Refreshing Data
The Refresh Data option allows you to load data selected from a source location to a target location. The source must be a database location, but the targets can be databases or file locations. For more information, see the Refresh concept page.
For consumption-based licensing, Fivetran offers a five-day troubleshooting window per table for performing free Refreshes in HVR. This window starts on the day you first perform a Refresh on a table in a given month. Any subsequent Refreshes done outside this window count towards paid MAR.
Refreshing from a source location is supported only on certain location types. For the list of supported source location types, see section Refresh and Compare in Capabilities.
Option Refresh Data is equivalent to the hvrrefresh CLI command.
This option to Refresh data is available on the following pages:
- Channel Details: the Refresh Data button at the top right of the page.
- Locations: the Refresh Data option under the More Options menu
 at the top right of the page.
at the top right of the page. - Location Details: the Refresh Data option under the More Options menu related to each channel in the Channel Membership pane.
- Tables: the Refresh Data option under the More Options menu at the top right of the page.
- Table Details: the Refresh Data option under the More Options menu at the top right of the page.
- Event Details: (related to a refresh event): the Repeat Refresh button at the to right of the page.
- Jobs: the New Refresh option under the More Options menu related to a refresh job.
The option to Refresh data may appear disabled in certain cases, for example, on the Channel Details page, if no locations are added to a channel. On the Tables page, you need to select one or more tables to enable the option, etc. When you hover over the disabled option, a tooltip will appear with an appropriate explanation.
The Refresh Data dialog allows you to choose specific locations and tables to be refreshed and configure different options to customize the refresh operation. For detailed information about each of the options available in the dialog, see section Refresh Options below.
Refresh Options
| Option | Description | |
|---|---|---|
| Locations | Locations section lists:
| |
| Tables | Tables section lists the table(s) that are to be refreshed. In the Command Line Interface, this option corresponds to hvrrefresh -t. | |
| No Initial Creation or Alter of Target Tables | Do not create any target new tables and keep the existing structure of the target tables (if any). | |
| Only Create Target Tables that are Missing | Create tables that are absent on a target location using the table definitions in a channel. In the Command Line Interface, this option corresponds to hvrrefresh -cbk. | |
| Create Missing Target Tables and Alter or Recreate Tables with Incorrect Layout | Create tables that are absent on a target location based on the table definitions in a channel, and alter or recreate tables if their layout does not match the table layout defined in a channel. In the Command Line Interface, this option corresponds to hvrrefresh -cbkr. | |
| Advanced Table Creation Options | This option is enabled only when Only Create Target Tables that are Missing or Create Missing Target Tables and Alter or Recreate Tables with Incorrect Layout is selected.  | |
| No Indexes | Do not create an index (unique key or non-unique index). When this option is not selected and if the original table does not have a unique key, then a non-unique index is created instead of a unique key. This option is available only when option Only Create Target Tables that are Missing or Create Missing Target Tables and Alter or Recreate Tables with Incorrect Layout is selected. In the Command Line Interface, this option corresponds to hvrrefresh -cbr. | |
| Recreate All Tables | Drop all target tables and create new ones based on the table layout in a channel. This option is available only when option Create Missing Target Tables and Alter or Recreate Tables with Incorrect Layout is selected. In the Command Line Interface, this option corresponds to hvrrefresh -cbfk. | |
| Keep Existing Structure | Keep the existing structure of all target tables. If a target table contains a column or index that is not included in the channel, HVR will not remove it. Also, columns that are too wide will not be shrunk. This option is available only when option Create Missing Target Tables and Alter or Recreate Tables with Incorrect Layout is selected. In the Command Line Interface, this option corresponds to hvrrefresh -cbekr. | |
| Keep Old Rows on Recreate | Preserve the existing data in a target table when recreating it. This option is available only when option Create Missing Target Tables and Alter or Recreate Tables with Incorrect Layout is selected. In the Command Line Interface, this option corresponds to hvrrefresh -cbkpr. | |
| Bulk Load - Table Granularity | Bulk Refresh means that the target object is truncated, and then the bulk copy is used to refresh the data from the read location. On certain locations, during Bulk Refresh table indexes and constraints will be temporarily dropped or disabled and will be reset after the refresh is complete. During Bulk Refresh, HVR typically streams data directly over the network into a bulk loading interface (e.g. direct path load in Oracle) of the target database. For DBMSs that do not support a bulk loading interface, HVR streams data into intermediate temporary staging files (in a staging directory) from where the data is loaded into the target database. For more information about staging files/directory, see section "Burst Integrate and Bulk Refresh" in the respective Source and Target Requirements. This option is commonly referred to as Bulk Refresh in this documentation. In the Command Line Interface, this option corresponds to hvrrefresh -gb. | |
Merge into Target (No Delete/Truncate on Target)Since v6.1.5/2 | Perform upsert refresh. This option merges the source rows into the target without initially deleting or truncating the target rows. Similar to Burst Integrate, the data is initially loaded into burst tables named tbl_ _rb and then the burst table is merged with the base table. Changes are applied as inserts or updates, similar to Resilient Integrate. Deletes or key updates are not covered by this type of refresh. Rows that are deleted on the source will still exist in the target. Rows for which the key has been updated in the source will exist with both the old and new key in the target. This option is only available for target locations that support the Burst integrate method. This option cannot be used for tables with a TimeKey column. In the Command Line Interface, this option corresponds to hvrrefresh -u. | |
Idempotent LoadSince v6.3.0/15, v6.3.5/5 | Perform idempotent load refresh. During a standard Bulk Refresh on BigQuery, Databricks, and Snowflake, HVR truncates the target table, stages the data, and then loads it. If the load step fails and HVR recovers, the load is retried against a target that may already contain partial data, resulting in duplicate rows. With this option, the step order changes: HVR first stages the data, then truncates the target table, and finally loads it. If the load step fails, HVR repeats the truncation before retrying, preventing duplicates. This option is only available for BigQuery, Databricks, and Snowflake targets. In the Command Line Interface, this option corresponds to hvrrefresh -k. | |
| Repair - Row by Row Granularity | Row-by-Row Refresh, also referred to as Row-wise Refresh, compares data on read and write locations and produces a 'diff' result based on which only rows that differ are updated on the write location, each row is refreshed individually. This results in a list of a minimal number of inserts, updates or deletes needed to re-synchronize the tables. For column-oriented databases (e.g., Redshift, Snowflake, Google BigQuery), Row-wise Refresh is best used on small amount of data, e.g., on tables with a small amount of changed data or on small tables. In other cases Row-wise Refresh on column-oriented databases takes a lot of time. In the Command Line Interface, this option corresponds to hvrrefresh -gr. | |
| Keep Difference Files | Verbose. This option creates binary diff files containing individual differences detected. Section Analyzing Diff File explains how to view and interpret the contents of a diff file. This option is only displayed for the Repair - Row by Row Granularity mode (not available when option Bulk Load - Table Granularity is selected). In the Command Line Interface, this option corresponds to hvrrefresh -v. | |
| Online refresh consistency when selecting tables which are being changed |  | |
| Select moment with Oracle flashback query | Select data from each table of the source from the same consistent moment in time. Options can be one of the following:
| |
| Online refresh controls to affect replication of changes that occurred before and during refresh | Online refresh of data from a database that is continuously being changed. This requires that capture is enabled on the source database. The integration jobs are automatically suspended while the online refresh is running, and restarted afterward. The target database is not yet consistent after the online refresh has finished. Instead, it leaves instructions so that when the replication jobs are restarted, they skip all changes that occurred before the refresh and perform special handling for changes that occurred during the refresh. This means that after the next replication cycle consistency is restored in the target database. If the target database had foreign key constraints, then these will also be restored. Available options are:
| |
| Contexts | This option controls whether actions defined with parameter Context are effective or are ignored. For more information, see the Refresh and Compare Contexts concept page. Defining an action with parameter Context can have different uses. For example, if action Restrict with parameters RefreshCondition="{id}>22" Context=qqq is defined, then normally all data will be refreshed, but if context qqq is enabled (-Cqqq), then only rows where id>22 will be refreshed. Variables can also be used in the restrict condition, such as "{id}>{hvr_var_min}". This means that hvrrefresh -Cqqq -Vmin=99 will only Refresh rows with id>99. Action ColumnProperties with parameter Context can also be defined. This can be used to define CaptureExpression parameters which are only activated if a certain context is supplied. For example, to define a Bulk Refresh context where SQL expressions are performed on the source database (which would slow down capture) instead of the target database (which would slow down Bulk Refresh). For more information, see the concept page - Refresh and Compare Contexts.This option is displayed only if either of the action (CollisionDetect, ColumnProperties, Environment, FileFormat, Integrate, Restrict, TableProperties, Transform) is defined with parameter Context. In the Command Line Interface, this option corresponds to hvrrefresh -C. | |
Variables | Supply value for refresh restrict condition or add a new variable. In the Command Line Interface, this option corresponds to hvrrefresh -V. | |
| Parallel Sessions | Perform refresh for different tables in parallel using the specified number of sessions (sub-processes). The refresh will start by processing that many tables in parallel; when the first of these is finished, the next table will be processed, and so on. In the Command Line Interface, this option corresponds to hvrrefresh -P. | |
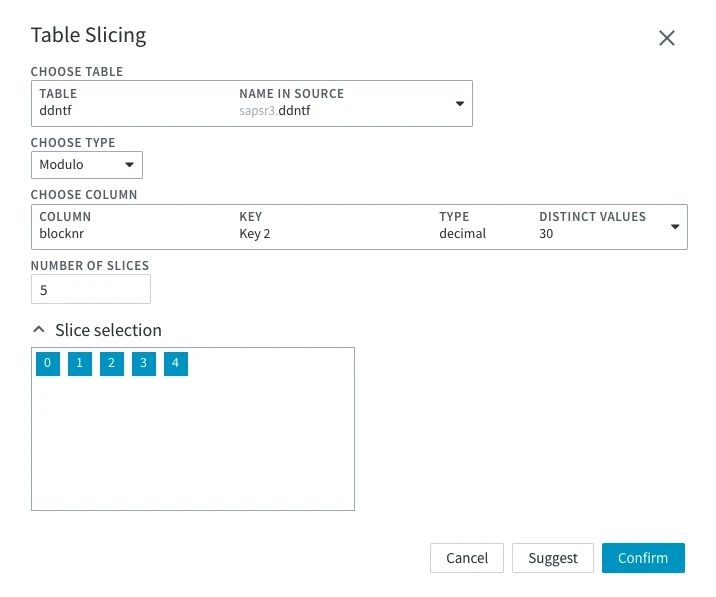
| Slicing | The slicing section allows you to configure the slicing options. For more information, see the Slicing concept page. Table Slicing dialog can be invoked by clicking the Add Table button. In this dialog, you can choose the slicing separately for each table in your source.
| |
Choose Table | Table for which the slicing is to be configured. | |
Choose Type | Types of slicing that can be applied to the table:
| |
Choose Column | The table will be sliced by the chosen column's data. Slicing on a non-key column can cause errors if an update moves a row between slices. The Distinct Values field is shown if dbms_stats gathering is enabled for the database. The Distinct Values column is only available for Oracle. This option is available when Modulo or Boundary slicing type is chosen. | |
Number of Slices | The number of slices the table will be divided into. | |
Boundaries | Set the boundaries for each slice. To set them, you have to know the data in your table. This option is available when the Boundary slicing type is chosen. | |
| Data Type | Choose the data type for slicing. To set it, you have to know the data in your table. This option is available when the Boundary slicing type is chosen. | |
| Series Values | Set values for each slice. To set them, you have to know the data in your table. This option is available when the Series slicing type is chosen. | |
Slice Selection | Choose which slices you want to perform the job on. For example, you have chosen Boundary slicing and have set the boundaries to 1000, 3500, and 6000. In this case, you will have 5 slices: with values 0 to 999, 1000 to 3499, 3500 to 5999, and 6000 to the end of the table. You can choose only the second and third slices so that the Refresh job is performed on rows with values 1000 to 5999. | |
Slicing Suggestions dialog can be invoked by:
In the Slicing Suggestions dialog, you can configure the slicing settings for the current job. 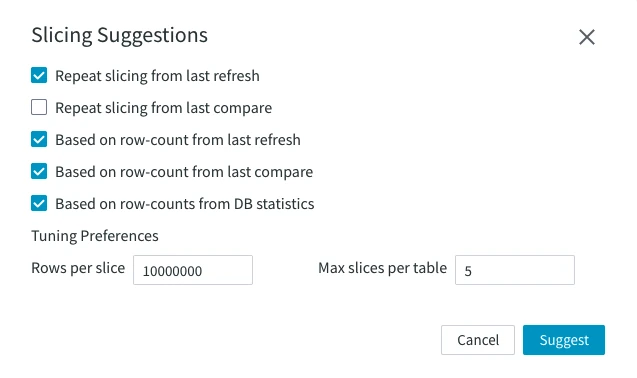 This option is not supported since 6.3.0/0. | ||
| Slicing Suggestions | Repeat a previous slicing job or base it upon certain data:
This option is not supported since 6.3.0/0. | |
| Tuning Preferences | Rows per slice – sets the number of rows per slice. Set to 10 million by default. Max slices per table – sets the maximum number of suggested slices per table. By default, the number is set to 5.This option is not supported since 6.3.0/0. | |
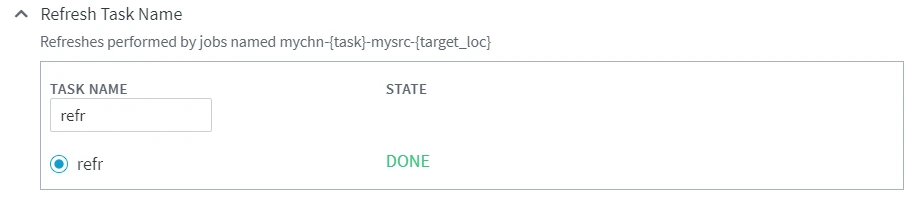
| Refresh Task Name |
Specify an alternative name for a refresh task to be used for naming scripts and jobs. The task name must begin with an 'r'. Thedefault task name is refr, so without this option, the Refresh jobs and scripts are named chn-refr-l1-l2. | |
| Isolate Tables During Refresh |
Enable table isolation during refresh. Isolated table refresh allows integrate jobs to continue for tables that are not part of the isolated refresh. The integrate jobs for the isolated tables will resume once the refresh is complete. You can specify when to start isolation:
| |
| Advanced Refresh Options |  | |
Only Repair Certain DifferencesSince v6.2.5/6 | Ignore certain types of differences during the refresh operation. When enabled, the selected difference types are not repaired in the target database. They are also excluded from SQL output generated by the Verbose mode. You can select one or more of the following options:
This option is only displayed for the row by row refresh mode (not available when option Table Checksums Only is selected). In the CLI, this option corresponds to the | |
| Foreign Key Constraints | Behavior for foreign key constraint in the target database which either reference or are referenced by a table which should be refreshed. Available option is:
If this option is unselected, the foreign key constraints are ignored. Normally this would cause foreign key constraint errors. This option is supported/available only for certain location types. By default, the foreign key constraints are ignored for the unsupported location types. For the list of supported location types, see Disable/enable constraints check during hvrrefresh and Disable/enable foreign keys during hvrrefresh (option -F) in Capabilities. | |
| Disable Triggers | Disable database triggers during integrate. This option is enabled only when Repair - Row by Row Granularity is selected. This option is supported only for certain location types. For the list of supported location types, see Disable/enable database triggers during integrate (NoTriggerFiring) in Capabilities. For Ingres, this parameter disables the firing of all database rules during integration. This is done by performing SQL statement set norules at connection startup. For SQL Server, this parameter disables the firing of database triggers, foreign key constraints and check constraints during integration if those objects were defined with not for replication. This is done by connecting to the database with the SQL Server Replication connection capability. A disadvantage of this connection type is that the database connection string must have form host,port instead of form \\host\instance. This port needs to be configured in the Network Configuration section of the SQL Server Configuration Manager. Another limitation is that encryption of the ODBC connection is not supported if this parameter is used for SQL Server. For Oracle and SQL Server, HVR will automatically disable triggers on target tables before the Refresh and re-enable them afterwards, unless option Online Refresh is defined. Other ways to control trigger firing are described in Managing Recapturing Using Session Names. In the Command Line Interface, this option corresponds to hvrrefresh -f. | |
Add a Truncate Record Before First RowsSince v6.1.5/2 | Add the timekey truncate record as the first record of each table that is refreshed from the source location. This implies all previous timekey records for this table can be ignored by the system or application that consumes the data in the target location. This option is only supported if the target is a file or Kafka location. This option can only be used for tables with a TimeKey column. In the Command Line Interface, this option corresponds to hvrrefresh -n. | |
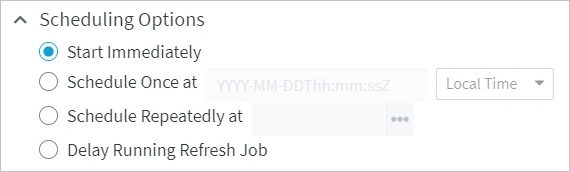
Scheduling Options |
Schedule the time to run the refresh job. Available options are:
| |
| Show Equivalent HVR Command Line | Show the CLI command equivalent to the UI options selected in the dialog. You can use (copy and paste) the equivalent line to manually repeat or perform this operation later on. In cases when the command line equivalents are different for Linux/Unix and Windows, both options are shown. Select option Include -R (Remote hub server) argument to include the parameters for accessing a hub server that runs on a remote machine. For more information about this CLI option, see hvrrefresh -R. | |

Viewing Refresh Results
Clicking the Refresh Data button in the Refresh Data dialog will start the refresh job. You will see the following notification at the top of the page.

Once the refresh job is started, the following notification will appear at the top of the page. Click the View Refresh event link to open the Event Details page displaying detailed information about the refresh event.

On the Channel Details page, the refresh job state is displayed on the Jobs pane. To open the Event Details, click the More Options icon ![]() of the refresh job and select Go To Event.
of the refresh job and select Go To Event.

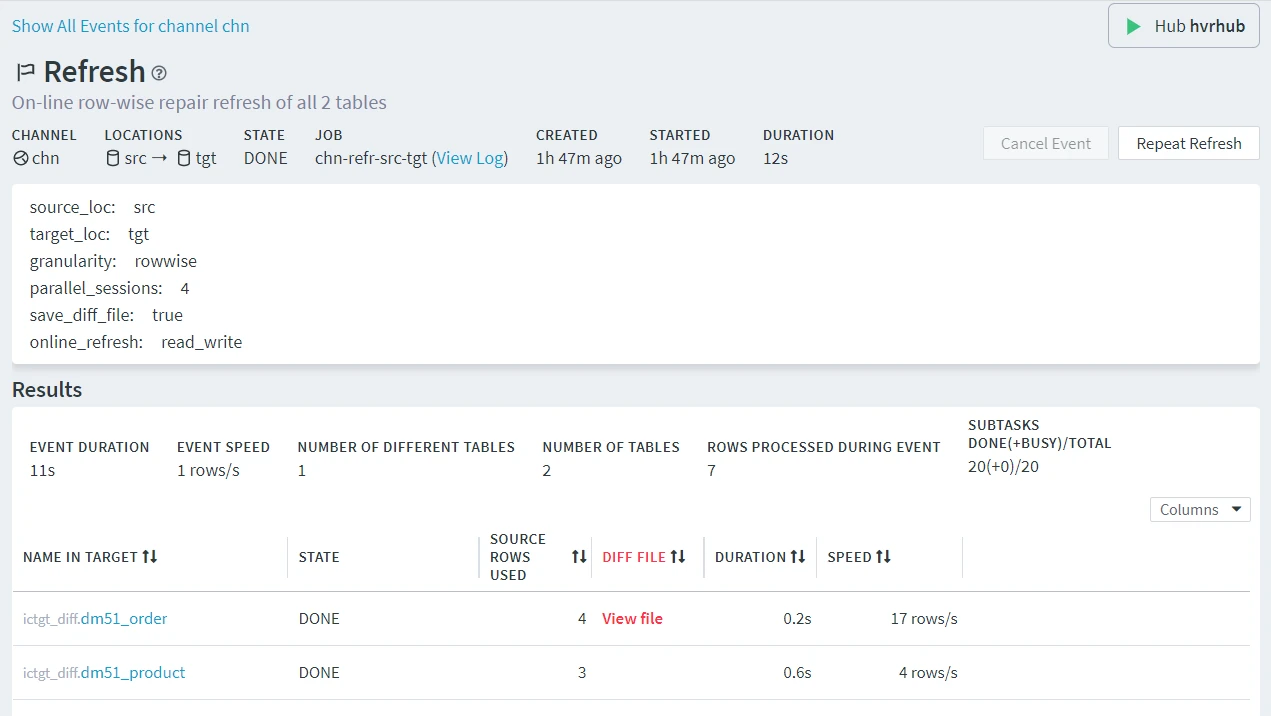
The image below displays a sample Event Details page showing the details of a refresh event.
- The top pane displays information about the channel and location(s), for which the refresh event was done, the event state, the job name associated with the event, and the start time of the event.
- The middle pane displays additional information related to the options configured in the Refresh Data dialog, such as granularity mode, online refresh options, and other.
- The Results pane displays the refresh statistics for each table involved in the refresh event. The View file link opens the View Diff File dialog that allows to inspect a diff file containing the list of differences detected. Section Analyzing Diff File explains how to view and interpret the contents of the diff file. For detailed description of each parameter in the Results pane, see section Refresh and Compare Results.