Oracle Fusion Cloud Applications
Oracle Fusion Cloud Applications is a suite of SaaS applications for business functions.
Supported services
Fivetran supports the following Oracle Fusion Cloud applications:
- Customer Experience - Oracle Fusion Cloud Applications - CRM connector
- Enterprise Resource Planning - Oracle Fusion Cloud Applications - FSCM (ERP & SCM) connector
- Supply Chain Management - Oracle Fusion Cloud Applications - FSCM (ERP & SCM) connector
- Human Capital Management - Oracle Fusion Cloud Applications - HCM connector
Sync overview
Fivetran uses Business Intelligence Cloud Connector (BICC) to sync data from Oracle Fusion Cloud applications to your destination.
Once we connect to your Oracle instance, we create the following BICC extract jobs for each object:
- Data job to extract data.
- Active PK job to extract active primary keys.
We use the query filters of these jobs to fetch incremental data from your Oracle Fusion Cloud applications. The connectors manage the life cycle of these jobs.
During syncs, the connections create submit schedules for the BICC jobs. We extract the data files from Oracle UCM and sync the data to your destination.
Learn more about the Oracle BICC use cases in our documentation.
Capturing deletes
We use the BICC Extract Active Primary Key job to fetch the list of active records. We mark the non-active records as deleted.
Configuring delete capture frequency
You can choose the frequency for capturing deletes for your Oracle Fusion Cloud Applications connections. In the Delete Capture Frequency drop-down menu, you can select from the following frequencies:
- Every sync (default)
- Every day
- Every week
- Never
If you disable delete capture and later re-enable it, the next sync captures all previously missed deletes, which can increase sync time.
Re-import Objects
If an object doesn't have incremental filter then Oracle treats that object as a re-import object. Fivetran in that case extracts all the rows even in incremental syncs, which increases MAR. See our Oracle Fusion Cloud setup guides to enable incremental extract for custom objects.
The length of the query filters in BICC jobs is limited to 4000 characters. If the length exceeds 4000 characters, we treat the incremental objects as re-import objects.
Syncing custom objects
We support syncing custom objects. You must add the custom object to an offering and select the primary keys in the custom objects. For more information, see our Oracle Fusion Cloud setup guides.
Schema information
The connectors sync the View Objects as they are available in the Oracle Fusion databases.
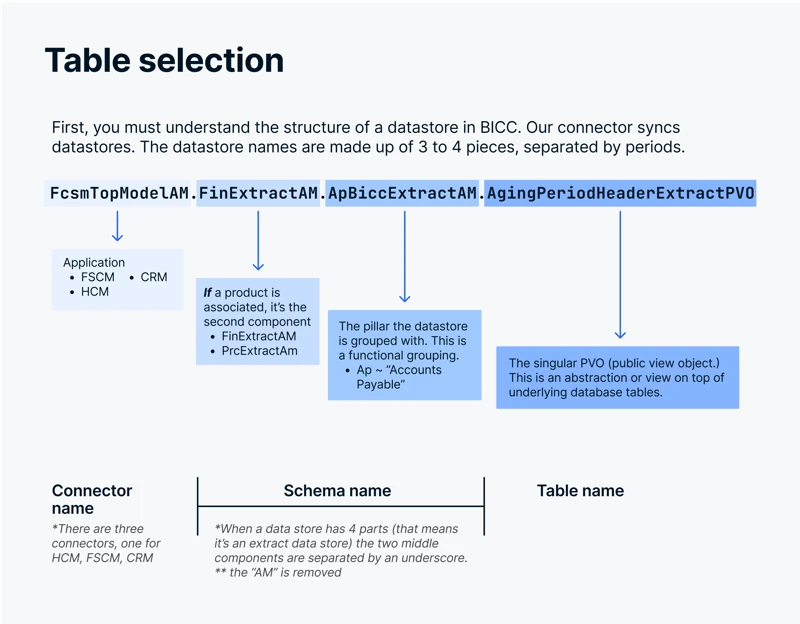
View Objects are referred to as datastores in the source. The datastores consist of three or four parts which are separated by periods.
We split the datastores when naming tables and schemas. We name tables after the last component. We name the schema after the product (if present) and the pillar (removing the AM suffix if it is present).
We remove the AM suffix if is present in the product or pillar name. We don't remove any suffix from the product or pillar name if it ends with any suffix other than AM.
Schema naming
Some datastore names have three parts (Application.Pillar.Table), while some have four parts (Application.Product.Pillar.Table).
Schema names in the source
In three part datastore names (Application.Pillar.Table), the second component (Pillar) would be the schema name (removing the AM suffix if present) and the last component (Table) would be the table name.
For example:
- Datastore name:
FscmTopModelAM.FinArTopPublicModelAM.TransactionLinePVO - Schema name in source:
FinArTopPublicModel - Table name:
TransactionLinePVO
In four part datastore names (Application.Product.Pillar.Table), the second and third component (Product_Pillar) would be the schema name (removing the AM suffix if present) and the last component (Table) would be the table name.
For example:
- Datastore name:
FscmTopModelAM.FinExtractAM.XlaBiccExtractAM.SubledgerJournalDistributionExtractPVO - Schema name in source:
FinExtract_XlaBiccExtract - Table name:
SubledgerJournalDistributionExtractPVO
Schema names in the destination
In destination, the schema name would be destinationSchemaPrefix_schemaNameInSource, where destinationSchemaPrefix is the schema name you set in the setup form.
Oracle Fusion Cloud Apps connectors use Standard Renaming Rules for schema and table names in the destination.
View object to database lineage mapping
You can review the mapping of the View Objects to their corresponding database tables and Oracle connectors in the following lineage mapping spreadsheets:
| Data Source | Oracle Lineage Mapping Spreadsheet |
|---|---|
| Customer Experience (CX) | Mapping Spreadsheet |
| Enterprise Resource Planning (ERP) | Mapping Spreadsheet |
| Supply Chain Management (SCM) | Mapping Spreadsheet |
| Human Capital Management (HCM) | Mapping Spreadsheet |
Oracle ERP and Oracle SCM share the same lineage mapping spreadsheet because Oracle treats both the applications as the Financials and Supply Chain Management (FSCM) application.
You can download the consolidated database lineage mapping spreadsheet for the Financials and Supply Chain Management (FSCM) and Customer Experience applications.
Schema notes
Fivetran only supports Universal Content Management (UCM) for storing the BICC extract job files.
Fivetran creates and manages the BICC extract jobs. Do not manually edit the Fivetran jobs or create schedules.
Fivetran only syncs the default columns for all the data stores. In the data store, the default columns have the Select List checkbox selected. To sync a non-default column, select the Select List checkbox. You can customize the data store in the Oracle BICC Console.
In the BICC Console, you must customize the data store itself and not the jobs associated with the datastore.
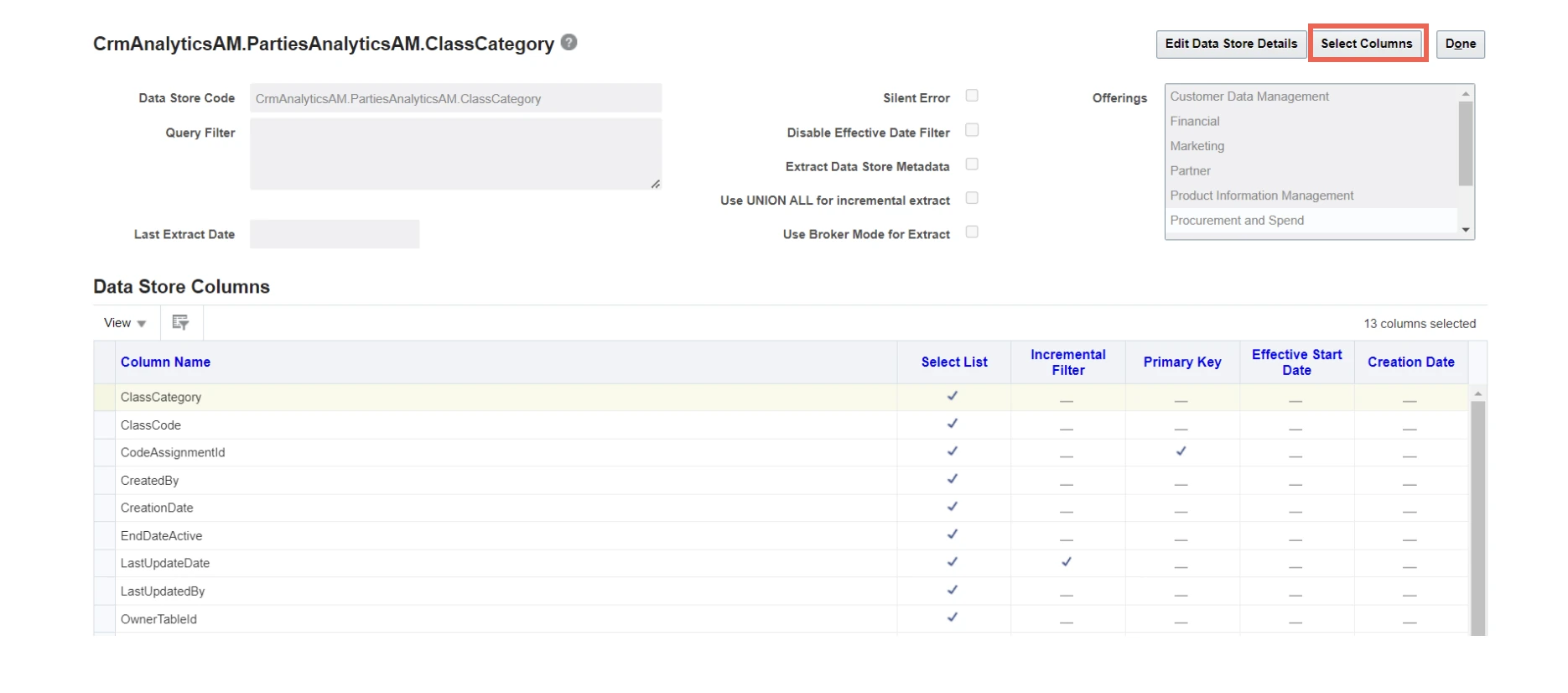
Expand for the steps to add columns in data store
Use the following steps to customize your data store and add columns in a data store:Log in to Fusion BICC using
https://<instance-name>/biacm/faces/setupClick Manage Offerings and Data Stores.
Select the offering in which your datastore is configured.
If the datastore is configured to multiple offerings, you can select any one of them.
Search and select the datastore you want to customize.
Click Select Columns.
In the Select List column, select the checkboxes corresponding to the columns names that you want to add to the datastore.
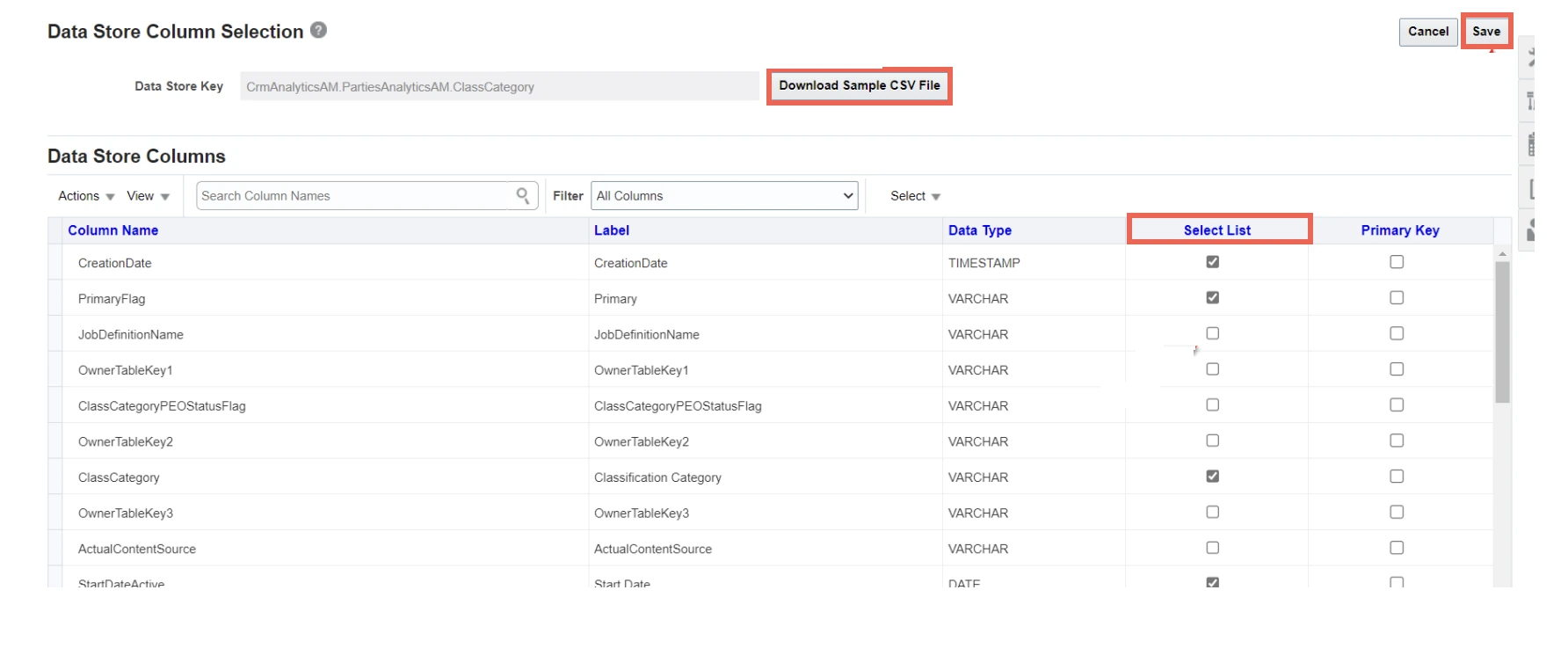
Click Save.
If you want to download and validate the sample CSV file, click Download Sample CSV File.
Fivetran marks source tables as Excluded By System in the connection dashboard:
- If the datastore is not part of an offering.
- If the datastore does not contain a primary key.
- If the datastore contains more than 1000 default columns (Oracle doesn't support retrieving more than 1000 columns for a data store).
The connectors perform an automatic re-import:
- We need the Active PK job schedule file from the previous sync to capture deletes. If the Active PK job schedule file is deleted, we perform a re-import to capture the deletes.
- We need access to the active primary keys file to capture deletes. By default, the files are removed from UCM in 90 days. If the previous files are removed, we perform a re-import to capture the deletes.
Fivetran converts the data types for the following columns to DOUBLE irrespective of their original data type in Oracle Fusion Cloud applications:
FaBalanceExtractBeginningBalancecolumn in theFA_BALANCES_EXTRACT_PVOtablereverse_uom_ratecolumn in theUOM_INTERCLASS_PVOtable
Fivetran converts the data types for columns with
amount,duration,price, andweightingsuffixes from NUMERIC to DOUBLE in the destination.Fivetran converts the data types for columns where the
scalevalue is not equal0orprecisionvalue is greater than18, from NUMERIC to DOUBLE in the destination.
Syncing empty tables and columns
Fivetran can sync empty tables for your Oracle Fusion Cloud Applications. Fivetran can sync empty columns only if the column data types are known. For Oracle Fusion Cloud Applications connection, Fivetran infers the column data types other than VARCHAR, DATE, TIMESTAMP, and NUMERIC, as unknown.
Unsupported data types
The connectors don't support the BLOB and CLOB data types.