Functions
Fivetran users who signed up on or after July 22, 2025, no longer have access to Function connections. Older Fivetran users can continue to create and use Function connections as before. All our users can use Connector SDK to build custom connectors. Connector SDK provides a streamlined development experience, and we'll host your custom connector for you.
Function connectors allow you to code a data connection as an extension of Fivetran. For example, if you have a custom data source or a private API that we don't support, you can develop a serverless ELT data pipeline using our Function connectors.
Building a custom data pipeline from scratch is complicated. It’s even harder to maintain. When you use a Function connection with your custom function, you only have to write the cloud function to extract the data from your source. We will load and transform the data in your destination. You can use our Function connectors and serverless platforms to build robust data pipelines faster than traditional monolithic orchestration platforms.
A developer can use our templates to create data pipelines that deploy and manage themselves. Cloud functions allow Fivetran to work with code to support custom data sources. Fivetran executes the code in your account on the cloud platform and syncs the returned data to your destination.
Our Function connectors have the same intrinsic capabilities as standard Fivetran connectors:
- Incremental updates
- Source data type inference
- Automatic schema updates
- Data de-deduplication
- Destination ingestion optimizations
- Logs and alerts to monitor events and troubleshoot issues
- Soft delete
Use Fivetran's Function connectors if:
- Fivetran doesn't have a connector for your source
- You are using private APIs or custom applications
- You are using a source or API that Fivetran is unlikely to support in the near future
- You want to sync unsupported file formats that require pre-processing
- You have sensitive data that needs filtering or anonymizing before entering the destination
Additional benefits of using a cloud function with Fivetran:
- Your function runs within your Virtual Private Cloud
- Unified logging and alerting system
- Multi-language support
- Built-in setup tests
Function connections count towards MAR. You will also have to pay for the function to be run by the infrastructure provider.
Supported services
Architecture
The following diagram provides a high-level overview of how Fivetran executes a cloud function:
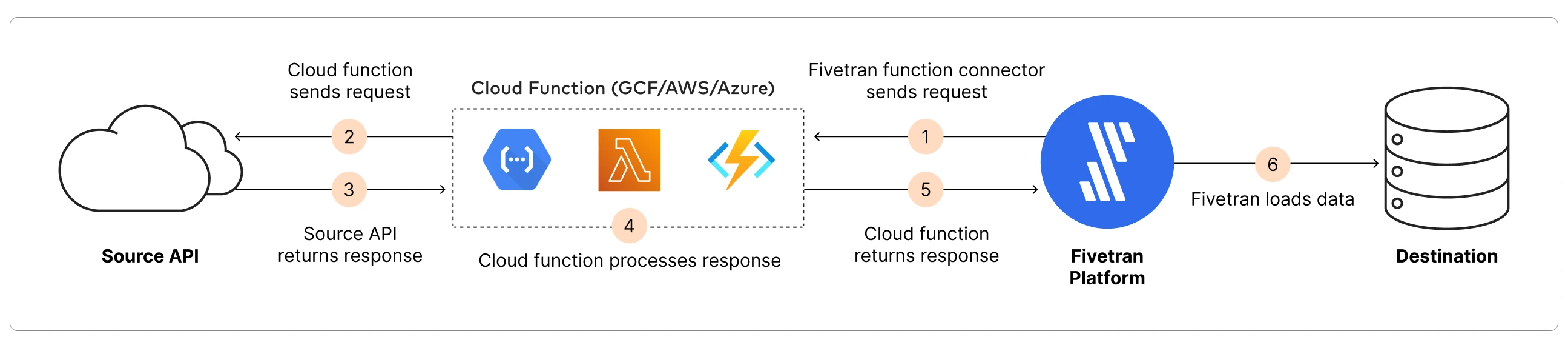
Sync overview
Authorize: Authorize Fivetran to the cloud service using the IAM role authorization mechanism.
Initial sync: Fivetran begins the initial sync of data by supplying an empty state (
{}). Your function responds with an initial set of data and a set of cursors.Parse: Fivetran parses the data returned by your function. The data must be in the standard response format.
Process: Fivetran creates a table in the destination for each entity. Fivetran typecasts and maps the elements in the entity to a column in the table. Fivetran also transforms data types that are not natively supported in the destination into data types that are supported by the destination.
Load: Fivetran automatically creates schemas (one per connection). Each mapped source object can translate to more than one normalized table. Fivetran creates the tables based on what you specify in the function’s response. Fivetran populates these tables with the initial dump of data.
Update: Fivetran periodically calls your function to pull the next set of data from it. Fivetran creates new tables if you add them in your function response.
Soft delete: Fivetran marks all the records of specified destination tables as deleted by setting the
_fivetran_deletedcolumn totrue. We recommend that you use this option only during full re-syncs of specified tables and not during incremental syncs.
Request format
Fivetran's request has a standard format. It is a JSON object with the following fields:
agentis an informational object.stateis a JSON object that contains cursors from the previous successful function execution. It is key to performing incremental updates. A cursor is a bookmark that marks the data Fivetran has already synced (for example, a timestamp, ID, or index). For the initial sync,stateis an empty JSON object{}. Fivetran expects an updatedstateobject in every response.The
stateobject can't be NULL. If you perform a full re-sync, thestateresets to{}. If there is an error during a full re-sync, Fivetran doesn't save intermediate data. To ensure data integrity, you must trigger the full re-sync again.secrets(optional) is a JSON object that contains access keys or API keys for the upstream APIs. Secrets allow you to store information (API tokens or database passwords) that you don’t want to check in to your code. We use encryption at rest to store the secrets. We pass the secrets into your function every time we call the function. Enter the secrets using a JSON format in the connection setup form.customPayload(optional) is a JSON object as a set of key-value pairs that can be used to specify custom information. We pass the custom payloads into your function every time we call the function.setup_test(optional) is a boolean that lets the function know that Fivetran has invoked the function for the setup tests. The function runs a lightweight job to test the connectivity and returns a JSON object with thehasMorefield set tofalse.We don't add this field to the request during syncs.
sync_id(optional) is the Fivetran sync identifier (UUID). You can find thesync_idin your connection's dashboard logs and use it to debug and link function logs with connection logs.When the
setup_testfield is set totrue, we add thesetup-testvalue to thesync_idfield in the request. We call the function once with thesync_id, and if we get an error, we then call the function without thesync_id.
Example request
{
"agent" : "<function_connector_name>/<external_id>/<schema>",
"state": {
"cursor": "2018-01-01T00:00:00Z"
},
"secrets": {
"apiToken": "abcdefghijklmnopqrstuvwxyz_0123456789"
},
"sync_id": "468b681-c376-4117-bbc0-25d8ae02ace1"
}
In this example,
function_connector_nameis the connection name. It can be one of the following:- Fivetran AWS Lambda Connector
- Fivetran Azure Functions Connector
- Fivetran Google Cloud Functions Connector
external_idis the unique ID tied to your connection. You can find the ID in your connection setup form.schemais the destination schema name you enter when you first set up your connection.
Response format
The response is a JSON object with the following root fields:
statecontains the updated state value(s). Your response must always return an updatedstateto checkpoint the data fetched in the request.insertspecifies the entities and records to be inserted. Fivetran reads the data and infers the data type and the number of columns.delete(optional) specifies the entities and records to be deleted. Use this field to mark records as deleted. Fivetran doesn't delete the record; instead it marks the record as deleted by setting_fivetran_deletedcolumn value totrue. If you specify the delete field, you must also specify the schema field.Fivetran creates the
_fivetran_deletedcolumn in the destination table, only if your function response has thedeletefield.schema(optional) specifies primary key columns for each entity. You must be very consistent with theschemafield and the primary key columns to avoid any unwanted behavior. If you don’t specify the schema, Fivetran appends the data.hasMoreis a boolean indicator for Fivetran to make a follow-up call to fetch the next set of data. Fivetran will keep making calls whilehasMore = trueuntil it receiveshasMore = false. In either case, your response should return an updated state to checkpoint the data fetched in that request and avoid an infinite loop.Fivetran terminates the connection if we detect more than 10 consecutive empty responses from the function.
softDelete(optional) specifies the list of entities to be soft deleted. Fivetran marks the records of these entities as deleted by setting the value of the_fivetran_deletedcolumn totrue. We recommend that you use this field if you do not want to specify the individual records to be deleted in thedeletefield. If a table is specified in bothdeleteandsoftDelete, the delete section will have no effect. ThesoftDeleteparameter must be included in the function response payload even if your data is being ingested through S3 Files.
Example response
{
"state": {
"transaction": "2018-01-02T00:00:00Z",
"campaign": "2018-01-02T00:00:01Z"
},
"insert": {
"transaction": [
{"id":1, "amount": 100},
{"id":2, "amount": 50}
],
"campaign": [
{"id":101, "name": "Christmas"},
{"id":102, "name": "New Year"}
]
},
"delete": {
"transaction": [
{"id":3},
{"id":4}
],
"campaign": [
{"id":103},
{"id":104}
]
},
"schema" : {
"transaction": {
"primary_key": ["id"]
},
"campaign": {
"primary_key": ["id"]
}
},
"hasMore" : true,
"softDelete":["transaction"]
}
In this example,
statecontains thetransactionandcampaigncursorstransactionandcampaignare entities. Fivetran creates two tables:TRANSACTIONwith columnsidandamountCAMPAIGNwith columnsidandname
The function inserts:
- records
1and2into theTRANSACTIONtable - records
101and102into theCAMPAIGNtable
- records
The function marks:
- records
3and4as deleted from theTRANSACTIONtable - records
103and104as deleted from theCAMPAIGNtable
- records
hasMoreis set totrueto indicate that there are more records. Fivetran immediately makes a following call to fetch the next set of values.softDeletemarks all the records of theTRANSACTIONtable as deleted by setting the value of its_fivetran_deletedcolumn totrue
Idempotence
Fivetran expects the cloud function you write will be idempotent: repeated calls with the same state return (roughly) the same data. An idempotent function doesn't track state internally. If an update fails at any point, Fivetran will repeat the function execution with the previous state. Fivetran will only save the new state returned by the function after the destination is successfully updated.
Custom error handling
Cloud functions may fail due to various reasons, including code execution errors, runtime issues, or internal errors. You can add an error handling mechanism in your function response to report an error on your Fivetran dashboard.
Design your function to report an error:
Use the
errorMessagefield in your response to indicate function execution errors. Fivetran creates an Error in the connection dashboard with your custom error message. For example, for the following response, Fivetran creates aThis is an errorerror in your dashboard:{ "errorMessage": "This is an error" }Use the optional
errorTypeandstackTracefields to pass additional information about the error. You must specify theerrorMessagefield to use theerrorTypeandstackTracefields. You can use a String value for theerrorTypefield.For example, for the following response, Fivetran creates an Error on your connection dashboard with the error type and stack trace details:
{ "errorMessage": "name 'response' is not defined", "errorType": "NameError", "stackTrace": [ [ "/var/task/sample_function.py", 35, "function_handler", "response['errorMessage'] = \"This is an error\"" ] ] }- Use a success or an error response as the
responsefield value:- Success response containing data operations (for example,
insertordelete). - Error response (containing the
errorMessage). If you includeerrorMessagein your response, the function displays that error and ignores any data operations you've specified.
- Success response containing data operations (for example,
- Use a success or an error response as the
Schema information
Fivetran creates a schema for the Function connection. You can customize your schema name when you first set up your connection. All tables for this connection are created in this schema. The destination schema name becomes your connection’s name and must be unique. For more information about the naming conventions, see our Naming conventions documentation.
You can only use lowercase letters (a-z), numbers (0-9), and underscores (_) to name your destination schema. Do not begin names with a number.
Additionally, Fivetran also creates _fivetran_batch and _fivetran_index columns:
_fivetran_batchis incremented every time Fivetran fetches data from the function. Its initial value is 0._fivetran_indexis the index at which a record is inserted for each batch.
Fivetran makes the _fivetran_batch and _fivetran_index columns as primary key columns if:
- your function doesn't specify the
schemaor - your function specifies a
schemabut doesn't specify theprimary_keyin theschema
- If your function doesn't specify a
primary_key, the data will be inserted as new rows to your destination and will count towards your Monthly Active Rows (MAR). Otherwise, Fivetran will use the specifiedprimary_keyto perform a merge and update the data in your destination. - Each function connection loads data into a unique schema to ensure one connection never accidentally overwrites data from another. You can use one function connection to load data into multiple tables within one schema.
Schema definition and data types
Your cloud function defines the destination schema, and Fivetran is not responsible for maintaining the schema. You must ensure that your cloud function consistently delivers data to the destination schema in the same format.
Fivetran supports a standard list of data types for all our destinations. We select an appropriate data type for the data stored in that column before writing to your destination. For more information about data types and type inference, see our Data types documentation.
Naming conventions
We follow our standard schema naming conventions.
Syncing empty tables and columns
Function connections don't support the creation of empty tables and columns in your destination.
Connection state management
You can manage the state of your function connection by using our API endpoints:
Sample functions
See the Fivetran Cloud Functions GitHub repo for sample functions you can use to build your own cloud functions. In the GitHub repo, we have included sample functions to fetch data from the following data sources:
Transport API - Download zip file
You can download our sample Transport - API (London Tube) function. Use your cloud platform's zip deployment feature to deploy the pre-built function and retrieve London Tube data to your Fivetran destination.
Select your language to download the sample function (.zip file):
Custom development service
If you need assistance with developing a customized function connection, our Services team may be able to help. Contact your Account Representative for more information.