ColumnProperties
Action ColumnProperties defines properties of a column. This column is matched either by using parameter Name or DataType. The action itself has no effect other than the effect of the other parameters used. This affects both replication (on the Capture and Integrate side), Refresh, and Compare.
Parameters
This section describes the parameters available for action ColumnProperties.
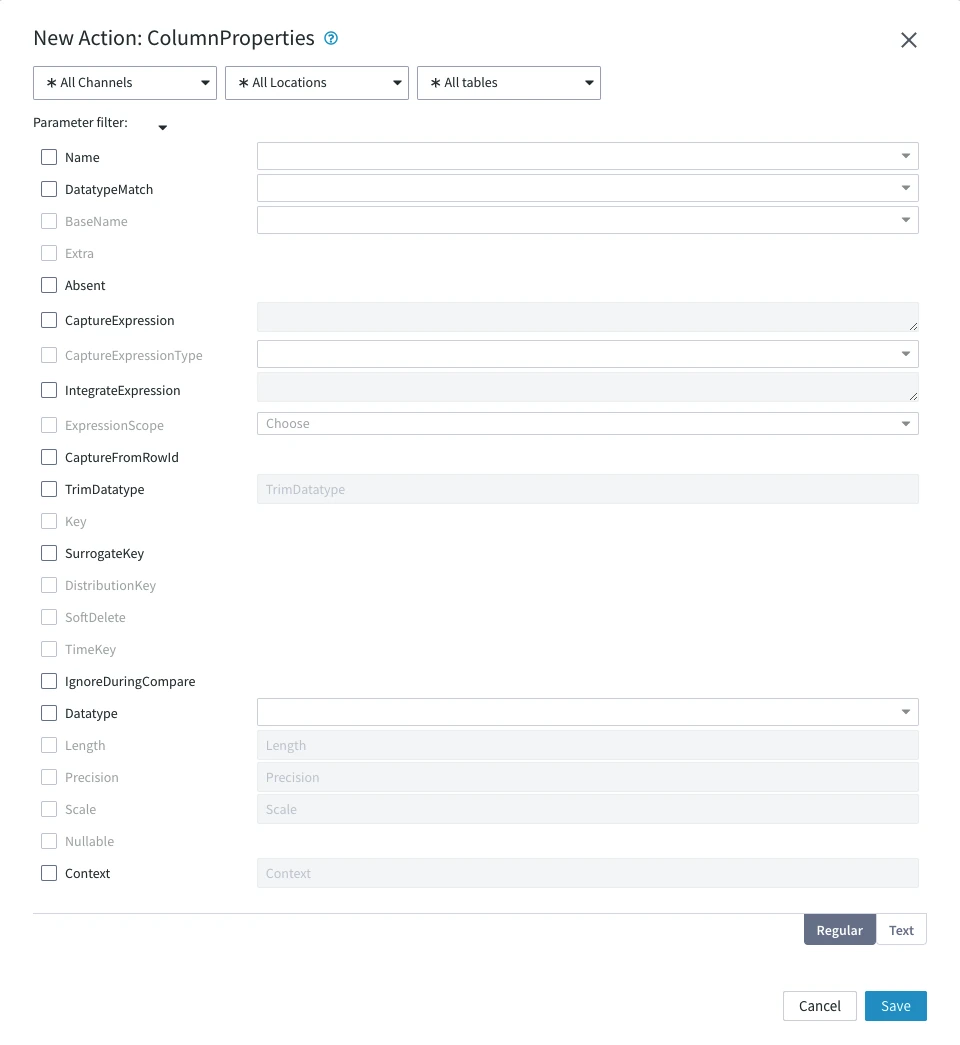
Following are the two tabs/ways, which you can use for defining action parameters in this dialog:
- Regular: Allows you to define the required parameters by using the UI elements like checkbox and text field.
- Text: Allows you to define the required parameters by specifying them in the text field. You can also copy-paste the action definitions from Fivetran HVR documentation, emails, or demo notes.
Name
Argument: col_name
Description: Match a column by name. This is the name of the column in the HVR_COLUMN repository table.
The col_name should not be the same as the substitution defined in CaptureExpression and IntegrateExpression. HVR will not populate values for the column if col_name and substitution (sql_expr) are the same. For example, when IntegrateExpression=hvr_op is used then in that action definition Name=hvr_op should not be used.
DatatypeMatch
Argument: datatypematch
Description: Match column by data type (instead of Name).
Value datatypematch can either be
a single data type name (such as number) or
a data type name with conditions, specified in the format: datatype[condition].
The format for condition is attribute operator value, where:
- attribute can be prec, scale, bytelen, charlen, encoding, or null
- operator can be =, <>, !=, <, >, <=, or >=
- value is an integer or a single-quoted string
Multiple conditions can be supplied, separated by &&.
Examples
DatatypeMatch="number"
DatatypeMatch="number[prec>=19]"
DatatypeMatch="varchar[bytelen>200]"
DatatypeMatch="varchar[encoding='UTF-8' && null='true']"
DatatypeMatch="number[prec=0 && scale=0]" - matches Oracle numbers without any explicit precision or scale.
This parameter can be used to associate a ColumnProperties action with all columns that match the specified data type and the optional attribute conditions.
BaseName
Argument: tbl_name
Description: Defines the actual name of the column in the database location, as opposed to the column name that HVR has in the channel.
This parameter is needed if the base name of the column is different in the capture and integrate locations. In that case, the column name in the HVR channel should have the same name as the 'base name' in the capture database and parameter BaseName should be defined on the integrate side. An alternative is to define the BaseName parameter on the capture database and have the name for the column in the HVR channel the same as the base name in the integrate database.
The concept of the base name in a location as opposed to the name in the HVR channel applies to both columns and tables, see parameter BaseName in action TableProperties.
Extra
Description: Column exists in the database but not in the HVR_COLUMN repository table. If a column has parameter Extra defined then its value is not captured and not read during Refresh or Compare. If the value is omitted then the appropriate default value is used (null, zero, empty string, etc.).
This parameter requires parameter Datatype or SoftDelete.
This parameter cannot be used on columns that are part of the replication key. Also, it cannot be defined in a given database on the same column, nor can either be combined on a column with parameter BaseName.
This parameter cannot be used together with parameters BaseName and Absent.
Absent
Description: Column does not exist in the database table. If no value is supplied with parameter CaptureExpression then an appropriate default value is used (null, zero, empty string, etc.). When replicating between two tables with a column that is in one table but is not in the other there are two options: either register the table in the HVR repository tables with all columns and add parameter Absent; or register the table without the extra column and add parameter Extra. The first option may be slightly faster because the column value is not sent over the network.
CaptureExpression
Argument: sql_expr
Description: SQL expression for column value when capturing changes or reading rows. This value may be a constant value or an SQL expression. This parameter can be used to 'map' values data values between a source and a target table. An alternative way to map values is to define an SQL expression on the target side using parameter IntegrateExpression. Possible SQL expressions include null, 5 or 'hello'. For many databases (e.g., Oracle and SQL Server) a subselect can be supplied, for example SELECT descrip FROM lookup WHERE id = {id};.
Expand to see the possible substitutions for the SQL expression
The SQL expression sql_expr can contain the following substitutions:
{colname [spec]} is replaced/substituted with the value of current table's column colname. If the target column has a character-based data type or if parameter Datatype=character_data_type is defined, the default format is %[localtime] %Y-%m-%d %H:%M:%S. The default format can be overridden using the timestamp substitution format specifier spec. For more information, see Timestamp Substitution Format Specifier.
{colname %[allow_missings]} if the value of column colname is missing, instead of an error, the {%[allow_missings]} specifier causes HVR to replace the value with a default value (0 or an empty string). The {%[allow_missings]} must be the first specifier, if there are more than one (e.g., {%[allow_missings] %[localtime] %H%M%S}).
{hvr_cap_loc} is replaced with the name of the source location where the change occurred.
{hvr_cap_tstamp [spec]} is replaced with the moment (time) that the change occurred in the source location. If the target column has a character-based data type or if parameter Datatype=character_data_type then the default format is %[localtime] %Y-%m-%d %H:%M:%S, but this can be overridden using the timestamp substitution format specifier spec. For more information, see Timestamp Substitution Format Specifier.
{hvr_cap_user} is replaced with the name of the user who made the change.
{{hvr_col_name [spec]}} is replaced with the value of the current column. If the target column has a character-based data type or if parameter Datatype=character_data_type is defined, the default format is %[localtime] %Y-%m-%d %H:%M:%S. The default format can be overridden using the timestamp substitution format specifier spec. For more information, see Timestamp Substitution Format Specifier.
{hvr_slice_num} is replaced with the current slice number if slicing is defined with Count (option -S num) in hvrrefresh or Compare.
{hvr_slice_total} is replaced with the total number of slices if slicing is defined with Count (option -S num) in hvrrefresh or Compare.
{hvr_slice_value} is replaced with the current slice value if slicing is defined with Series (option -S val1[;val2]...) in hvrrefresh or Compare.
{hvr_var_xxx} is replaced with value of 'context variable' xxx. The value of a context variable can be supplied using option –Vxxx=val in hvrrefresh or Compare.
It is recommended to define parameter Context when using the substitutions {hvr_slice_num}, {hvr_slice_total}, {hvr_slice_value}, or {hvr_var_xxx} so that it can be easily disabled or enabled.
{hvr_slice_num}, {hvr_slice_total}, {hvr_slice_value} cannot be used if the one of the old slicing substitutions {hvr_var_slice_condition}, {hvr_var_slice_num}, {hvr_var_slice_total}, or {hvr_var_slice_value} is defined in the channel/table involved in the compare/refresh.
For more information on how to substitute column values into SQL expressions, see the Substituting Column Values Into Expressions section below.
CaptureExpressionType
Argument: expr_type
Description: Type of mechanism used by Capture, Refresh, and Compare job to evaluate the value in parameter CaptureExpression.
Expand to see the options available for this parameter
Available options for expr_type are:
SQL_PER_CYCLE (
defaultfor database locations if the capture expression matches a pattern in file $HVR_HOME/etc/constsqlexpr.pat): The capture job only evaluates the expression once per replication cycle, so every row captured by that cycle will get the same value. It requires fewer database 'round-trips' than SQL_PER_ROW and SQL_WHERE_ROW. For Refresh and Compare jobs the expression is just included in the mainSELECTstatement, so no extra database round-trips are used and the database could assign each row a different value.This type is not supported for file locations.
SQL_PER_ROW (
defaultfor database locations if the capture expression does not match a pattern in file $HVR_HOME/etc/constsqlexpr.pat): The capture job evaluates the expression for each change captured. This means every row captured by that cycle could get a different value but requires more database 'round-trips' than SQL_PER_CYCLE. For Refresh and Compare jobs the expression is just included in the mainSELECTstatement, so no extra database round-trips are used and the database could assign each row a different value.This type is not supported for file locations.
SQL_WHERE_ROW: The capture job evaluates the expression for each change captured but with an extra
WHEREclause containing the key value for the table on which the change occurred. This allows that expression to include expressions like {colx} which reference other columns of that table. Each row captured could get a different value but requires more database 'round-trips' than SQL_PER_CYCLE. For Refresh and Compare jobs the expression is just included in the mainSELECTstatement (without the extraWHEREclause), so no extra database round-trips are used and the database could assign each row a different value.This type is not supported for file locations.
INLINE: String-based replacement by HVR itself.
IntegrateExpression
Argument: sql_expr
Description: SQL expression for column value when integrating changes or loading data into a target table. HVR may evaluate itself or use it as an SQL expression. This parameter can be used to 'map' values between a source and a target table. An alternative way to map values is to define an SQL expression on the source side using CaptureExpression. Possible expressions include null, 5, or 'hello'. For many databases (e.g., Oracle and SQL Server), a subselect can be supplied, for example SELECT descrip FROM lookup WHERE id = {id};.
When the integrate method is set to APPEND, the IntegrateExpression that must be delegated to the database for evaluation cannot be used.
Expand to see the possible substitutions for the SQL expression
The SQL expression sql_expr can contain the following substitutions:
{colname [spec]} is replaced/substituted with the value of current table's column colname. If the target column has a character-based data type or if parameter Datatype=character_data_type is defined, the default format is %[localtime] %Y-%m-%d %H:%M:%S, but this can be overridden using the timestamp substitution format specifier spec. For more information, see Timestamp Substitution Format Specifier.
{colname %[allow_missings]} - if the value of column colname is missing, instead of an error, the {%[allow_missings]} specifier causes HVR to replace the value with a default value (0 or an empty string). The {%[allow_missings]} must be the first specifier, if there are more than one (e.g., {%[allow_missings] %[localtime] %H%M%S}).
{hvr_cap_count_or_rrn} is replaced with the source location log record's count or RRN (Db2 for i). This substitution should only be used if the source location database is Db2 for i. It has a value only during Integrate and only if the environment variable HVR_DB2I_CAP_COUNT_OR_RRN=1 is defined on the source location.
Since v6.3.0/0{hvr_cap_entry_timestamp} is replaced with the source location log record's entry timestamp (Db2 for i). This substitution should only be used if the source location database is Db2 for i. It has a value only during Integrate and only if the environment variable HVR_DB2I_CAP_ENTRY_TIMESTAMP=1 is defined on the source location.
Since v6.3.0/0{hvr_cap_job} is replaced with the source location's job name (Db2 for i). This substitution should only be used if the source location database is Db2 for i. It has a value only during Integrate and only if the environment variable HVR_DB2I_CAP_JOB_NAME=1 is defined on the source location.
Since v6.2.5/7{hvr_cap_journal_code} is replaced with the source location log record's journal code (Db2 for i). This substitution should only be used if the source location database is Db2 for i. It has a value only during Integrate and only if the environment variable HVR_DB2I_CAP_JOURNAL_CODE=1 is defined on the source location.
Since v6.3.0/0{hvr_cap_journal_entry_type} is replaced with the source location log record's journal entry type (Db2 for i). This substitution should only be used if the source location database is Db2 for i. It has a value only during Integrate and only if the environment variable HVR_DB2I_CAP_JOURNAL_ENTRY_TYPE=1 is defined on the source location.
Since v6.3.0/0{hvr_cap_loc} is replaced with the name of the source location where the change occurred.
{hvr_cap_program} is replaced with the source location's program name (Db2 for i). This substitution should only be used if the source location database is Db2 for i. It has a value only during Integrate and only if the environment variable HVR_DB2I_CAP_PROGRAM_NAME=1 is defined on the source location.
Since v6.2.5/7{hvr_cap_sequence_number} is replaced with the source location log record's sequence number (Db2 for i). This substitution should only be used if the source location database is Db2 for i. It has a value only during Integrate and only if the environment variable HVR_DB2I_CAP_SEQUENCE_NUMBER=1 is defined on the source location.
Since v6.3.0/0{hvr_cap_tstamp [spec]} is replaced with the moment (time) that the change occurred in the source location. If the target column has a character-based data type or if parameter Datatype=character_data_type then the default format is %[localtime] %Y-%m-%d %H:%M:%S, but this can be overridden using the timestamp substitution format specifier spec. For more information, see Timestamp Substitution Format Specifier.
{hvr_cap_user} is replaced with the name of the user who made the change.
{hvr_chn_name} is replaced with the name of the channel.
{{hvr_col_name [spec]}} is replaced with the value of the current column. If the target column has a character-based data type or if parameter Datatype=character_data_type is defined, the default format is %[localtime] %Y-%m-%d %H:%M:%S. The default format can be overridden using the timestamp substitution format specifier spec. For more information, see Timestamp Substitution Format Specifier.
{hvr_integ_key} is replaced with a 16-byte string value (hex characters) that is unique and continuously increasing for all rows integrated into the target location. The value is calculated using the hexadecimal representation of the current epoch time when the first row is integrated. From there, the counter is incremented by one for every subsequent row. When the integrate process is restarted, a higher seed time will be used. This means that if changes from the same source database are captured by different channels and delivered to the same target location then the order of this sequence will not reflect the original change order. This contrasts with substitution {hvr_integ_seq} where the order of the value matches the order of the change captured, and recapturing changes with the same channel definition will result in the same output values. Another consequence of using a seed time with a sequence is that if the same changes are sent again to the same target location (for example, after option 'capture rewind' of hvractivate, or if a Kafka location's integrate job is restarted due to interruption) then the 're-sent' change will be assigned a new value. This means the target databases cannot rely on this value to detect 're-sent' data. This substitution is recommended for action ColumnProperties defined with parameter TimeKey if the channel has multiple source locations. If the integrate method is APPEND, the TimeKey column should be configured with {hvr_integ_seq} to ensure that data is reprocessed without inserting duplicates after the Integrate process is interrupted and restarted. Configuring the TimeKey column with {hvr_integ_key} instead may result in duplicates when the Integrate process recovers. If the integrate location is a Kafka or file location, TimeKey must be defined on that location to replicate delete operations.
{hvr_integ_seq} behaves differently during Refresh and Integrate.
During Refresh, it is replaced with a hexadecimal value starting from 1, incrementing by one for each subsequent row. This sequential assignment indicates the order in which rows were selected from the source table. The only exception is when Select Moment - Specific (option -Mtime) is set during Refresh.
The purpose of replacing it with hexadecimal values during Refresh is to establish a basis for TimeKey ordering, ensuring that all future changes processed by the Integrate job have a higher sequence number. However, if you refresh a table that has already been replicated using TimeKey, it may disrupt the ordering. Additionally, some records may receive different hexadecimal values compared to the initial load or previous Refresh runs.During Integrate, it is replaced with a string of up to 45 bytes (hexadecimal characters separated by
|), which is unique and continuously increasing for a specific source location. If the channel has multiple source locations, this substitution must be combined with {hvr_cap_loc} to give a unique value for the entire target location. The value is derived from the source database's DBMS logging sequence, for example, the Oracle System Change Number (SCN).
{hvr_integ_tstamp [spec]} is replaced with the moment (time) that the change was integrated into the target location. If the target column has a character-based data type or if parameter Datatype=character_data_type then the default format is %Y-%m-%d %H:%M:%S[.SSS], but this can be overridden using the timestamp substitution format specifier spec. For more information, see Timestamp Substitution Format Specifier.
\{{hvr_key_names sep}} is replaced with the values of the table's key columns, concatenated together with separator sep. If the value of a key column is missing (this happens during multi-delete operations with SapUnpack), it is replaced with a default value (0 or an empty string).
{hvr_key_names sep} is replaced with the names of the table's key columns, concatenated together with separator sep.
{hvr_op} is replaced with the HVR operation type. Values are 0 (delete), 1 (insert), 2 (after update), 3 (before key update), 4 (before non–key update) or 5 (truncate table). For the complete list of values supported by hvr_op, see hvr_op in Extra Columns for Capture, Fail and History Tables section. Note that this substitution cannot be used with parameter ExpressionScope. If the integrate location is a Kafka or file location, this substitution should be used as an extra column (Extra).
{hvr_op_str [mapping]} is replaced with the string representation of HVR operation (hvr_op) type.
Since v6.2.5/0
The default values for hvr_op_str are: 0 = D (delete), 1 = I (insert), 2 = U (after update), 3 = K (before key update), 4 = 4 (befornon-key update), 5 = T (truncate table).
If a custom mapping is defined, it will map hvr_op numeric values to the specified string. The format for custom mapping is hvr_op > string. Foexample, the default mapping is {hvr_op_str 0>D;1>I;2>U;3>K;4>4;5>T}.
If custom mapping is defined for only one or more hvr_op values, but not all, the remaining hvr_op values will not be mapped to a string. Instead, thewill stay as their numeric values. For example, with the custom mapping {hvr_op_str 0>D;1>I}, hvr_op 0 will be mapped to D and hvr_op 1 tI. However, if hvr_op 3 is encountered, it will not be mapped to the default string; it will remain as 3.
This substitution should be used as an extra column (Extra) with Datatype=char or varchar and Length=2 (or more). Since hvr_op can be a double-digit number, Length should be no less than 2.{hvr_schema} is replaced with the schema name of the table. This is only allowed if the channel is defined with the tables. This can only be used when action TableProperties with parameter Schema=my_schema is explicitly defined for these tables on the target file location.
{hvr_slice_num}: is replaced with the current slice number if slicing is defined with Count (option -S num) in hvrrefresh or hvrcompare.
{hvr_slice_total}: is replaced with the total number of slices if slicing is defined with Count (option -S num) in hvrrefresh or hvrcompare.
{hvr_slice_value}: is replaced with the current slice value if slicing is defined with Series (option -S val1[;val2]...) in hvrrefresh or hvrcompare.
{hvr_tbl_name} is replaced with the name of the current table.
{hvr_tbl_base_name} is replaced with the base name of the current table
{hvr_tx_countdown} is replaced with the countdown of changes within a transaction, for example, if a transaction contains three changes the first change would have countdown value 3, then 2, then 1. A value of 0 indicates that commit information is missing for that change. This substitution only has a value during Integrate or during Refresh if a select moment (option -M) was specified.
{hvr_tx_scn} is replaced with the source location's SCN (Oracle). This substitution can only be used if the source location database is Oracle. This substitution can only be used for ordering if the channel has a single source location. This substitution only has a value during Integrate or if Select Moment - Specific (option -Mtime) was specified during hvrrefresh.
When using this substitution, you must set the column’s data type to VARCHAR(10) by defining the Datatype parameter. However, if you want the column’s data type to be NUMBER, you must use the substitution as
CAST({hvr_tx_scn} AS NUMBER).{hvr_tx_sequence_number} is replaced with the source location's sequence_number (Db2 for i). This substitution can only be used if the source location database is Db2 for i. This substitution can only be used for ordering if the channel has a single source location. This substitution only has a value during Integrate.
Since v6.2.5/4{hvr_tx_seq} is replaced with a hex representation of the sequence number of the transaction. For capture from Oracle, this value can be mapped back to the SCN of the transaction's commit statement. Value [hvr_tx_seq, -hvr_tx_countdown] is increasing and uniquely identifies each change. This substitution only has a value during Integrate or if Select Moment - Specific (option -Mtime) was specified during hvrrefresh.
{hvr_var_xxx} is replaced with value of 'context variable' xxx. The value of a context variable can be supplied using option –Vxxx=val to command hvrrefresh or hvrcompare.
It is recommended to define parameter Context when using the substitutions {hvr_slice_num}, {hvr_slice_total}, {hvr_slice_value}, or {hvr_var_xxx} so that it can be easily disabled or enabled.
{hvr_slice_num}, {hvr_slice_total}, {hvr_slice_value} cannot be used if the one of the old slicing substitutions {hvr_var_slice_condition}, {hvr_var_slice_num}, {hvr_var_slice_total}, or {hvr_var_slice_value} is defined in the channel/table involved in the compare/refresh.
For more information on how to substitute column values into SQL expressions, see the Substituting Column Values Into Expressions section below.
ExpressionScope
Argument: expr_scope
Description: Scope for which operations (e.g., INSERT or DELETE) an integrate expression (parameter IntegrateExpression) should be used.
Available options for expr_scope are:
- DELETE
- INSERT
- UPDATE_AFTER
- UPDATE_BEFORE_KEY
- UPDATE_BEFORE_NONKEY
- TRUNCATE
Expand for more information
This parameter can be used only when action Integrate is defined with parameter Burst. This parameter is ignored for database targets if parameter Burst is not defined and for file targets (such as HDFS or S3). This burst restriction means that no scopes exist yet or for 'update before' operations (such as UPDATE_BEFORE_KEY and UPDATE_BEFORE_NONKEY). Only Bulk Refresh obeys this parameter (it always uses scope INSERT); Row-wise Refresh ignores the expression scope. This value of the affected IntegrateExpression parameter can contain its regular substitutions except for {hvr_op} which cannot be used.
Example 1: To add a column opcode to a target table (defined with parameter SoftDelete) containing values 'I', 'U', and 'D' (for insert, update, and delete respectively), define these actions:
| Action | Parameters |
|---|---|
| ColumnProperties | Name=opcode IntegrateExpression="'I'" ExpressionScope=INSERT Datatype=varchar Length=1 Nullable Extra |
| ColumnProperties | Name=opcode IntegrateExpression="'U'" ExpressionScope=UPDATE Datatype=varchar Length=1 Nullable Extra |
| ColumnProperties | Name=opcode IntegrateExpression="'D'" ExpressionScope=DELETE Datatype=varchar Length=1 Nullable Extra |
Example 2: To add a column insdate (only filled when a row is inserted) and column upddate (filled on update and SoftDelete), define these actions:
| Action | Parameters |
|---|---|
| ColumnProperties | Name=insdate IntegrateExpression=sysdate ExpressionScope=INSERT Datatype=timestamp Extra |
| ColumnProperties | Name=upddate IntegrateExpression=sysdate ExpressionScope=DELETE Datatype=timestamp Extra |
CaptureFromRowId
Description: Capture values from the table's DBMS row-id (Oracle, HANA) or Relative Record Number (RRN in Db2 for i). Define on the capture location.
This parameter is supported only for certain location classes. For the list of supported location classes, see Log-based capture from hidden rowid/RRN column in Capabilities.
This parameter is not supported for Oracle's Index Organized Tables (IOT).
TrimDatatype
Argument: int
Description: Reduce the width of data type when selecting or capturing changes. This parameter affects string data types (such as varchar, nvachar, and clob) and binary data types (such as raw and blob). The value int is a limit in bytes; if this value is exceeded then the column's value is truncated (from the right) and a warning is written.
For example, if action ColumnProperties is defined with the following parameters DatatypeMatch=clob, TrimDatatype=10, Datatype=varchar, Length=30, it will replicate all columns with data type clob into a target table as strings. Note that parameter Datatype and Length ensures that Refresh will create target tables with the smaller data type. Its length is smaller because Length parameter is used.
This parameter is supported only for certain location classes. For the list of supported location classes, see Reduce width of datatype when selecting or capturing changes in Capabilities.
Key
Description: Add column to table's replication key.
SurrogateKey
Description: Use column instead of the regular key during replication. Define on the capture and integrate locations.
Specify in combination with parameter CaptureFromRowId to capture from HANA or from Oracle tables to reduce supplemental logging requirements.
Integrating with SurrogateKey is impossible if the SurrogateKey column is captured from a CaptureFromRowId that is reusable (Oracle).
For Oracle, to use ROWID as a surrogate key, it must remain unchanged over time. Any change to ROWID can result in replication errors. Avoid using ROWID as a surrogate key if any operation might change it.
Oracle documentation states that ROWID is not a permanent identifier and may change under certain conditions, including, but not limited to:
- Partition key updates when row movement is enabled
- Flashback Table operations
- Shrink operations
- Export and import using Oracle utilities, which delete and reinsert rows
DistributionKey
Description: Distribution key column. The distribution key is used for parallelizing changes within a table. It also controls the DISTRIBUTED BY clause for a CREATE TABLE in distributed databases such as Teradata, Redshift, and Greenplum.
SoftDelete
Description: Convert DELETE operations in the source into UPDATE in the target.
Defining this parameter avoids the actual deletion of rows in the target. Instead, an extra column is added to indicate whether a row was deleted in the source. The initial value in this column is 0, indicating the row is not deleted. The value of this column is updated to 1 when a row is deleted in the source.
In each integrate cycle the changes are coalesced and optimized away. For example, if an INSERT and DELETE operation performed on a row happens in the same integrate cycle, these changes will be coalesced and optimized. As a result, a soft deleted row (with value 1) will not be added to the target. If the same changes happen in two separate integrate cycles, in the first cycle a row will be inserted in the target and in the second cycle, the row will be marked as deleted (value 1) in the target.
TimeKey
Description: Convert all changes (INSERT, UPDATE, DELETE in the source location) into INSERT in the target location.
Defining this parameter affects how all changes are delivered into the target table. This parameter is often used with parameter IntegrateExpression={hvr_integ_seq}, which will populate a value.
HVR uses the concept of TimeKey to indicate storing history. TimeKey is defined with an extra column on the target for every table uniquely storing the sequence in which changes came into the channel. Action ColumnProperties with parameter IntegrateExpression={hvr_integ_seq} uniquely defines the order in which the changes were applied in the source location.
When using this parameter, the integration process unconditionally appends every operation to the base table. This means that changes made during a Refresh might be captured and appended again, leading to apparent duplicate entries. Although this parameter adds an extra key column to prevent technical duplicates, you may still see two inserts for the same replication key due to Refresh overlaps.
If HVR is configured to replicate only some columns in a table, and an UPDATE affects only the non-replicated columns, the TimeKey still reflects the change.
For Kafka and File locations, this parameter must be defined to replicate DELETE operations.
IgnoreDuringCompare
Description: Ignore values in this column during Refresh and Compare. Also during integration, this parameter means that this column is overwritten by every update statement, rather than only when the captured update changed this column.
This parameter is ignored during row-wise compare/refresh if it is defined on a key column.
Datatype
Argument: data_type
Description: Data type in the database if this differs from the value defined in the HVR_COLUMN repository table.
Length
Argument: attr_val
Description: String length in the database if this differs from the value defined in the HVR_COLUMN repository table.
When used together with parameter Name or DatatypeMatch parameters, keywords bytelen and charlen can be used and will be replaced by respective values of the matched column. Additionally, basic arithmetic operators (+,-,*,/) can be used with bytelen and charlen. For example, if Length="bytelen/3" is defined, it will be replaced with the byte length of the matched column divided by 3.
This parameter requires parameter Datatype.
Precision
Argument: attr_val
Description: Integer precision in the database if this differs from the value defined in the HVR_COLUMN repository table.
When used together with Name or DatatypeMatch parameters, keywords prec can be used and will be replaced by respective values of the matched column. Additionally, basic arithmetic operators (+,-,*,/) can be used with prec. For example, if Precision="prec+5" is defined, it will be replaced with the precision of the matched column plus 5.
This parameter requires parameter Datatype.
Scale
Argument: attr_val
Description: Integer scale in the database if this differs from the value defined in the HVR_COLUMN repository table.
When used together with Name or DatatypeMatch parameters, keyword scale can be used and will be replaced by respective values of the matched column. Additionally, basic arithmetic operators (+,-,*,/) can be used with scale. For example, if Scale="scale*2" is defined, it will be replaced with the scale of the matched column times 2.
This parameter requires parameter Datatype.
Nullable
Description: Nullability in the database if this differs from the value defined in the HVR_COLUMN repository table.
This parameter requires parameter Datatype.
Context
Argument: context
Description: Action ColumnProperties is effective/applied only if the context matches the context defined in Compare or Refresh. For more information about using Context, see our concept page Refresh or Compare context.
The value should be a context name, specified as a lowercase identifier. It can also have form !context, which means that the action is effective unless the matching context is enabled for Compare or Refresh.
One or more contexts can be enabled for Compare and Refresh.
Defining an action that is only effective when a context is enabled can have different uses. For example, if action ColumnProperties is defined with parameters IgnoreDuringCompare, Context=qqq , then normally all data will be compared, but if context qqq is enabled (-Cqqq), then the values in one column will be ignored.
Columns Which Are Not Enrolled In Channel
Normally all columns in the location's table (the 'base table') are enrolled in the channel definition. But if there are extra columns in the base table (either in the capture or the integrate database) which are not mentioned in the table's column information of the channel, then these can be handled in two ways:
They can be included in the channel definition by adding action ColumnProperties with parameter Extra to the specific location. In this case, the SQL statements used by HVR integrate jobs will supply values for these columns; they will either use the parameter IntegrateExpression or if that is not defined, then a default value will be added for these columns (NULL for nullable data types, or 0 for numeric data types, or '' for strings).
These columns can just not be enrolled in the channel definition. The SQL that HVR uses for making changes will then not mention these 'unenrolled' columns. This means that they should be nullable or have a default defined; otherwise, when HVR does an insert it will cause an error. These 'unenrolled' extra columns are supported during Integrate, Refresh, and Compare, but are not supported for Capture. If an 'unenrolled' column exists in the base table with a default clause, then this default clause will normally be respected by HVR, but it will be ignored during Bulk Refresh on Ingres, or SQL Server unless the column is a 'computed' column.
Substituting Column Values Into Expressions
HVR has different actions that allow column values to be used in SQL expressions, either to map column names or to do SQL restrictions. Column values can be used in these expressions by enclosing the column name in braces, for example, a restriction "{price} > 1000" means only rows where the value in price column is higher than 1000.
In some cases, it may be unclear which column names should be used in the braces. Consider the following scenario:
Suppose you are replicating a source base table with three columns (A, B, C) to a target base table with just two columns named (E, F). These columns will be mapped together using action ColumnProperties defined with parameter CaptureExpression or IntegrateExpression.
- If these mapping expressions are defined on the target side, then the table would be enrolled in the HVR channel with the source columns (A, B, C).
- If these mapping expressions are defined on the source side, then the table would be enrolled with the target columns (D, E).
Theoretically, mapping expressions could be put on both the source and target, in which case the columns enrolled in the channel could be different from both, (e.g., F, G, H), but this is unlikely. But when an expression is being defined for this table, should the source column names be used for the brace substitution (e.g., {A} or {B})? Or should the target parameter be used (e.g., {D} or {E})? The answer is that this depends on which parameter is being used and it depends on whether the SQL expression is being put on the source or the target side.
For parameters IntegrateExpression and IntegrateCondition (in action Restrict), the SQL expressions can only contain {} substitutions with the column names as they are enrolled in the channel definition (the "HVR Column names"), not the "base table's" column names (e.g., the list of column names in the target or source base table). So in the example above substitutions {A}, {B}, and {C} could be used if the table was enrolled with the columns of the source and with mappings on the target side, whereas substitutions {E} and {F} are available if the table was enrolled with the target columns and had mappings on the source.
But for parameters CaptureExpression, CaptureCondition (in action Restrict), and RefreshCondition (in action Restrict) the opposite applies: these expressions must use the "base table's" column names, not the "HVR column names". So in the example these parameters could use {A}, {B}, and {C} as substitutions in expressions on the source side, but substitutions {E} and {F} in expressions on the target.
Timestamp Substitution Format Specifier
Timestamp substitution format specifiers allows explicit control of the format applied when substituting a timestamp value. These specifiers can be used with {hvr_cap_tstamp[spec]}, {hvr_integ_tstamp[spec]}, and {colname [spec]} if colname has timestamp data type. The components that can be used in a timestamp format specifier spec are:
| Component | Description | Example |
|---|---|---|
| %a | Abbreviate weekday according to current locale. | Wed |
| %b | Abbreviate month name according to current locale. | Jan |
| %d | Day of month as a decimal number (01–31). | 07 |
| %H | Hour as number using a 24–hour clock (00–23). | 17 |
| %j | Day of year as a decimal number (001–366). | 008 |
| %m | Month as a decimal number (01 to 12). | 04 |
| %M | Minute as a decimal number (00 to 59). | 58 |
| %s | Seconds since epoch (1970–01–01 00:00:00 UTC). | 1099928130 |
| %S | Second (range 00 to 61). | 40 |
| %T | Time in 24–hour notation (%H:%M:%S). | 17:58:40 |
| %U | Week of year as decimal number, with Sunday as first day of week (00 – 53). | 30 |
%V Linux | The ISO 8601 week number, range 01 to 53, where week 1 is the first week that has at least 4 days in the new year. | 15 |
| %w | Weekday as decimal number (0 – 6; Sunday is 0). | 6 |
| %W | Week of year as decimal number, with Monday as first day of week (00 – 53) | 25 |
| %y | Year without century. | 14 |
| %Y | Year including the century. | 2014 |
| %[localtime] | Perform timestamp substitution using machine local time (not UTC). This component should be at the start of the specifier (for example, {{hvr_cap_tstamp %[localtime]%H}}). | |
| %[utc] | Perform timestamp substitution using UTC (not local time). This component should be at the start of the specifier (for example, {{hvr_cap_tstamp %[utc]%T}}). |
set