reporting model that generates an end model containing unstructured document data to be used for Retrieval Augmented Generation (RAG) applications leveraging Large Language Models (LLMs).
The Unified RAG model supports the HubSpot, Jira, and Zendesk Support connectors.
Learn more in our Unified RAG model documentation.
May 2024
We now support Remote Issue Links. We are gradually rolling out this feature to all existing connections. Once it's available for your connector, you will find the ISSUE_REMOTE_LINK table in your destination. To learn more, see Jira's Remote Issue Links documentation.
April 2024
We now support all Jira field types. This feature is available to all Jira connections set up after April 1, 2024. Learn more in our Jira documentation.
Additionally, we have added a new column, dimension_table, to the FIELD table.
February 2024
We have added a new table, SPRINT_BOARD, to store information on sprint and board relationships.
The SPRINT.board_id column stores the ID of the board the sprint was originally added to.
August 2023
You can now exclude the ISSUE_BOARD and PROJECT_BOARD tables of the BOARD group from your sync.
On your connector details page, go to the Schema tab and deselect the tables you want to exclude.
July 2023
You can now manually register the webhook to capture deleted entities even if you don't grant the Administer Jira global permission to the connecting user. Learn more in our Jira setup guide.
To support the Atlassian Teams Coming to Jira Software change, we have added additional columns to the TEAM table. The TEAM table now contains the following columns:
idnametitleis_sharedis_visible
We are gradually rolling out this change to all existing connections.
February 2023
We have added a new column, is_active, to the USER table.
November 2022
We have added a new column, state, to the SPRINT table.
September 2022
Now we write information about the actual sprint start date stored in the activated_date field, to the start_date column of the SPRINT table in the destination.
This feature is relevant for Jira Server (On-Premise) versions 8.8 and above.
August 2022
We have excluded the SPRINT table from the BOARD group of tables in the Schema tab of your connector. We sync all sprints entirely when you select the BOARD group of tables in the Schema tab.
July 2022
Now you can connect to your Jira Cloud instance using an API token. Now you can connect to your Jira on-premise instance using an application link. Refer to our Jira Setup Guide for details.
June 2022
Now we use webhooks to keep the sprints in the up-to-date state in the destination.
To use webhooks, you must have the Jira Administrators global permission.
As an alternative, we have added the SPRINT table to the BOARD group of tables, and now we sync all sprints entirely for particular board once a day.
May 2022
We now sync the Affected Services, Customer Request Type, and Approvals fields with a customer request from Jira Service Management (formerly Jira Service Desk). We sync the Affected Services, Customer Request Type, and Approvals fields into the following tables:
APPROVALAPPROVERREQUESTREQUEST_TYPESERVICE
See the Jira ERD for more information.
We are gradually rolling out this feature to all existing connections. When it's available for your connector, you will see the tables above on the Schema tab. To fetch data for all issues, re-sync your connector.
Previously, we only synced the name subfield in the Customer Request Type field. We kept this logic for compatibility. See the January 2021 Release Notes for more information.
April 2022
We now sync issue watchers to the ISSUE_WATCHER table. We are gradually rolling out this feature to all existing connections. Once this feature is available, you will see the ISSUE_WATCHER table on the Schema tab. To fetch data for all issues, re-sync your connector.
We apply this feature both to new issues and existing issues once they are changed. Fivetran does not consider assigning and unassigning issue watchers a change in an existing issue since there is no initial state in an existing issue for us to compare to.
March 2022
We now sync the following ISSUE custom field types:
Ranksyncs to your destination as alexorank algorithmstring.Teamsyncs to your destination as an integer value. The integer acts a team identifier. We have also added a new table,TEAM, that contains additional team data.
To learn how we sync custom fields for Jira, see our June 2020 release note.
February 2022
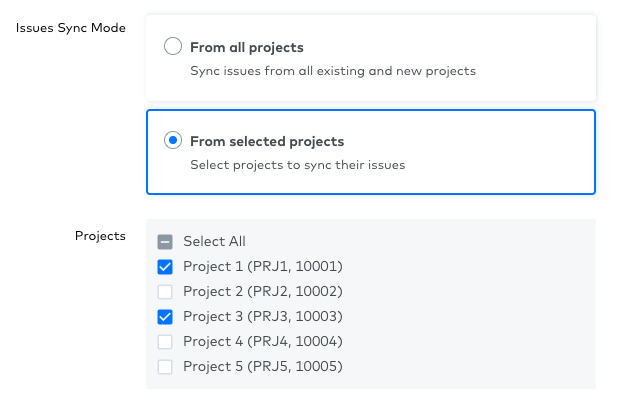
You can now select Projects in the setup form to sync only their associated issues.
January 2022
We now sync the goal field of the sprint to the SPRINT table.
November 2021
Now, we store a separate cursor for each project and use it to track updates in project issues. We can now sync all issues regardless of when the connecting user in your Jira instance was granted permissions for the relevant projects. Previously, we had a single cursor for all issues. When the user was granted permissions for a project after the initial sync had completed, we were not able to capture the old issues created before the user was granted permissions.
We now fetch issues in parallel threads, one for each project, which improves the extract time of the connector. We are gradually migrating all existing connections to this new mode.
October 2021
You can now specify the Consumer Key in the connector setup form while creating an application link between Fivetran and your Jira installation. Previously, it was impossible to create an application link if the Consumer key we provided was used by another external application in your Jira installation.
September 2021
We now capture deleted projects using webhooks. We're gradually rolling out to all existing connections.
We can't capture projects that were deleted before your Jira connector registered the webhook in your Jira installation.
August 2021
Now, if your Jira installation returns an HTTP 500 Internal Server error during a sync, we only skip the relevant issue field records from the sync. Previously, the entire sync failed.
June 2021
We now sync system Jira fields, such as project andpriority, even if there are custom fields with the same names. Previously, we skipped all fields that had the same names. This feature applies to connectors set up before September 10, 2020. Connections created after this date sync all fields regardless of the names.
We have added a new field, is_active, to the ISSUE_FIELD_HISTORY and ISSUE_MULTISELECT_HISTORY tables. The field allows you to assemble the complete current state of an issue without a full table scan. It is true for the current issue records and false for historical issue records. To get values in the is_active field for all issues, re-sync your connector. We are gradually rolling out this feature to connections set up after September 10, 2020.
May 2021
We have added a new column, author_id, to the ISSUE_FIELD_HISTORY and ISSUE_MULTISELECT_HISTORY tables.
This column stores the identifiers of the users who made changes to a given Jira issue. This feature applies to all connectors set up after September 10, 2020. Re-sync your existing connector to sync this data for all historical changes.
April 2021
Now you can sync the following table groups by selecting the relevant group checkbox on the Schema tab of the connector details page:
BOARD,ISSUE_BOARD,PROJECT_BOARDPERMISSION_SCHEME,PERMISSION,PERMISSION_HOLDERSECURITY_SCHEME,SECURITY_LEVEL,SECURITY_SCHEME_LEVEL.
When sync is enabled for any of these groups, all tables within the selected groups are re-synced once a day.
Now we sync the historical changes of the key field.
March 2021
We now sync entries related to Jira permissions. We are gradually rolling out this feature to all existing connections. Once this feature is available for your connector, you will see the following items in your destination:
- The
PERMISSION,PERMISSION_SCHEME,PERMISSION_HOLDER,PROJECT_ROLEtables - The
permission_scheme_idcolumn in thePROJECTtable See Jira Schema Information section for details.
We have added a new column, _fivetran_deleted, to the FIELD table. Now we capture custom fields deleted from source.
We now sync the Security Level field.
We now sync Issue Security Schemes. We are gradually rolling out this feature to all existing connections. Once this feature is available for your connector, you will see the SECURITY_SCHEME, SECURITY_LEVEL, and SECURITY_SCHEME_LEVEL tables in your destination.
February 2021
We now support the Satisfaction and Satisfaction date fields of Jira Service Management (formerly Jira Service Desk).
Our Jira connector no longer uses the use_webhooks configuration field.
January 2021
We now use the X-Force-Accept-Language header to get responses in English. This applies to all Jira connections created after February 1, 2021.
We now support the name subfield in the Customer Request Type field of Jira Service Management (formerly Jira Service Desk).
December 2020
We now automatically capture deletes for Jira connections. We have removed the "Capture deletes" toggle from the connector setup form. To be able to capture deletes, you must have the Jira Administrators global permission. We cannot capture deleted issues that were deleted before sync deletes was enabled. To get all deleted issues, re-sync your connector.
We have released pre-built, dbt Core-compatible data models for Jira. Find the models in Fivetran's dbt hub or data models documentation. Learn more about our dbt Core integration in our Transformations for dbt Core documentation.
We have fixed capturing of array fields such as components and fixVersions in the ISSUE_MULTISELECT_HISTORY table. Now we write null instead of "0" for empty values. The value and _fivetran_id column values for the relevant records will be updated during the next sync.
November 2020
We now fully support the cascading select fields in Jira issues. We've added a new parent_id column, which refers to the parent value, to the FIELD_OPTION table. To sync fields of this type for all issues, re-sync your connector.
October 2020
We have improved how we sync historical changes for the standard issue array fields components, fixVersions, and versions. We now write the actual values for each historical change, making the table much easier to use. The Jira API delivers empty values if part of the value is removed, and previously we just wrote that empty value.
We now support the Jira Service Management (formerly Jira Service Desk) Organization fields in Jira issues. To sync fields of this type for all issues, re-sync your connector.
September 2020
We enable the improved schema by default for connectors set up after September 10, 2020. See our June 2020 release note for details about the improvements, which were previously opt-in, but are now default.
August 2020
We have added a new column, is_public, to the COMMENT table.
We have improved the mechanism that detects similar fields that might cause data integrity issues. When we detect that similar field names would become duplicate names after normalization, we do not sync them to your destination. Instead, we show a warning on your dashboard and ask you to rename the fields. This prevents duplicates in the destination and avoids writing the values of the different fields into the same history table.
To prevent data integrity issues, we will sync some standard fields in the following way:
Σ Original Estimatefield to theISSUE_AGGREGATE_ORIGINAL_ESTIMATE_HISTORYtableΣ Time Spentfield to theISSUE_AGGREGATE_TIME_SPENT_HISTORYtableΣ Remaining Estimatefield to theISSUE_AGGREGATE_REMAINING_ESTIMATE_HISTORYtableΣ Progressfield to theISSUE_AGGREGATE_PROGRESS_HISTORYtable.
We have also improved the mechanism that detects the Jira changelog to avoid syncing values from one field into multiple history tables.
July 2020
We have changed the styling of the connector name from "JIRA" to "Jira" in the Fivetran dashboard to match Atlassian's official styling.
June 2020
We have added a new way to sync issue field values and their historical changes. Previously, users whose ISSUE table had a large number of fields found that it was generating an overwhelming amount of ISSUE_[FIELD_NAME]_HISTORY tables.
Now, the ISSUE table contains only columns for the Jira standard fields.
We added a FIELD table that contains information about all fields. We sync all values from the custom non-array fields and their history items to a single ISSUE_FIELD_HISTORY table. We sync all values from the array fields and their history items to a single ISSUE_MULTISELECT_HISTORY table. We sync initial null values from history items to the history tables to provide a better historical analysis.
If you would like to use this new method, contact our support team to enable it. Then, create a new connector or re-sync the existing one.
We have improved the mechanism that detects the changelog. Now, if a fieldId is not present in the Jira response, we will find the changelog entries using a fieldname. This improvement prevents data integrity issues when the current field value is written into the history table as initial.
May 2020
You can now configure your Jira connector using the Fivetran REST API. This feature is in BETA and available only for Standard and Enterprise accounts.
March 2020
Previously, when there were multiple changes in the source during the sync, our connector sometimes missed some data. We have fixed this problem by changing our pagination strategy. To ensure that all your data is synced, re-sync your connector.
January 2020
When the value of a field was null, our Jira connector didn't always update array values. That meant that, for example, if the value was removed from a field in the source, sometimes the destination still showed the previous value. Now when a field value is null, our Jira connector will write a default empty value according to the type of the field.
Our Jira connector can now sync issues from January 1, 1970 forward. Previously, our connector only synced issues from January 1, 2002 forward. If you have issues from 1970-2002, perform a re-sync to ensure that we capture all issues.
September 2019
We can now sync empty array type fields, such as labels. This means that any removed values will be accurately reflected in the destination. Previously, we could not sync array fields with null values, which meant that some values deleted in the source were not deleted in the destination.
We now track deletes in the WORKLOG table. This means that any deleted work logs will be accurately reflected in the destination.
August 2019
We now support SLA fields in Jira issues. We are gradually rolling out this feature to all our connections.
When it's available for your connector, you will see an additional SLA table in your destination. You can see the SLA table on our Jira ERD. To sync all SLA fields, re-sync your connector.
July 2019
We now support capturing deleted issues by using webhooks. We are gradually rolling out this feature to all existing connections. When it's available for your account, you will see a Capture deletes toggle on the Jira connector setup form. To enable capturing deletes, set the toggle to ON.
May 2019
We have added a new table, WORKLOG. To sync the WORKLOG table, create a new connector or re-sync the existing one.
April 2019
Jira has deprecated the field key and replaced it with account_id.
Because we used key to form the primary key in the USER and USER_GROUP tables, we have made changes to those two tables:
- In the
USERtable,account_idnow populates theidcolumn. - In the
USER_GROUP, tableaccount_idnow populates theuser_idcolumn.
This change will cause the USER and USER_GROUP tables to have duplicated records based on our previous primary keys for them which were based on the deprecated key. To remove duplicate data in the USER and USER_GROUP tables, drop the USER and USER_GROUP tables and perform a full re-sync.
February 2019
The PROJECT table will have key and project_type_key columns either after re-sync or for all new Jira connections.
May 2018
We have dropped the primary key constraint from the value column in the ISSUE_[FIELD]_HISTORY and ISSUE_[FIELD] tables.
April 2018
We now remove the relationship between an issue and an issue label if the issue is removed in Jira.
If you deploy your Jira to a custom root path, you can now specify that path in our setup form: