How to Use Online Refresh to Correct Data Mismatches
Question
How can I use Online Refresh to correct data mismatches?
Environment
HVR 5
Answer
This refresh procedure is used for a specific table or tables that have data consistency problems.
Full Load for Small or Medium-Sized Tables
Open the Refresh dialog.
Select the source and target location(s).
Select the tables that need to be refreshed.
Select the level of parallelism for the tables.
Select the Online Refresh option and set it to Skip Previous Integrate. This is because we assume two integrate locations.
Select the Schedule box and choose a sensible name for the refresh task.
Click Schedule.
Suspend the integrate jobs. You can leave the capture jobs running.
(Optionally) Go to the Scheduler, select the refresh job that has just been created, and choose New Attribute.
Create a
retry_maxattribute and set this to the required value. 0 means no retry.Right-click the refresh job and click Start to run the job.
Selective Refresh for Large Tables
Open the Refresh dialog.
Select the source and target location(s).
Select the tables that need to be refreshed.
Select the applicable context that activates the Restrict /RefreshCondition.
Select the level of parallelism for the tables (only applicable if multiple tables are refreshed).
Select the Online Refresh option and set it to Only Resilience. This is because only a slice of the tables is being refreshed.
Select the Schedule box and choose a sensible name for the refresh task.
Click Schedule.
Suspend the integrate jobs. You can leave the capture jobs running.
(Optionally) Go to the Scheduler, select the refresh job that has just been created, and choose New Attribute. Create a
retry_maxattribute and set this to the desired value. 0 means no retry.Right-click the refresh job and click Start to run the job.
Refreshes that use Restrict /RefreshCondition almost always use Only Resilience. The only exception is when the /RefreshCondition will match /CaptureCondition or /Integrate Condition that prevents some datasets from being replicated. Selective refreshes to correct for missed data should always be done with Only Resilience.
For selective refreshes, to correct for missed updates, with conditions on, for example, last_update date; duplicates can occur after the refresh because the old row will still be in there. These duplicates need to be (hard) deleted manually.
Example of Restrict /RefreshCondition
The following is an example of Restrict /RefreshCondition based upon the creation_date and last_update_date columns, where creation_date stands for the date when the row was inserted and last_update_date stands for the last date when the row was updated.
Using creation_date is applicable when inserts are missed; using last_update_date is applicable when updates are missed. A context parameter is added /Context=<ctx_name>. This allows the creation of specific refresh tasks with different /RefreshCondition applied.
Example based on creation_date
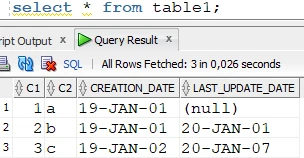
Source table:
Target table:
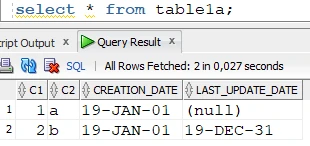
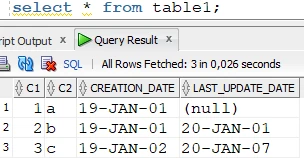
The row where
CREATION_DATE = 2019-01-02is missing from the target; therefore, we have to give this date as the condition of the refresh. The syntax of the condition depends on the source and target database. In this case, both the source and target databases are Oracle: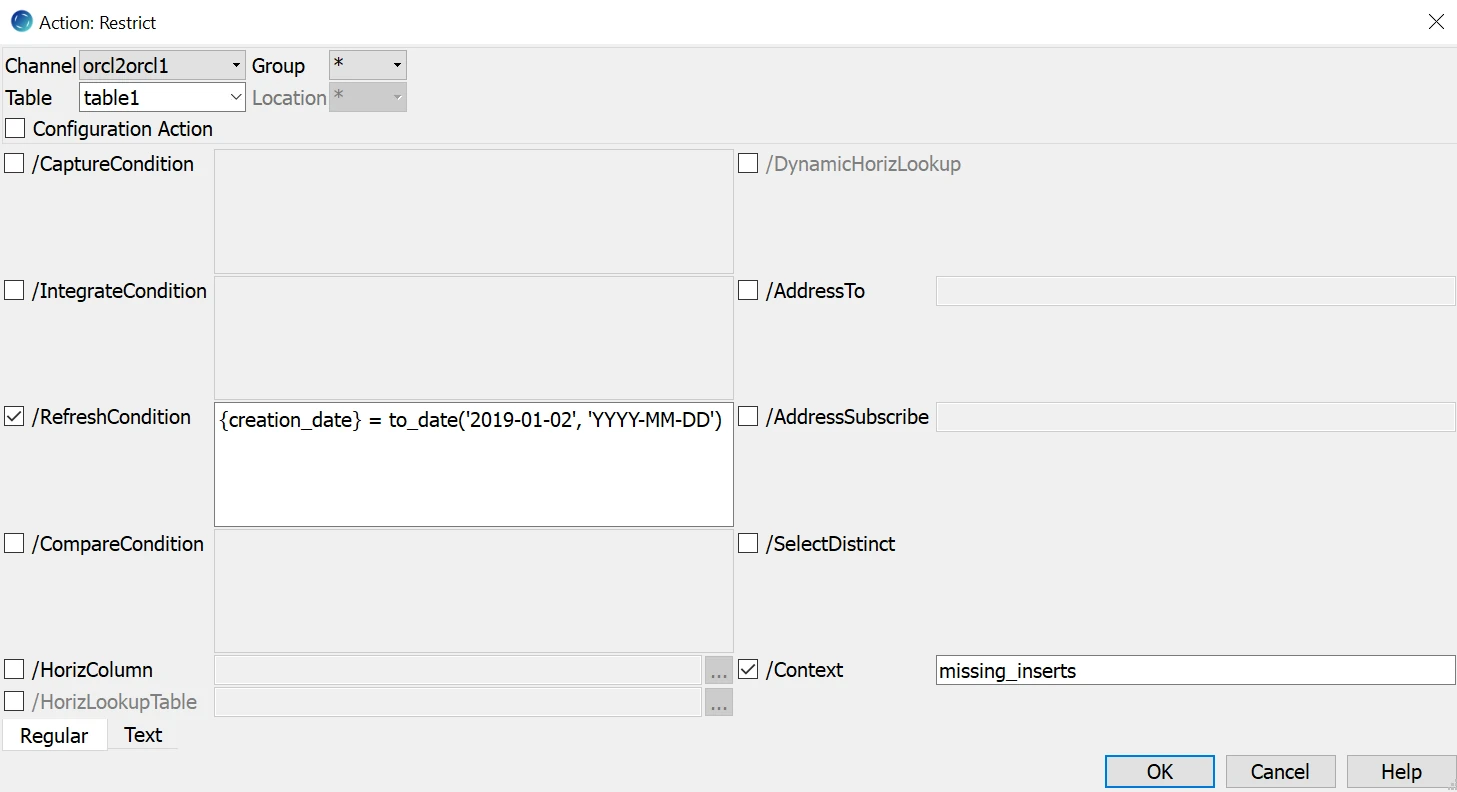
The condition has to be applied to both location groups (source and target); this way, the row(s) where
CREATION_DATE = 2019-01-02will be selected from the source table, and the rows whereCREATION_DATE <> 2019-01-02won’t be deleted from the target table.Schedule and start the refresh:
a. Open the HVR Refresh dialog and select Bulk Granularity and Only Resilience.
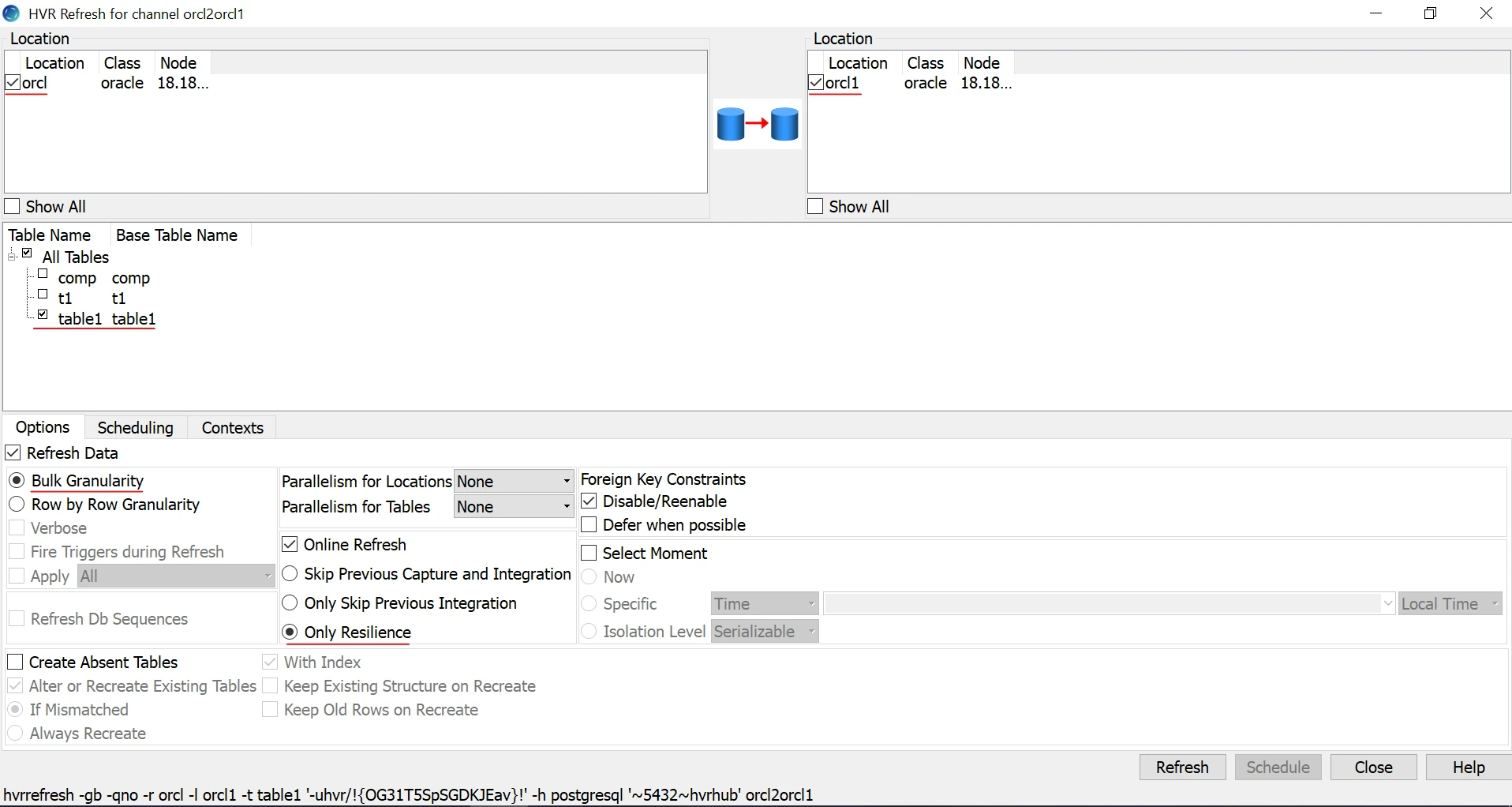
b. Click the Scheduling tab and select the Schedule Classic Job option. Specify the required Taskname.
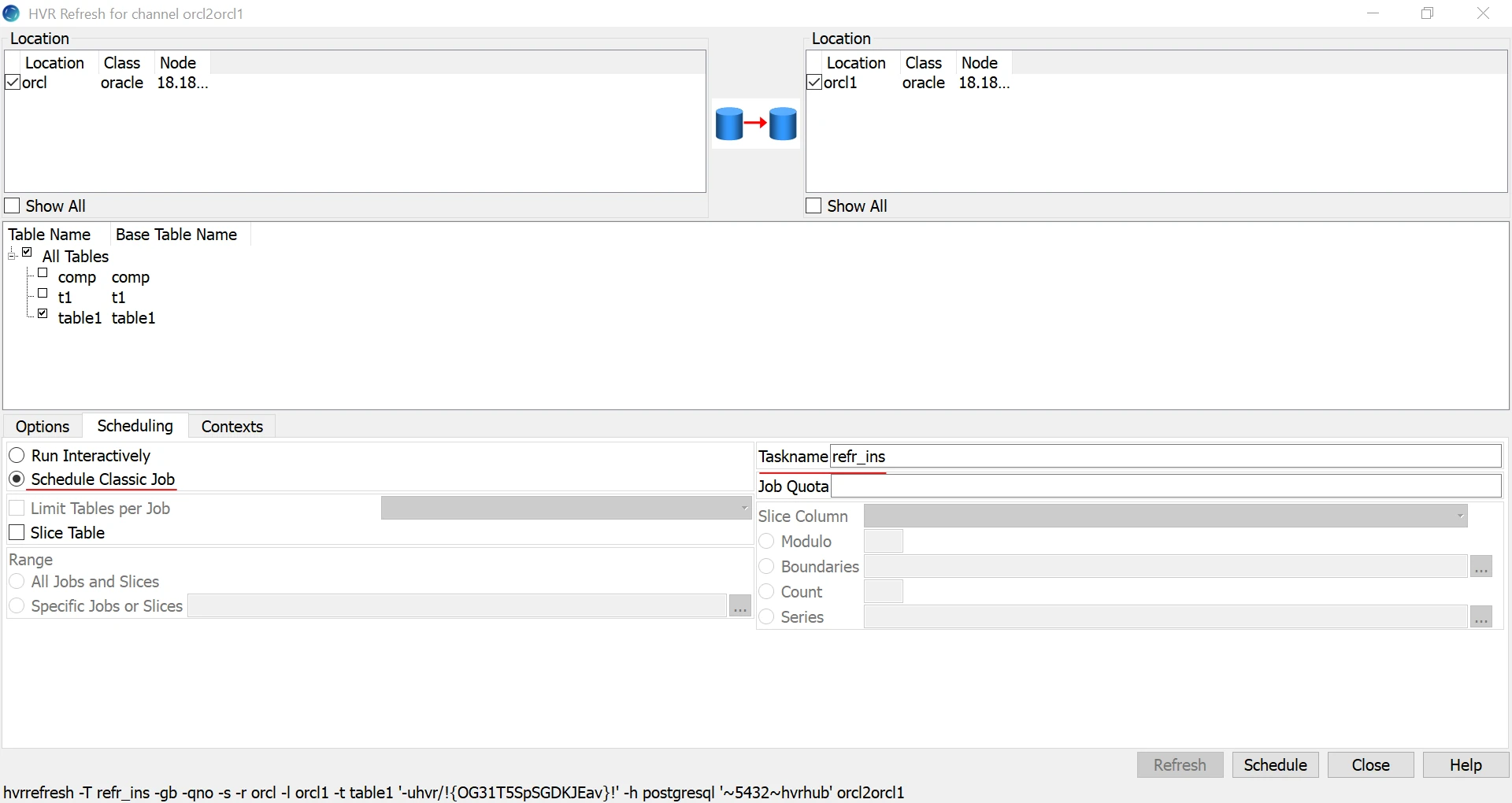
c. Click the Contexts tab and select the
missing_insertscontext and click the Schedule button.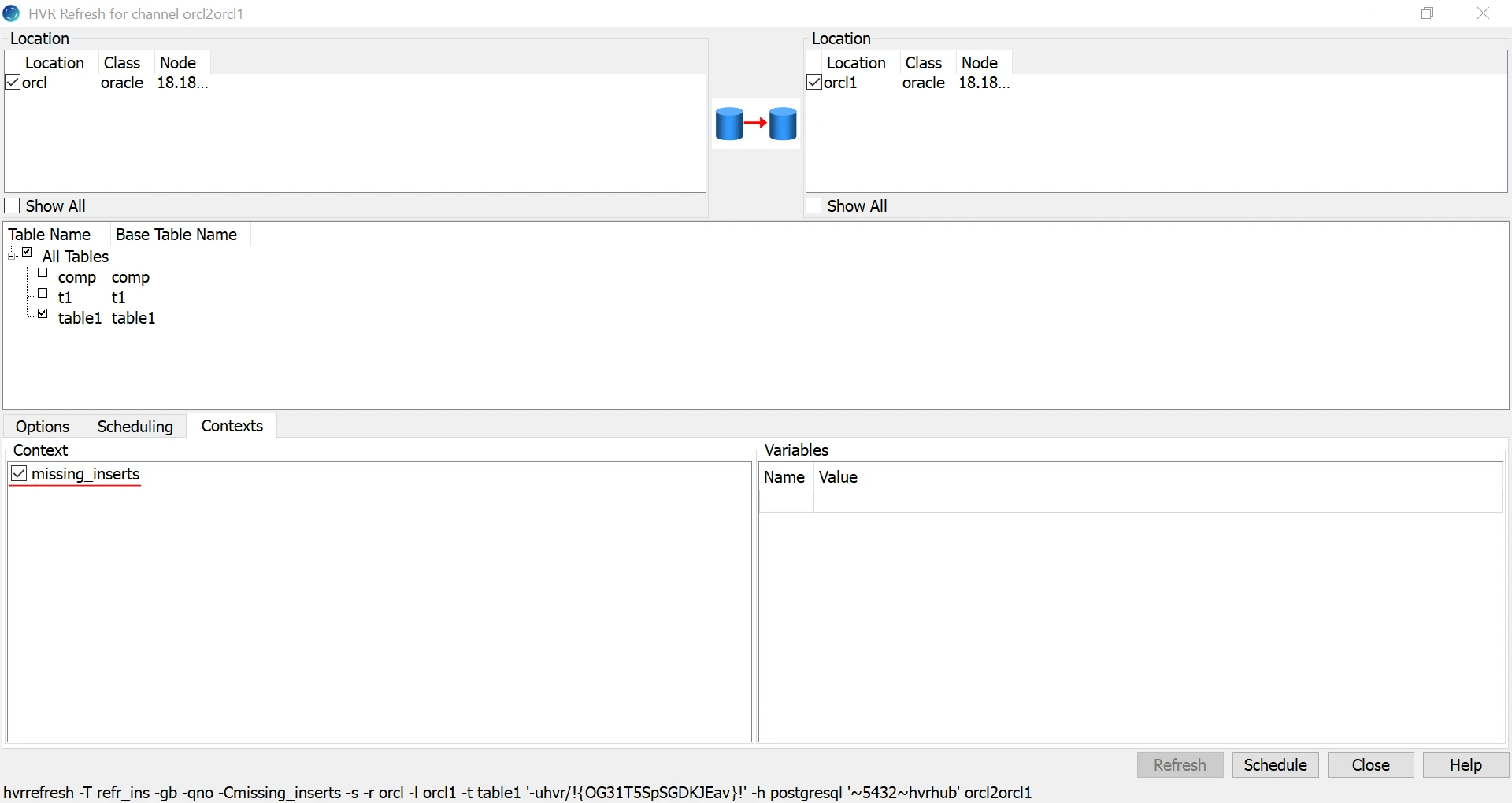
After scheduling the job, start it and wait until it is finished:

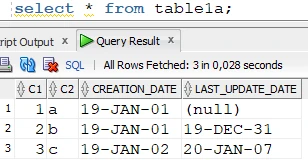
The target table after the refresh:
Source table:
Target table:
Example based on last_update_date
Source table:
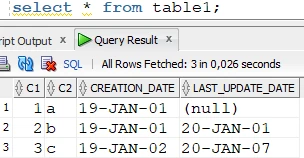
Target table:
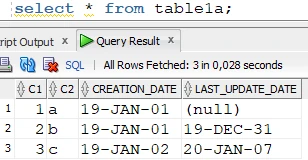
For some reason, an update was not replicated to the target table, which is visible from the difference in the last_update column of the row where C1 = 2.
To correct this, we have to do a refresh, but first, the differing row has to be deleted from the target. If we do not delete it and we create a condition based on the source table’s last_update_date column’s value, then the refresh job will not be able to locate the row in the target (since the target last_update_date value differs) and the target row where C1 = 2 will not be deleted before the row with the correct values is inserted. This is important especially if there are key/unique columns in the target, because this scenario will lead to a violation of the key/unique constraint.
Delete the different row from the target:

Source table:
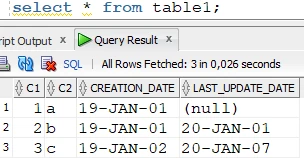
Target table:
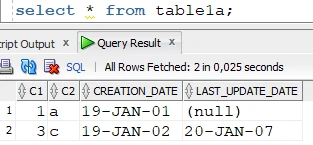
Create the refresh condition:
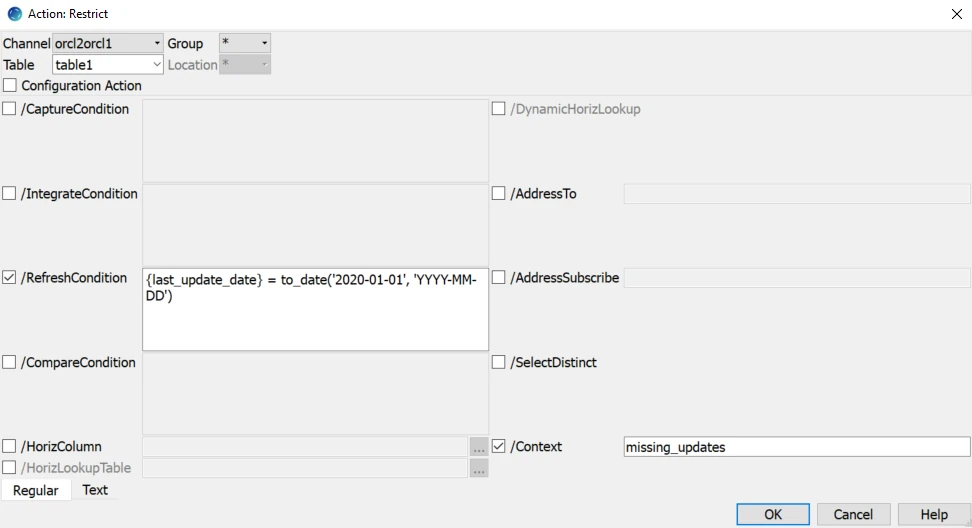
Schedule and start the refresh (the steps are detailed in the previous example’s second step).
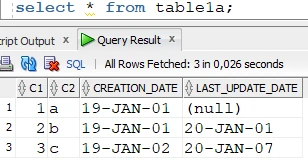
After the refresh is finished, the previously deleted row is inserted with the correct
last_update_datecolumn value:
Source table:
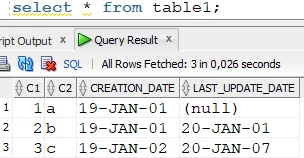
Target table:
On the source Restrict /RefreshCondition=”creation_date>to_date('15-MAR-18','dd-mon-yy') and creation_date<to_date('20-MAR-18','dd-mon-yy')” /Context=create_date
On the target Restrict /RefreshCondition=”creation_date > '2018-03-15' and creation_date < '2018-03-20' and hvr_is_deleted=0” /Context=create_date