Core Concepts
The building blocks of data organization are tables and schemas. Schema defines how tables consisting of rows and columns are linked to each other by primary and foreign keys. Each Fivetran connector creates and manages its own schema.
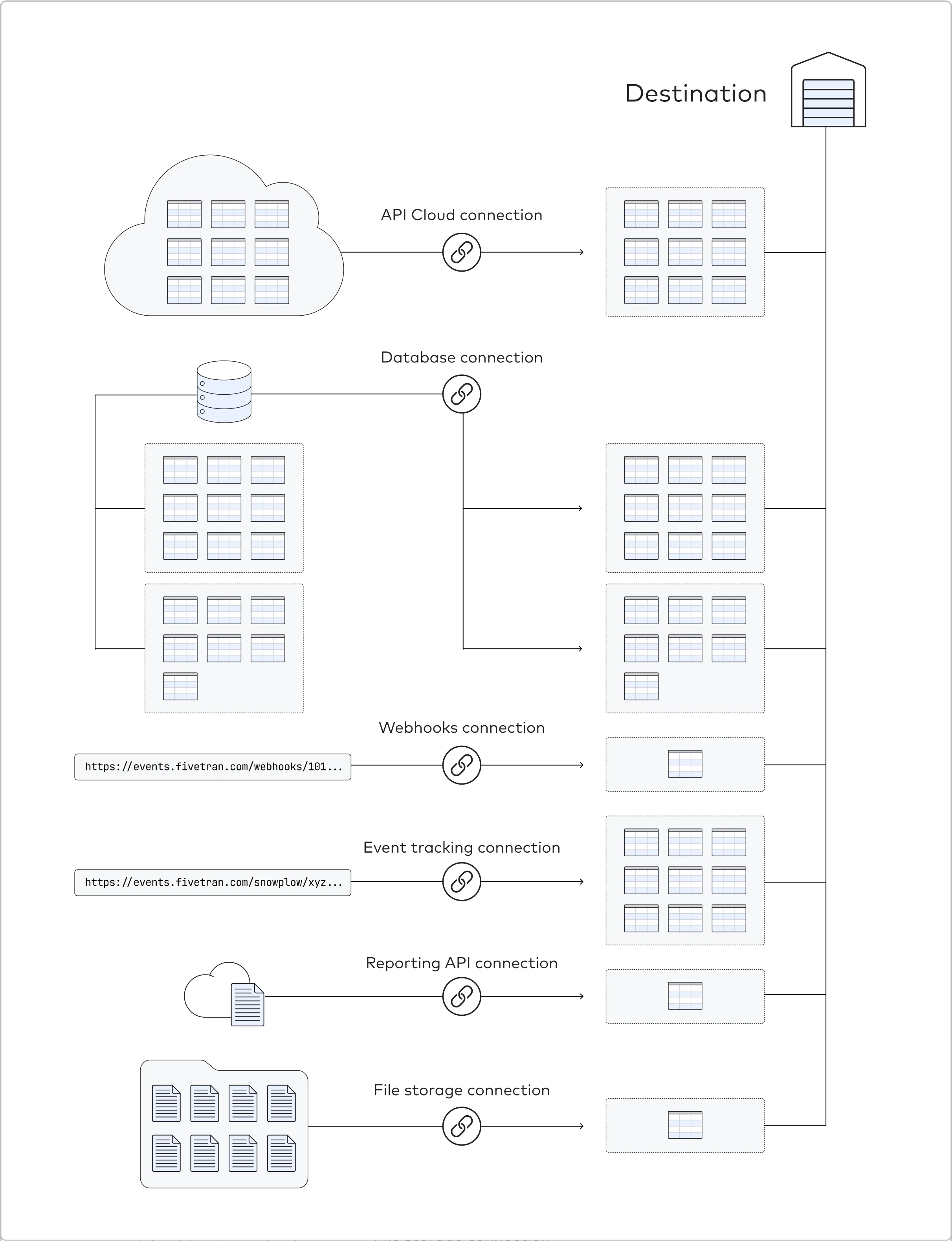
In simple terms, a Fivetran connector reaches out to your source, receives data from it, and writes it to your destination.
Depending on the type of connector, Fivetran either collects data that the source pushes to us or sends a request to the source and then grabs the data that the source sends in response.
The following diagram displays a single connector of each of our supported connector types.
ETL vs. ELT
In an ideal world, data analysts have access to all their required data without concern for where it's stored or how it's processed - analytics just works.
Until recently, the reality of analytics has been much more complicated. Expensive data storage and underpowered data warehouses meant that accessing data involved building and maintaining fragile ETL (Extract, Transform, Load) pipelines that pre-aggregated and filtered data down to a consumable size. ETL software vendors competed on how customizable, and therefore specialized, their data pipelines were.
Technological advances now bring us closer to the analysts' ideal. Practically free cloud data storage and dramatically more powerful modern columnar cloud data warehouses make fragile ETL pipelines a relic of the past. Modern data architecture is ELT-extract and load the raw data into the destination, then transform it post-load. This difference has many benefits, including increased versatility and usability. Read our blog post, The Modern Data Pipeline, to learn more about the difference between ETL and ELT.
Shared responsibility model
Data transformation and modeling is a shared responsibility between Fivetran and you, the customer. This shared model relieves you of much of the data integration burden because Fivetran
- designs, builds, operates, and maintains the extract and load from the source system to the destination schema; and
- orchestrates the transformation, modeling, and validation within the destination.
In designing a Fivetran schema, we do not try to provide an immediate answer to a specific customer's question. Instead, our goal is to provide a correct, easy-to-query schema that all of our customers can use to answer their own questions.
Fivetran’s responsibility
It is Fivetran’s responsibility to deliver up-to-date, accurate information in a cleaned and normalized schema - the canonical schema - at the lowest level of aggregation. It is our responsibility to regularly maintain the connector and evolve the canonical schema to reflect operational and product changes in the source systems. It is our responsibility to respond to any unknown operational breaking change in the extract and load from the source system to the destination schema.
Customer’s responsibility
It is your responsibility to write SQL queries that transform and model the data we deliver into a format that's suited to your particular needs. It is your responsibility to regularly maintain the transformation and modeling as the canonical schema evolves. It is your responsibility to respond to a known operational breaking change and follow the instructions to restore service.
Exceptions
In the cases we provide templates, like our dbt Core-compatible data models, we make sure that these templates are correct. However, you are responsible for adapting them to your needs.
Data types
Fivetran supports a standard list of data types for all our destinations. Fivetran analyzes the source data to check whether the connector has specified the data type for a column. We select an appropriate data type for the data stored in that column before writing to your destination.
Our connectors generate both explicitly- and implicitly-typed columns:
- Explicit data types are specified by the source. If the connector specifies the column data type, we don't infer the data. For example, Salesforce specifies an explicit data type for every field, which becomes a column in the destination.
- Implicit data types are inferred by Fivetran. If the connector doesn't specify the column data type, we try to infer the data type. For example, CSV files have no explicit types, so we have to analyze the data to infer the data type.
We use our data type hierarchy to automatically assign the most appropriate data type. We compute the data subtype and supertype using our hierarchy. We also use our hierarchy to find the optimal data type to write the data to your destination.
Depending on the destination, we may need to transform a source data type to a supported destination data type. You can find more information about these transformations on Fivetran's destination pages. For example, if your source database specifies a column data type as JSON, but your destination doesn't have a native JSON type, we change the column’s data type from JSON to STRING so that we can create the column in the destination.
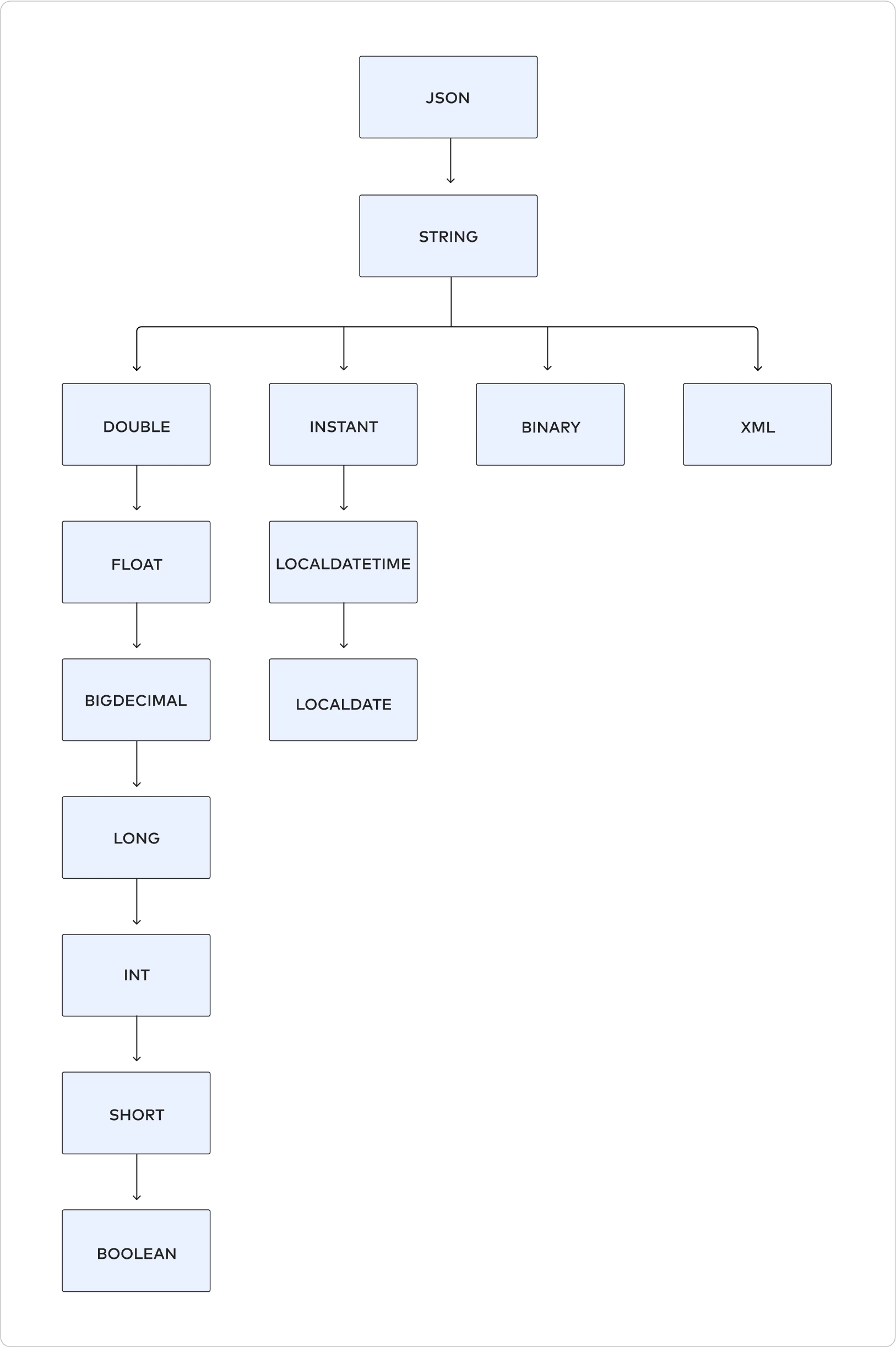
Data type hierarchy
Fivetran has a defined subtype-supertype relationship among the data types. In our hierarchy, JSON and STRING are the largest data types. The data type hierarchy is universal across all the destinations we support.
The following image illustrates Fivetran’s data type hierarchy.
Automatic data types assignment
Fivetran automatically assigns a data type when the source doesn't specify the data type. We try to use the smallest data type that can correctly store and represent your data. Smaller data types are usually faster because they use less space on the disk and in memory and because they require fewer CPU cycles to process. We try to use the simplest data type because operations on simpler data types are comparatively faster. For example, INT is easier to compare than STRING.
We use type inference and subtyping to find the optimal data type that we can use.
Type inference
We infer the data type by looking at each value and inferring the most specific type that can hold that value. We use the following inference logic:
If it is not a STRING value, we inspect the type of value. For example, if we see the value 1, we know it is not a STRING and will infer the data type is INT.
If it is a STRING value, then we try to infer the most suitable type. For example, if we see the value '9' in a CSV file, the most specific type that can hold that value is INT. If we see only values 't' or 'f' in a CSV file, the data type that can hold those values is BOOLEAN, so we infer the column as BOOLEAN.
The key principle behind using type inference is reversibility. For example, the STRING '9' can be coerced to the INT 9, then back to STRING, and we will get the original value, '9'.
We make a few exceptions to the reversibility principle to infer the precise data types. For example, we will infer the data type of '9.90' to be DOUBLE, even though the coercion of '9.90' that results in 9.9 is not reversible.
After inferring the data type for a value, we combine all the inferred data types according to our type hierarchy to find the optimal column data type. Consider the following example:
For a
countcolumn, we receive the value 9, and we infer the data type is INT.We receive another value for the same
countcolumn, 10.0, and we infer the data type is DOUBLE.The supertype between INT and DOUBLE is DOUBLE. The final inferred data type of the
countcolumn is DOUBLE.
Subtype and supertype
We use our data type hierarchy to identify subtypes and supertypes.
With subtyping, we try to minimize the type that we choose while still preserving the data’s integrity from the source. For example, SHORT is a subtype of INT because every SHORT is also an INT. We use subtyping to use the smallest possible data type to store the data. Each data type has a specific disk size. We transform the data type if the transformation does not result in a loss of precision. It lets us use less disk space to store the data in the destination.
If the column's data type (specified by the connector or inferred by us) is different from the one in the destination, we use supertyping to find the appropriate column data type to write to the destination.
Writing data types
Fivetran optimizes the data making it ready to be written to the destination:
- We compare the column's data type (explicit or inferred) with the one in the destination.
- Combine the data type with the type in the destination according to our type hierarchy.
- Merge the new data with the existing data in the destination.
Consider the following examples:
Explicit data type
A connector specifies the
countcolumn as INT. We write the data to the destination as INT.You change the data type of the
countcolumn in your source database to DOUBLE. In the next sync, the connector specifies thecountcolumn as DOUBLE.The supertype between INT and DOUBLE is DOUBLE. The optimal data type of the
countcolumn is DOUBLE.We write the
countcolumn as DOUBLE in the destination.
Implicit data type
From a CSV file, we inferred the final data type for the
countcolumn is DOUBLE.In the destination, the column
countis stored as STRING.The supertype between DOUBLE and STRING is STRING. The optimal data type of the
countcolumn is STRING.We write the
countcolumn as STRING in the destination.
Transformations and mapping
Our philosophy is to make a faithful replication of source data with as few transformations as necessary to make it useful. Fivetran automatically maps internal source types to supported destination types.
There are a few types of transformations that Fivetran performs automatically before loading the data. The first type of transformation is a minimal data cleaning.
- Transform data types that are not supported in the target destination.
- Perform a small amount of data manipulation and cleaning to put it in an optimal format to work within your destination. These textbook transformations are generally very generic and are beneficial for all of our customers.
- Perform a few schema transformations. Depending on how structured and well formatted the source data or API endpoints are, Fivetran performs some normalizing and cleaning of the schema. Schema transformations happen on a connector by connector basis. For further information relating to a particular connector, check the schema section of its documentation page.
Fivetran does not support advanced or user-definable in-flight transformations before we load your data, except for the row filtering feature, which is supported as an in-flight transformation. We do support custom push-down transformations in the destination after your data is loaded.
Because transformations happen post-load in the destination, your raw data is always available along with the transformed data. Read the Fivetran Transformations documentation to learn more about transformations in the destination.
Fivetran initially converts source timestamps to UTC and then loads them into your destination as UTC. However, if a source timestamp does not contain time zone information, then we load it as a TIMESTAMP WITHOUT TIMEZONE type into your destination.
Naming conventions
You can customize your connection's schema name when you first set up your connection. Fivetran offers the following naming conventions to name your schemas, tables, and columns in the destination:
For more information, see our naming conventions documentation.
Changing data type
Fivetran automatically promotes the column type to the most specific data type that losslessly accepts both the old and new data.
If a column changes data types in the source, we create a new column with a temporary name, copy all the values into it and cast them as the most specific data type that losslessly accepts both the old and new data, drop the old column, and then rename the new column with the name of the dropped column.
For example, if you convert a DOUBLE column to a BOOLEAN column, Fivetran converts the column to STRING which losslessly represents both the numbers and the strings "true" and "false." Note that column order might change when we convert column data types.
We encourage customers to use VIEWs to enforce data type coercions.
JSON documents
Some sources, such as JSON files or MongoDB, are composed of JSON objects with unknown schemas. In these cases, Fivetran promotes first level fields to columns in your destination.
If the first level field is a simple data type, we map it to its own type. If it's a complex data type (arrays or JSON data) we map it to a JSON type without unpacking. We do not automatically unpack nested JSON objects to separate tables in the destination. Any nested JSON objects will be preserved as is in the destination, so you will be able to use JSON processing functions in the destination.
To unpack more than one layer of nested fields, you can do one of the following:
- Set up a transformation in your destination.
- Build a custom connector using the Connector SDK.
For example, the following JSON:
{
"street" : "Main St."
"city" : "New York"
"country" : "US"
"phone" : "(555) 123-5555"
"zip code" : 12345
"people" : ["John", "Jane", "Adam"]
"car" : {
"make" : "Honda",
"year" : 2014,
"type" : "AWD"
}
}
gets converted to the following table when we load into your destination:
| _id | street | city | country | phone | zip code | people | car |
|---|---|---|---|---|---|---|---|
| 1 | Main St. | New York | US | (555) 123-5555 | 12345 | ["John", "Jane", "Adam"] | {"make" : "Honda", "year" : 2014, "type" : "AWD"} |
Re-syncing connections
When we re-sync a connection, we invalidate its incremental sync cursors, and we re-fetch all the original records from the source.
A re-sync is exactly like an initial sync, except that rather than creating new rows or tables in the destination, we overwrite the existing rows in the tables. For the majority of data, this may seem wasteful because we overwrite the rows with the same contents they have in the destination. However, in cases where the continuity of incremental updates has broken, this is the only way to ensure that we don't miss any changed data (new, changed, or deleted rows).
Data checkpoints
Whenever we write data to files stored locally on the disk or in the cloud, it is encrypted.
During the sync, Fivetran checkpoints data. A checkpoint marks the point in the sync operation up to which data have been retrieved, and written to the destination.
If your incremental sync fails, then Fivetran restarts the next sync from the last checkpoint, and not from point where the last successful sync left off. If your historical sync fails, then Fivetran restarts the next sync from the last checkpoint, not from the historical data start.
All Fivetran connectors use checkpoints. The checkpoint specifics vary depending on the connector type and your source configuration.
Release phases
We release new features, connectors, and destinations in phases to ensure we provide our users with the highest-quality experience. Below, we have outlined the expected user experience for each phase.
| Phase | Definition |
|---|---|
| Private Preview | We release private preview versions of new features, connectors, or destinations to a small group of customers to verify functionality and address issues. Releases in the private preview phase are hidden from non-participating users. Private preview releases are likely to be missing some functionality, and known or unknown issues may surface. We cannot guarantee a quick resolution to these issues during the private preview phase. When a connector (excluding destinations) is in Private Preview, its Monthly Active Rows (MAR) are free. |
| Beta | We use beta releases to test functionality with a broader audience. Beta releases are available to any customer who wishes to use them. In beta, the functionality is complete, and the goal is to test more edge cases. We address issues as soon as possible according to our Support SLA. |
| Generally Available | We release features or connectors as generally available once we have validated their quality and are sure we’ve identified all major technical issues in the previous two phases. If problems arise, we respond and address them as soon as possible according to our Support SLA. If a feature depends on a third-party partner integration, the partner must make that dependency generally available before we can release our feature as generally available. |
| Sunset | We sunset a feature, connector, or destination once we have identified a better solution that requires a breaking change. We notify users at least 90 days in advance of a sunset. |
Lite connectors have different release phases.