Integrate
Action Integrate instructs Fivetran HVR to integrate changes into a database table or file location. Various parameters are available to tune the integration functionality and performance.
If integration is done on file location in a channel with table information then any changes are integrated as records in either XML, CSV, AVRO, or Parquet format. For details, see action FileFormat.
Alternatively, a channel can contain only file locations and no table information. In this case, each file captured is treated as a 'blob' and is replicated to the integrate file locations without HVR recognizing its format. If such a 'blob' file channel is defined with only actions Capture and Integrate (no parameters) then all files in the capture location's directory (including files in sub-directories) are replicated to the integrate location's directory. The original files are not touched or deleted, and in the target directory, the original file names and sub-directories are preserved. New and changed files are replicated, but empty sub-directories and file deletions are not replicated.
If a channel is integrating changes into Salesforce, then the Salesforce 'API names' for tables and columns (case–sensitive) must match the 'base names' in the HVR channel. This can be done by defining action TableProperties with parameter BaseName on each of the tables and action ColumnProperties with parameter BaseName on each column.
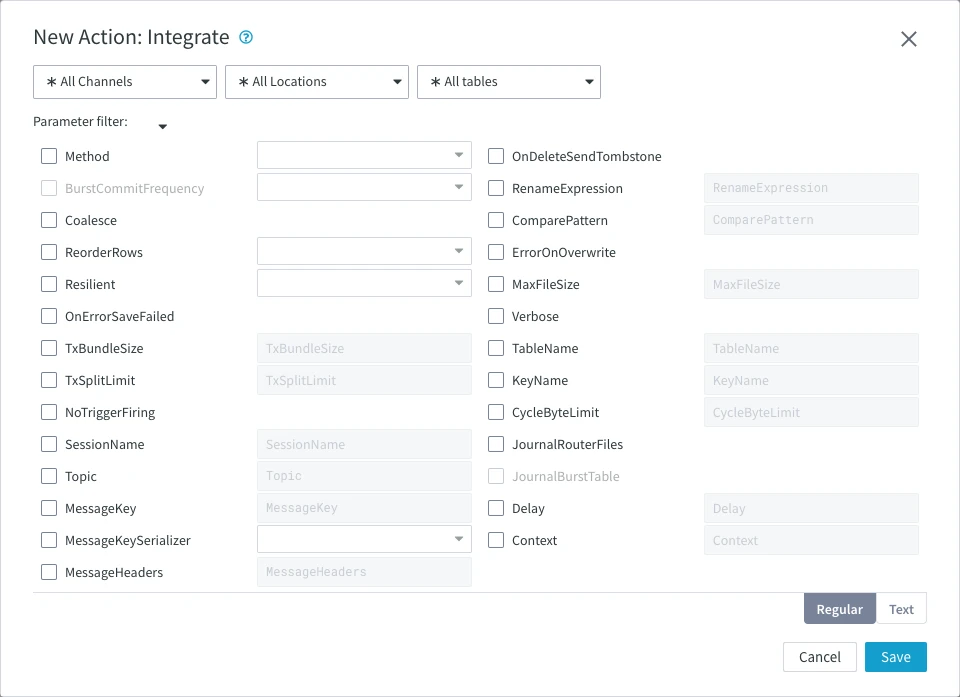
Parameters
This section describes the parameters available for action Integrate. By default, only the supported parameters for the selected location type(s) are displayed in the Integrate dialog.
Following are the two tabs/ways, which you can use for defining action parameters in this dialog:
- Regular: Allows you to define the required parameters by using the UI elements like checkbox and text field.
- Text: Allows you to define the required parameters by specifying them in the text field. You can also copy-paste the action definitions from HVR documentation, emails, or demo notes.
Method
Argument: method
Description: Method of writing or integrating changes into the target location.
Available options for method are:
BURST: Integrate changes into the target table using Burst algorithm.
Expand for more information
All changes for the cycle are first sorted and coalesced, so that only a single change remains for each row in the target table (see parameter Coalesce). These changes are then bulk loaded into 'burst tables' named tbl_ _b. Finally, a single set wise SQL statement is done for each operation type (
INSERT,UPDATE, andDELETE). The end result is the same as the CONTINUOUS integration but the order in which the changes are applied is completely different from the order in which they occurred on the capture machine. For example, all changes are done for one table before the next table. This is normally not visible to other users because the burst is done as a single transaction, unless parameter BurstCommitFrequency is used. If database triggers are defined on the target tables, then they will be fired in the wrong order.During BURST integrate, for some databases HVR 'streams' data into target databases straight over the network into a bulk loading interface specific for each DBMS (e.g. direct-path-load in Oracle) without storing the data on a disk. For other DBMSs, HVR puts data into a temporary directory ('staging file') before loading data into a target database.
This is the
defaultintegrate method for the following location types -- Actian Vector
- Aurora MySQL
- Aurora PostgreSQL
- Azure SQL Database
- Azure Synapse Analytics
- Azure SQL Managed Instance
- Google BigQuery
- Greenplum
- SAP HANA
- SingleStore
- Redshift
- Snowflake
- Teradata
If this method is defined for any table, then it affects all tables integrated to that location.
If this method is defined, deleting one row from a set of duplicates on the source leads to the deletion of the complete set of duplicate rows on the target.
This method is required for online analytical processing (OLAP) databases, such as Greenplum, Redshift, Snowflake, Teradata for better performance during integration.
This method cannot be used for file locations. A similar effect (reduce changes down to one per row) can be achieved by defining the parameter ReorderRows=SORT_COALESCE.
This method cannot be used if the channel contains tables with foreign key constraints.
This method cannot be used with action DbSequence.
This method cannot be used with action CollisionDetect.
This integrate method is commonly referred to as Burst Integrate in this documentation.
CONTINUOUS: Integrate changes into the target table continuously as and when a change is captured.
Expand for more information
Each change is applied as a separate
INSERT,UPDATE, andDELETESQL statement in the original captured order.This is the
defaultintegrate method for the following location types -- Apache Kafka
- Db2 for i
- Db2 for Linux, Unix and Windows
- Db2 for z/OS
- File, FTP, SFTP
- Ingres
- MariaDB
- MySQL
- Oracle
- PostgreSQL
- SAP NetWeaver
- SQL Server
- Sybase ASE
This integrate method is commonly referred to as Continuous Integrate in this documentation.
APPEND
Since v6.2.5/3: Append changes directly into a target with the TimeKey parameter defined.Expand for more information
The APPEND method enables the direct insertion of changes into target tables with the TimeKey parameter defined. During each cycle, changes are organized first by table and then by their sequence within each table. These organized changes are then bulk-loaded into the target tables, processing one table at a time.
Important Considerations:
This method is valid only if all tables in the target location have the TimeKey parameter defined.
The APPEND method is compatible exclusively with specific OLAP databases, namely Databricks, BigQuery, and Snowflake.
This method is not applicable for HANA sources.
This method cannot be used if there is an IntegrateExpression that requires evaluation within the target database.
If the integrate method is changed to BURST and replication is re-activated while Integrate is actively processing data, the first BURST cycle after the change may re-insert changes that are already present in the target, potentially causing duplicate entries.
BurstCommitFrequency
Argument: freq
Description: Frequency for committing burst set wise SQL statements.
Available options for freq are:
CYCLE
default: All changes for the integrate job cycle are committed in a single transaction. If this parameter is defined for any table then it affects all tables integrated to that location.TABLE: All changes for a table (the set wise
INSERT,UPDATE, andDELETEstatements) are committed in a single transaction.STATEMENT: A commit is done after each set wise SQL statement.
Coalesce
Description: Causes coalescing of multiple operations on the same row into a single operation. For example, an insert and an update can be replaced by a single insert; five updates can be replaced by one update, or an insert and a delete of a row can be filtered out altogether. The disadvantage of not replicating these intermediate values is that some consistency constraints may be violated on the target database.
The Burst Integrate performs a sequence of operations including coalescing. Therefore, this parameter should not be used when parameter Method is set to BURST.
CoalesceTimekey
Since v6.2.5/9
Description: Enables coalescing on TimeKey channels when writing to a database target. Multiple operations on the same row within a single integrate cycle are merged into a single operation.
This parameter is available only when the Method parameter is set to BURST. It only applies to database targets and is ignored for file targets.
ReorderRows
Argument: mode
Description: Specifies the order in which changes are written to files.
This parameter is only supported for file-based target locations.
Expand for more information
If the target file-name depends on the table name (for example parameter RenameExpression contains substitution {hvr_tbl_name}) and if the change-stream fluctuates between changes for different tables; then keeping the original order will cause HVR to create lots of small files (a few rows in a file for tab1, then a row for tab2, then another file for tab1 again). This is because HVR does not reopen files after it has closed them. Reordering rows during integration will avoid these 'micro-files'.
Available options for mode are:
NONE (
defaultif parameter RenameExpression does not contain a substitution which depends on the table name, which is common for XML format): Write all rows in their original order, even if it means creating micro-files per table.BATCH_BY_TABLE (
defaultif parameter RenameExpression does contain a substitution which depends on the table name, as is common for CSV and AVRO format): Reorder interleaved rows of different tables in batches, with best effort. This mode both prevents micro-files and avoids a full-sort, so performance is good and resource usage is minimal. If there is lots of data then multiple (larger) files can be created for a single table.ORDER_BY_TABLE: Reorder rows of different tables so there is only 1 file created per table. This value makes HVR buffer all changes during the integrate cycle before it writes them.
SORT_COALESCE: Sort and coalesce all changes for the cycle, so that only a single change remains for each row in the target file. This is equivalent to setting the Method parameter BURST for database locations. If you define this option for any table, it affects all tables that you integrate to that file location. A side effect of this value is that key updates (hvr_op 3 then 2) are replaced with a delete and insert (hvr_op 0 then 1) and a 'before' value for a regular update (hvr_op=4) is not written.
A column can be added by defining action ColumnProperties with parameter Extra which contains the type of operation. This can use either parameter IntegrateExpression={hvr_op} or multiple actions with ExpressionScope=scope with IntegrateExpression=const.
Adding such a column does not affect which operations (like INSERT, UPDATE, DELETE) are written to files. Instead, This depends on whether parameter SoftDelete or TimeKey are defined in action ColumnProperties.
Inserts (hvr_op=1) and 'after updates' (hvr_op=2) are always written.
Deletes (hvr_op=0), 'before key updates' (hvr_op=3), and 'truncates' (hvr_op=5) are written if either parameter SoftDelete or TimeKey is defined.
Before non-key updates (hvr_op=4) are only written if TimeKey is defined.
Resilient
Argument: mode
Description: Resilient integration of inserts, updates, and deletes.
Available options for mode are:
- SILENT
- SILENT_DELETES
- WARNING
Expand for more information
This parameter modifies the integration behavior when a change cannot be processed normally. If a row already exists, an insert operation is converted to an update. For a non-existent row, an update operation is converted to an insert, and the deletion of a non-existent row is discarded. A row's existence is determined using the replication key known to HVR, rather than checking the actual indexes or constraints on the target table. While resilience is a straightforward way to enhance replication robustness, it has the disadvantage of potentially allowing consistency problems to go undetected.
Additionally, HVR treats an update operation as a two-part process: before-update and after-update. Before-update contains the values before the update happened, and after-update contains the new values. If after-update contains missing values, it cannot be converted to an insert. Similarly, if before-update does not exist on target, HVR cannot perform the update and skips the operation. This is especially relevant to HANA locations.
This parameter controls whether an error message is generated when such inconsistencies occur.
This parameter has no effect if the TimeKey parameter in ColumnProperties action is defined in the channel.
OnErrorSaveFailed
Description: On integrate error, write the failed change into 'fail table' tbl__f and then continue integrating other changes.
Expand for more information
Changes written into the fail table can be retried afterwards (see command hvrretryfailed). If certain errors occur, then the integrate will no longer fail. Instead, the current file's data will be 'saved' in the file location's state directory, and the integrate job will write a warning and continue processing other replicated files. The file integration can be reattempted (see command hvrretryfailed). Note that this behavior affects only certain errors, for example, if a target file cannot be changed because someone has it open for writing. Other error types (e.g. disk full or network errors) are still fatal. They will just cause the integrate job to fail.
If this parameter is not defined and if an integrate error occurs, by default a fatal error is written and the job is stopped.
If data is being replicated from database locations and this parameter is defined for any table, then it affects all tables integrated to that location.
This parameter cannot be used when parameter Method is set to BURST.
For Salesforce, this parameter causes failed rows/files to be written to a fail directory ($HVR_CONFIG/work/hub/chn/loc/sf) and an error message to be written which describes how the rows can be retried.
DbProc
Description: Apply database changes by calling integrate database procedures instead of using direct SQL statements (insert, update, and delete).
The database procedures are created by hvractivate and called tbl__ii, tbl__iu, tbl__id. This parameter cannot be used on tables with long column data types.
This parameter is supported only for certain location types. For the list of supported location types, see Integrate with parameter DbProc in Capabilities.
- This parameter has been deprecated since version 6.1.0/0.
- This parameter cannot be used on tables with long data types, for example long varchar or blob.
TxBundleSize
Argument: int
Description: Bundle small transactions together for improved performance.
Expand for more information
The default transaction bundle size is 100.
For example, if the bundle size is 10 and there were 5 transactions with 3 changes each, then the first 3 transactions would be grouped into a transaction with 9 changes and the others would be grouped into a transaction with 6 changes. Transaction bundling does not split transactions.
This parameter cannot be used in combination with Burst Integrate (Method=BURST).
If this parameter is defined for any table, then it affects all tables integrated to that location.
TxSplitLimit
Argument: int
Description: Split very large transactions to limit resource usage.
Expand for more information
The default is 0, which means transactions are never split.
For example, if a transaction on the master database affected 10 million rows and the remote databases has a small rollback segment then if the split limit was set to 1000000 the original transaction would split into 10 transactions of 1 million changes each.
This parameter cannot be used in combination with Burst Integrate (Method=BURST).
If this parameter is defined for any table, then it affects all tables integrated to that location.
NoTriggerFiring
Description: Enable or disable database triggers during integrate.
Expand for more information
This parameter is supported only for certain location types. For the list of supported location types, see Disable/enable database triggers during integrate (NoTriggerFiring) in Capabilities.
Other ways to control trigger firing are described in Managing Recapturing Using Session Names.
For Ingres, this parameter disables the firing of all database rules during integration. This is done by performing SQL statement set norules at connection startup.
For SQL Server, this parameter disables the firing of database triggers, foreign key constraints, and check constraints during integration if those objects were defined with not for replication. This is done by connecting to the database with the SQL Server Replication connection capability. A disadvantage of this connection type is that the database connection string must have form host*,port instead of form \\host\instance*_. This port needs to be configured in the Network Configuration section of the SQL Server Configuration Manager. Another limitation is that encryption of the ODBC connection is not supported if this parameter is used for SQL Server.
For Oracle and SQL Server, hvrrefresh will automatically disable triggers on target tables before the refresh and re-enable them afterwards, unless option -q is defined.
SessionName
Argument: sess_name
Description: Integrate changes with specific session name.
Expand for more information
The default session name is hvr_integrate.
Capture triggers/rules check the session name to avoid recapturing changes during bidirectional replication. For a description of recapturing and session names see Managing Recapturing Using Session Names and Capture. If this parameter is defined for any table, then it affects all tables integrated to that location.
Topic
Kafka
Argument: expression
Description: Name of the Kafka topic. You can use strings/text or expressions as Kafka topic name.
Expand for more information
Following are the expressions to substitute capture location or table or schema name as topic name:
{hvr_cap_loc}: for capture location name.
{hvr_tbl_name}: for current table name. This is only allowed if the channel is defined with tables.
{hvr_schema}: for schema name of the table. This is only allowed if the channel is defined with tables and this can only be used when action TableProperties with parameter Schema=my_schema is explicitly defined for these tables on the target file location.
If this parameter is not defined, the messages are sent to the location's Default Topic field. The default topic field may also contain the above expressions. The Kafka topics used should either exist already in the Kafka broker or it should be configured to auto-create Kafka topic when HVR sends a message.
KeySubjectStrategy
Since v6.3.5/5 Kafka
Argument: mode
Description: Controls how schema subjects are named using one of four strategies according to Confluent Kafka Schema Registry requirements.
Available options for mode are:
- TopicNameStrategy
- RecordNameStrategy
- TopicRecordNameStrategy
- TopicNameSuffixStrategy
Expand for more information
This parameter modifies the integration behavior for Key part subject generation in case of using Schema Registry. When the topic name equals the table name, for example, when the Topic parameter is not set, or when the Topic expression still includes the table name, TopicNameSuffixStrategy and TopicNameStrategy produce identical subjects. TopicRecordNameStrategy is the recommended strategy for new configurations where the topic name does not rely on the table name. Using either parameter without a configured Schema Registry URL raises a configuration error.
Default value: TopicNameSuffixStrategy. This is a legacy format that is incompatible with standard Confluent Schema Registry strategies.
This parameter has no effect if the MessageKeySerializer parameter is set to STRING
ValueSubjectStrategy
Since v6.3.5/5 Kafka
Argument: mode
Description: Controls how schema subjects are named using one of four strategies according to Confluent Kafka Schema Registry requirements.
Available options for mode are:
- TopicNameStrategy
- RecordNameStrategy
- TopicRecordNameStrategy
- TopicNameSuffixStrategy
Expand for more information
This parameter modifies the integration behavior for Value part subject generation in case of using Schema Registry. When the topic name equals the table name, for example, when the Topic parameter is not set, or when the Topic expression still includes the table name, TopicNameSuffixStrategy and TopicNameStrategy produce identical subjects. TopicRecordNameStrategy is the recommended strategy for new configurations where the topic name does not rely on the table name. Using either parameter without a configured Schema Registry URL raises a configuration error.
Default value: TopicNameSuffixStrategy. This is a legacy format that is incompatible with standard Confluent Schema Registry strategies.
MessageKey
Kafka
Argument: expression
Description: Expression to generate user-defined key in a Kafka message. An expression can contain constant strings mixed with substitutions.
Expand for more information
When this parameter is not defined and action FileFormat with parameter Json or Avro (and location property Kafka_Schema_Registry) is defined, the default value for MessageKey is {"schema":string, "payload": {hvr_key_hash}}
Possible substitutions include:
{hvr_cap_loc} is replaced with the name of the source location where the change occurred.
{hvr_cap_subdirs} and {hvr_cap_filename} are also allowed if the file was captured from a file location.
{hvr_cap_tstamp [spec]} is replaced with the moment (time) that the change occurred in source location. The
defaultformat is %[utc] %Y%m%d%H%M%S, but this can be overridden using the timestamp substitution format specifier spec. For more information, see Timestamp Substitution Format Specifier. This substitution is supported only during Integrate and not supported during Refresh.{hvr_cap_user} is replaced with the name of the user who made the change.
{hvr_chn_name} is replaced with the name of the channel.
{colname [spec]} is replaced/substituted with the value of current table's column colname. If the column has a date and time data type, the
defaultformat is %[utc] %Y%m%d%H%M%S, but this can be overridden using the timestamp substitution format specifier spec. For more information, see Timestamp Substitution Format Specifier.{colname %[allow_missings]} - if the value of column colname is missing, instead of an error, the {%[allow_missings]} specifier causes HVR to replace the value with a default value (0 or an empty string). The {%[allow_missings]} must be the first specifier, if there are more than one (e.g. {%[allow_missings] %[localtime] %H%M%S}).
{hvr_integ_key} is replaced with a 36 byte string value (hex characters) which is unique and continuously increasing for all rows integrated into the target location. The value is calculated using a high precision timestamp of the moment that the row is integrated. This means that if changes from the same source database are captured by different channels and delivered to the same target location then the order of this sequence will not reflect the original change order. This contrasts with substitution {hvr_integ_seq} where the order of the value matches the order of the change captured. Another consequence of using a (high precision) integrate timestamp is that if the same changes are sent again to the same target location (for example after option 'capture rewind' of hvractivate, or if a Kafka location's integrate job is restarted due to interruption) then the 're-sent' change will be assigned a new value. This means the target databases cannot rely on this value to detect 're-sent' data.
{hvr_integ_seq} is replaced with a 45 byte string value (hex characters) which is unique and continuously increasing for a specific source location. If the channel has multiple source locations then this substitution must be combined with {hvr_cap_loc} to give a unique value for the entire target location. The value is derived from source database's DBMS logging sequence, e.g. the Oracle System Change Number (SCN). This substitution only has a value during Integrate or if the Select Moment - Specific Time option was selected in Refresh Data dialog (in CLI hvrrefresh with option
-Mtime.{hvr_integ_tstamp [spec]} is replaced with the moment (time) that the file was integrated into target location. The
defaultformat is %[utc] %Y%m%d%H%M%SSSS, but this can be overridden using the timestamp substitution format specifier spec. For more information, see Timestamp Substitution Format Specifier. If a format is supplied with spec, then HVR will throttle file integration to no faster than one file per second.{hvr_key_hash} is replaced with the hashed value of the key of current row This is only allowed if the channel is a Kafka location and action FileFormat with parameter Json or Avro (without using Schema Registry) is defined.
{{hvr_key_names sep}} is replaced with the values of table's key columns concatenated together with separator sep. If the value of a key column is missing (this happens during multi-delete operations with SapUnpack), it is replaced with a default value (0 or an empty string).
{hvr_key_names sep} is replaced with the names of table's key columns concatenated together with separator sep.
{hvr_op} is replaced with the HVR operation type. Values are 0 (delete), 1 (insert), 2 (after update), 3 (before key update), 4 (before non–key update) or 5 (truncate table). See also Extra Columns for Capture, Fail and History Tables.
{hvr_schema} is replaced with the schema name of the table. This is only allowed if the channel is defined with the tables. This can only be used when action TableProperties with parameter Schema=my_schema is explicitly defined for these tables on the target file location.
{hvr_slice_num}: is replaced with the current slice number if slicing is defined with Count (option
-Snum) in hvrrefresh or hvrcompare.{hvr_slice_total}: is replaced with the total number of slices if slicing is defined with Count (option
-Snum) in hvrrefresh or hvrcompare.{hvr_slice_value}: is replaced with the current slice value if slicing is defined with Series (option
-S val1[;val2]...) in hvrrefresh or hvrcompare.{hvr_tbl_base_name} is replaced with the base name of the current table. This is only allowed if the channel is defined with the tables.
{hvr_tbl_name} is replaced with the name of the current table. This is only allowed if the channel is defined with the tables.
{hvr_tx_countdown} is replaced with countdown of changes within transaction, for example if a transaction contains three changes the first change would have countdown value 3, then 2, then 1. A value of 0 indicates that commit information is missing for that change.
{hvr_tx_scn} is replaced with the source location's SCN (Oracle). This substitution can only be used if the source location database is Oracle. This substitution can only be used for ordering if the channel has a single source location. This substitution only has a value during Integrate or if the Select Moment - Specific Time option was selected in Refresh Data dialog (in CLI hvrrefresh with option
-Mtime).{hvr_tx_sequence_number} is replaced with the source location's sequence_number (Db2 for i). This substitution can only be used if the source location database is Db2 for i. This substitution can only be used for ordering if the channel has a single source location. This substitution only has a value during Integrate.
Since v6.2.5/4{hvr_tx_seq} is replaced with a hex representation of the sequence number of transaction. For capture from Oracle this value can be mapped back to the SCN of the transaction's commit statement. Value [hvr_tx_seq, -hvr_tx_countdown] is increasing and uniquely identifies each change. This substitution only has a value during Integrate or if the Select Moment - Specific Time option was selected in Refresh Data dialog (in CLI hvrrefresh with option
-Mtime).{hvr_var_xxx} is replaced with value of 'context variable' xxx. The value of a context variable can be supplied using option
–Vxxx=valto command hvrrefresh or hvrcompare.If the file was captured with a 'named pattern' (see parameter Pattern in action Capture), then the string that matched the named pattern can be used as a substitution. So if a file was matched with parameter Pattern="{office}.txt" then it could be renamed with expression hello_{office}.data.
It is recommended to define parameter Context when using the substitutions {hvr_var_xxx}, {hvr_slice_num}, {hvr_slice_total}, or {hvr_slice_value}, so that it can be easily disabled or enabled.
{hvr_slice_num}, {hvr_slice_total}, {hvr_slice_value} cannot be used if the one of the old slicing substitutions {hvr_var_slice_condition}, {hvr_var_slice_num}, {hvr_var_slice_total}, or {hvr_var_slice_value} is defined in the channel/table involved in the compare/refresh.
MessageKeySerializer
Kafka
Argument: format
Description: Serialization format of the Kafka message key. HVR encodes the generated Kafka message key into the selected serialization format.
Expand for more information
Available options for the format are:
STRING: The message key is encoded as a plain string without any schema description. This is the default format if the location property Kafka_Schema_Registry is not defined.
KAFKA_AVRO: The message key is encoded as a basic Avro string with schema description. For example -
{type:“string”}. This format is compatible with the Confluent Kafka Schema Registry. This is the default format if the location property Kafka_Schema_Registry is defined.KAFKA_JSON: The message key is encoded as a basic JSON string with schema description. For example -
{type:“string”}.KAFKA_AVRO_SCHEMA
Since v6.1.5/5: The message key is encoded as a more detailed Avro string with schema description listing all key columns along with their data types. For example, a table named salesorder with columns prod_id and ord_id is represented below. Note that the table name is always appended with _key.{ "type": "record", "name": "salesorder_key", "fields": [ { "name": "prod_id", "type": "long", "default": 0 }, { "name": "ord_id", "type": "long", "default": 0 } ] }KAFKA_JSON_SCHEMA
Since v6.1.5/5: The message key is encoded as a more detailed JSON string with schema description listing all key columns along with their data types. For example, a table named salesorder with columns prod_id and ord_id is represented as below. Note that the table name is always appended with _key.{ "type": "object", "name": "salesorder_key", "properties": { "prod_id": { "type": "integer" }, "ord_id": { "type": "integer" } } }
MessageHeaders
Since v6.2.5/1 Kafka
Argument: key=value
Description: Add custom headers to Kafka messages as key-value pairs.
To specify multiple key-value pairs, use a semicolon-separated format: key=value;key=value;...
The value can be either plain text or a substitution. For example, name=HVR;id={id}, where id is a source column name.
Expand for more information
Possible substitutions for value include:
{hvr_cap_loc} is replaced with the name of the source location where the change occurred.
{hvr_cap_subdirs} and {hvr_cap_filename} are also allowed if the file was captured from a file location.
{hvr_cap_tstamp [spec]} is replaced with the moment (time) that the change occurred in source location. The
defaultformat is %[utc] %Y%m%d%H%M%S, but this can be overridden using the timestamp substitution format specifier spec. For more information, see Timestamp Substitution Format Specifier. This substitution is supported only during Integrate and not supported during Refresh.{hvr_cap_user} is replaced with the name of the user who made the change.
{hvr_chn_name} is replaced with the name of the channel.
{colname [spec]} is replaced/substituted with the value of current table's column colname. If the column has a date and time data type, the
defaultformat is %[utc] %Y%m%d%H%M%S, but this can be overridden using the timestamp substitution format specifier spec. For more information, see Timestamp Substitution Format Specifier.{colname %[allow_missings]} - if the value of column colname is missing, instead of an error, the {%[allow_missings]} specifier causes HVR to replace the value with a default value (0 or an empty string). The {%[allow_missings]} must be the first specifier, if there are more than one (e.g. {%[allow_missings] %[localtime] %H%M%S}).
{hvr_integ_key} is replaced with a 36 byte string value (hex characters) which is unique and continuously increasing for all rows integrated into the target location. The value is calculated using a high precision timestamp of the moment that the row is integrated. This means that if changes from the same source database are captured by different channels and delivered to the same target location then the order of this sequence will not reflect the original change order. This contrasts with substitution {hvr_integ_seq} where the order of the value matches the order of the change captured. Another consequence of using a (high precision) integrate timestamp is that if the same changes are sent again to the same target location (for example after option 'capture rewind' of hvractivate, or if a Kafka location's integrate job is restarted due to interruption) then the 're-sent' change will be assigned a new value. This means the target databases cannot rely on this value to detect 're-sent' data.
{hvr_integ_seq} is replaced with a 45 byte string value (hex characters) which is unique and continuously increasing for a specific source location. If the channel has multiple source locations then this substitution must be combined with {hvr_cap_loc} to give a unique value for the entire target location. The value is derived from source database's DBMS logging sequence, e.g. the Oracle System Change Number (SCN). This substitution only has a value during Integrate or if the Select Moment - Specific Time option was selected in Refresh Data dialog (in CLI hvrrefresh with option
-Mtime.{hvr_integ_tstamp [spec]} is replaced with the moment (time) that the file was integrated into target location. The
defaultformat is %[utc] %Y%m%d%H%M%SSSS, but this can be overridden using the timestamp substitution format specifier spec. For more information, see Timestamp Substitution Format Specifier. If a format is supplied with spec, then HVR will throttle file integration to no faster than one file per second.{{hvr_key_names sep}} is replaced with the values of table's key columns concatenated together with separator sep. If the value of a key column is missing (this happens during multi-delete operations with SapUnpack), it is replaced with a default value (0 or an empty string).
{hvr_key_names sep} is replaced with the names of table's key columns concatenated together with separator sep.
{hvr_op} is replaced with the HVR operation type. Values are 0 (delete), 1 (insert), 2 (after update), 3 (before key update), 4 (before non–key update) or 5 (truncate table). See also Extra Columns for Capture, Fail and History Tables.
{hvr_schema} is replaced with the schema name of the table. This is only allowed if the channel is defined with the tables. This can only be used when action TableProperties with parameter Schema=my_schema is explicitly defined for these tables on the target file location.
{hvr_slice_num}: is replaced with the current slice number if slicing is defined with Count (option
-Snum) in hvrrefresh or hvrcompare.{hvr_slice_total}: is replaced with the total number of slices if slicing is defined with Count (option
-Snum) in hvrrefresh or hvrcompare.{hvr_slice_value}: is replaced with the current slice value if slicing is defined with Series (option
-S val1[;val2]...) in hvrrefresh or hvrcompare.{hvr_tbl_base_name} is replaced with the base name of the current table. This is only allowed if the channel is defined with the tables.
{hvr_tbl_name} is replaced with the name of the current table. This is only allowed if the channel is defined with the tables.
{hvr_tx_countdown} is replaced with countdown of changes within transaction, for example if a transaction contains three changes the first change would have countdown value 3, then 2, then 1. A value of 0 indicates that commit information is missing for that change.
{hvr_tx_scn} is replaced with the source location's SCN (Oracle). This substitution can only be used if the source location database is Oracle. This substitution can only be used for ordering if the channel has a single source location. This substitution only has a value during Integrate or if the Select Moment - Specific Time option was selected in Refresh Data dialog (in CLI hvrrefresh with option
-Mtime.{hvr_tx_seq} is replaced with a hex representation of the sequence number of transaction. For capture from Oracle this value can be mapped back to the SCN of the transaction's commit statement. Value [hvr_tx_seq, -hvr_tx_countdown] is increasing and uniquely identifies each change. This substitution only has a value during Integrate or if the Select Moment - Specific Time option was selected in Refresh Data dialog (in CLI hvrrefresh with option
-Mtime.{hvr_var_xxx} is replaced with value of 'context variable' xxx. The value of a context variable can be supplied using option
–Vxxx=valto command hvrrefresh or hvrcompare.If the file was captured with a 'named pattern' (see parameter Pattern in action Capture), then the string that matched the named pattern can be used as a substitution. So if a file was matched with parameter Pattern="{office}.txt" then it could be renamed with expression hello_{office}.data.
In Kafka, headers are additional metadata attached to a message that provides additional information about the message. They are key-value pairs that accompany the message payload (the actual data). Adding headers increases the size of your Kafka messages. Ensure that the configured headers do not cause the Kafka message size to exceed its limits.
This parameter applies only to the Kafka schema registry formats - AVRO and JSON.
OnDeleteSendTombstone
Since v6.1.5/8 Kafka
Description: Convert DELETE operations from a source location into Kafka tombstone messages on a target Kafka location.
If the SoftDelete or Timekey parameters in ColumnProperties action are defined, HVR will send an additional tombstone message for DELETE operation. This message will contain the key from the deleted record and an empty value.
This parameter applies only to the Kafka schema registry formats - AVRO and JSON.
RenameExpression
Argument: expression
Description: Expression to name new files. A rename expression can contain constant strings mixed with substitutions.
Expand for more information
Possible substitutions include:
{hvr_cap_loc} is replaced with the name of the source location where the change occurred.
{hvr_cap_subdirs} and {hvr_cap_filename} are also allowed if the file was captured from a file location.
{hvr_cap_tstamp [spec]} is replaced with the moment (time) that the change occurred in source location. The
defaultformat is %[utc] %Y%m%d%H%M%S, but this can be overridden using the timestamp substitution format specifier spec. For more information, see Timestamp Substitution Format Specifier. This substitution is supported only during Integrate and not supported during Refresh.{hvr_cap_user} is replaced with the name of the user who made the change.
{hvr_chn_name} is replaced with the name of the channel.
{colname [spec]} is replaced/substituted with the value of current table's column colname. This can be used to partition data into subdirectories based on column values. For example, if you have a column named "states", your rename expression could include states='{states}', which creates a dynamic folder, for example, states='CA' if the row value was CA for the state. The [spec] is usually associated with date/datetime formats. The
defaultformat is %[utc] %Y%m%d%H%M%S, but this can be overridden using the timestamp substitution format specifier spec if the column has a date and time data type. For more information, see Timestamp Substitution Format Specifier.
Example: /RenameExpression="{hvr_tbl_name}/state='{state}'/{hvr_integ_tstamp}.csv"{colname %[allow_missings]} - if the value of column colname is missing, instead of an error, the {%[allow_missings]} specifier causes HVR to replace the value with a default value (0 or an empty string). The {%[allow_missings]} must be the first specifier if there are more than one (e.g. {%[allow_missings] %[localtime] %H%M%S}).
{hvr_integ_key} is replaced with a 36 byte string value (hex characters) which is unique and continuously increasing for all rows integrated into the target location. The value is calculated using a high precision timestamp of the moment that the row is integrated. This means that if changes from the same source database are captured by different channels and delivered to the same target location then the order of this sequence will not reflect the original change order. This contrasts with substitution {hvr_integ_seq} where the order of the value matches the order of the change captured. Another consequence of using a (high precision) integrate timestamp is that if the same changes are sent again to the same target location (for example after option 'capture rewind' of hvractivate, or if a Kafka location's integrate job is restarted due to interruption) then the 're-sent' change will be assigned a new value. This means the target databases cannot rely on this value to detect 're-sent' data.
{hvr_integ_seq} is replaced with a 45 byte string value (hex characters) which is unique and continuously increasing for a specific source location. If the channel has multiple source locations then this substitution must be combined with {hvr_cap_loc} to give a unique value for the entire target location. The value is derived from source database's DBMS logging sequence, e.g. the Oracle System Change Number (SCN). This substitution only has a value during Integrate or if the Select Moment - Specific Time option was selected in Refresh Data dialog (in CLI hvrrefresh with option
-Mtime.{hvr_integ_tstamp [spec]} is replaced with the moment (time) that the file was integrated into target location. The
defaultformat is %[utc] %Y%m%d%H%M%SSSS, but this can be overridden using the timestamp substitution format specifier spec. For more information, see Timestamp Substitution Format Specifier. If a format is supplied with spec, then HVR will throttle file integration to no faster than one file per second.\{{hvr_key_names sep}} is replaced with the values of table's key columns concatenated together with separator sep. If the value of a key column is missing (this happens during multi-delete operations with SapUnpack), it is replaced with a default value (0 or an empty string).
{hvr_key_names sep} is replaced with the names of table's key columns concatenated together with separator sep.
{hvr_op} is replaced with the HVR operation type. Values are 0 (delete), 1 (insert), 2 (after update), 3 (before key update), 4 (before non–key update) or 5 (truncate table). See also Extra Columns for Capture, Fail and History Tables.
{hvr_schema} is replaced with the schema name of the table. This is only allowed if the channel is defined with the tables. This can only be used when action TableProperties with parameter Schema=my_schema is explicitly defined for these tables on the target file location.
{hvr_slice_num}: is replaced with the current slice number if slicing is defined with Count (option
-Snum) in hvrrefresh or hvrcompare.{hvr_slice_total}: is replaced with the total number of slices if slicing is defined with Count (option
-Snum) in hvrrefresh or hvrcompare.{hvr_slice_value}: is replaced with the current slice value if slicing is defined with Series (option
-S val1[;val2]...) in hvrrefresh or hvrcompare.{hvr_tbl_base_name} is replaced with the base name of the current table. This is only allowed if the channel is defined with the tables.
{hvr_tbl_name} is replaced with the name of the current table. This is only allowed if the channel is defined with the tables.
{hvr_tx_countdown} is replaced with countdown of changes within transaction, for example if a transaction contains three changes the first change would have countdown value 3, then 2, then 1. A value of 0 indicates that commit information is missing for that change.
{hvr_tx_scn} is replaced with the source location's SCN (Oracle). This substitution can only be used if the source location database is Oracle. This substitution can only be used for ordering if the channel has a single source location. This substitution only has a value during Integrate or if the Select Moment - Specific Time option was selected in Refresh Data dialog (in CLI hvrrefresh with option
-Mtime.{hvr_tx_seq} is replaced with a hex representation of the sequence number of transaction. For capture from Oracle this value can be mapped back to the SCN of the transaction's commit statement. Value [hvr_tx_seq, -hvr_tx_countdown] is increasing and uniquely identifies each change. This substitution only has a value during Integrate or if the Select Moment - Specific Time option was selected in Refresh Data dialog (in CLI hvrrefresh with option
-Mtime.{hvr_var_xxx} is replaced with value of 'context variable' xxx. The value of a context variable can be supplied using option
–Vxxx=valto command hvrrefresh or hvrcompare.If the file was captured with a 'named pattern' (see parameter Pattern in action Capture), then the string that matched the named pattern can be used as a substitution. So if a file was matched with parameter Pattern="{office}.txt" then it could be renamed with expression hello_{office}.data.
It is recommended to define Context when using the substitutions {hvr_var_xxx}, {hvr_slice_num}, {hvr_slice_total}, or {hvr_slice_value}, so that it can be easily disabled or enabled.
{hvr_slice_num}, {hvr_slice_total}, {hvr_slice_value} cannot be used if the one of the old slicing substitutions {hvr_var_slice_condition}, {hvr_var_slice_num}, {hvr_var_slice_total}, or {hvr_var_slice_value} is defined in the channel/table involved in the compare/refresh.
When this parameter is not defined -
The new files are named {hvr_cap_subdirs}/{hvr_cap_filename} if they are captured from another file location.
The new files are named {hvr_integ_tstamp}.xml if they are for database changes and the channel is defined with tables.
ComparePattern
Argument: pattern
Description: Perform direct file compare.
Expand for more information
During compare, HVR reads and parses (deserializes) files directly from a file location instead of using HIVE external tables (even if it is configured for that location).
While performing direct file compare, the files of each table are distributed to pre-readers. The file 'pre-read' subtasks generate intermediate files. The location for these intermediate files can be configured by defining the location property Intermediate_Directory.
To configure the number of pre-read subtasks during compare use Comparing data with option File Prereaders per Table or command hvrcompare with option -w.
This parameter is only applicable for file-based target locations.
HVR can parse only CSV or XML file formats and does not support Avro, Parquet or JSON.
Example: {hvr_tbl_name}/**/*.csv
To perform direct file compare, select the Generate Compare Event option in the Compare Data dialog (in CLI use hvrcompare -e).
ErrorOnOverwrite
Description: Error if a new file has same name as an existing file. If data is being replicated from database locations and this parameter is defined for any table, then it affects all tables integrated to that location.
MaxFileSize
Argument: int
Description: Threshold (in bytes) for bundling rows in a file.
Expand for more information
The rows are bundled into the same file until after this threshold is exceeded. After that happens, the file is finalized/closed and HVR will start writing rows to a new file.
The files written by HVR always contain at least one row, which means that specifying a very low size such as 1 byte will cause each file to contain a single row. For efficiency reasons HVR decision to start writing a new file depends on the length of the previous row, not the current row. This means that sometimes the actual file size may slightly exceed the value specified. If data is being replicated from database locations and this parameter is defined for any table, then it affects all tables integrated to that location.
This parameter cannot be used for 'blob' file channels which contain no table information and only replicated files as 'blobs'.
Verbose
Description: The file integrate job will write extra information, including the name of each file which is replicated. Normally, the job only reports the number of files written. If data is being replicated from database locations and this parameter is defined for any table, then it affects all tables integrated to that location.
TableName
Argument: userarg
Description: API name of Salesforce table into which attachments should be uploaded. For more information, see Salesforce Attachment Integration section below.
KeyName
Argument: userarg
Description: API name of key in Salesforce table for uploading attachments. For more information, see Salesforce Attachment Integration section below.
CycleByteLimit
Argument: int
Description: Maximum amount (in bytes) of compressed router files to process per integrate cycle.
Expand for more information
The default value is 10000000 bytes (10 MB). If parameter Method is set to BURST, then the default value is 100000000 bytes (100 MB).
Value 0 means unlimited, so the integrate job will process all available work in a single integrate cycle.
If more than this amount of data is queued for an integrate job, then it will process the work in 'sub cycles'. The benefit of 'sub cycles' is that the integrate job won't last for hours or days. If parameter Method is set to BURST, then large integrate cycles could boost the integrate speed, but they may require more resources (memory for sorting and disk room in the burst tables tbl_ _b).
If the supplied value is smaller than the size of the first transaction file in the router directory, then all transactions in that file will be processed. Transactions in a transaction file will never be split between cycles or sub-cycles.
If this parameter is defined for any table, then it affects all tables integrated to that location.
JournalRouterFiles
Description: Move processed transaction files to the journal directory HVR_CONFIG/hubs/hub/channels/channel/locs/location/jnl on the hub machine.
Normally an integrate job would just delete its processed transactions files. The journal files are compressed, but their contents can be viewed using command hvrrouterview.
If this parameter is defined for any table, then it affects all tables integrated to that location.
JournalBurstTable
Description: Keep track of changes in the burst table during Burst Integrate.
If this option is enabled, HVR will create a copy of the burst table in a separate audit table with some extra metadata like time-stamp, burst SQL statement etc. This is useful to easily recover in case of a failure during Burst Integrate.
Delay
Argument: n
Description: Delay integration of changes for n seconds.
Context
Argument: context
Description: Action Integrate is effective/applied only if the context matches the context defined in Compare or Refresh. For more information about using Context, see our concept page Refresh or Compare context.
The value should be a context name, specified as a lowercase identifier. It can also have form !context, which means that the action is effective unless the matching context is enabled for Compare or Refresh.
One or more contexts can be enabled for Compare and Refresh.
Defining an action that is only effective when a context is enabled can have different uses. For example, if action Integrate is defined with parameters RenameExpression and Context=qqq, then the file will only be renamed if context qqq is enabled in Compare or Refresh.
Columns Changed During Update
If an SQL update is done to one column of a source table, but other columns are not changed, then normally the UPDATE statement performed by HVR integrate will only change the column named in the original update. However, all columns will be overwritten if the change was captured using action Capture with parameter NoBeforeUpdate.
There are three exceptional situations where columns will never be overwritten by an update statement:
If action ColumnProperties is defined with parameter NoUpdate;
If the column has a LOB data type and was not change in the original update;
If the column was not mentioned in the channel definition.
Controlling Trigger Firing
Sometimes during integration it is preferable for application triggers not to fire. This can be achieved by changing the triggers so that they check the integrate session (for example where userenv('CLIENT_INFO') <>'hvr_integrate'). For more information, see section Application triggering during integration in Capture.
For Ingres target databases, the database rule firing can be prevented by defining action Integrate with parameter NoTriggerFiring or with hvrrefresh option –f.
Salesforce Attachment Integration
Attachments can be integrated into Salesforce.com by defining a 'blob' file channel (without table information) which captures from a file location and integrates into a Salesforce location. In this case, the API name of the Salesforce table containing the attachments can be defined either using action Integrate with parameter TableName or using 'named pattern' {hvr_sf_tbl_name} in the parameter Pattern of action Capture. Likewise, the key column can be defined either using action Integrate with parameter KeyName or using 'named pattern' {hvr_sf_key_name}. The value for each key must be defined with 'named pattern' {hvr_sf_key_value}.
For example, if the photo of each employee is named id.jpg, and these need to be loaded into a table named Employee with key column EmpId, then the following two actions should be defined; action Capture with parameter Pattern="{hvr_sf_key_value}.jpg" and action Integrate with parameters TableName="Employee" and KeyName="EmpId".
All rows integrated into Salesforce are treated as 'upserts' (an update or an insert). Deletes cannot be integrated.
Salesforce locations can only be used for replication jobs; HVR Refresh and HVR Compare are not supported.
Timestamp Substitution Format Specifier
Timestamp substitution format specifiers allows explicit control of the format applied when substituting a timestamp value. These specifiers can be used with {hvr_cap_tstamp[spec]}, {hvr_integ_tstamp[spec]}, and {colname [spec]} if colname has timestamp data type. The components that can be used in a timestamp format specifier spec are:
| Component | Description | Example |
|---|---|---|
| %a | Abbreviate weekday according to current locale. | Wed |
| %b | Abbreviate month name according to current locale. | Jan |
| %d | Day of month as a decimal number (01–31). | 07 |
| %H | Hour as number using a 24–hour clock (00–23). | 17 |
| %j | Day of year as a decimal number (001–366). | 008 |
| %m | Month as a decimal number (01 to 12). | 04 |
| %M | Minute as a decimal number (00 to 59). | 58 |
| %s | Seconds since epoch (1970–01–01 00:00:00 UTC). | 1099928130 |
| %S | Second (range 00 to 61). | 40 |
| %T | Time in 24–hour notation (%H:%M:%S). | 17:58:40 |
| %U | Week of year as decimal number, with Sunday as first day of week (00 – 53). | 30 |
%V Linux | The ISO 8601 week number, range 01 to 53, where week 1 is the first week that has at least 4 days in the new year. | 15 |
| %w | Weekday as decimal number (0 – 6; Sunday is 0). | 6 |
| %W | Week of year as decimal number, with Monday as first day of week (00 – 53) | 25 |
| %y | Year without century. | 14 |
| %Y | Year including the century. | 2014 |
| %[localtime] | Perform timestamp substitution using machine local time (not UTC). This component should be at the start of the specifier (for example, {{hvr_cap_tstamp %[localtime]%H}}). | |
| %[utc] | Perform timestamp substitution using UTC (not local time). This component should be at the start of the specifier (for example, {{hvr_cap_tstamp %[utc]%T}}). |