Quick Start for HVR - Kafka
This quick start guide helps you to get started with HVR for replicating data into Kafka.
To proceed with this replication you must have basic understanding about HVR's architecture and terminologies like Hub, Location, Channel, Location Groups, Actions etc.
The example here demonstrates how to replicate tables from one Oracle schema (source location) to two Kafka locations (target locations) - one with JSON format messages and other with Confluent's Schema Registry as its 'micro' AVRO format..
Before proceeding with this example ensure that the requirements for using HVR with Oracle and Kafka are met.
For information about access privileges and advanced configuration changes required for performing replication using Oracle and Kafka, see:
Create Test Schema and Tables
Create Source Schema
create user sourcedb identified by hvr default tablespace users temporary tablespace temp quota unlimited on users;
Create Tables in Source Schema
create table sourcedb.dm51_product ( prod_id number(10) not null, prod_price number(10,2) not null, prod_descrip varchar2(100) not null, primary key (prod_id) );
create table sourcedb.dm51_order ( prod_id number(10) not null, ord_id number(10) not null, cust_name varchar2(100) not null, cust_addr varchar2(100), primary key (prod_id, ord_id) );
Insert Values in Source Tables
insert into sourcedb.dm51_product values (100, 90, 'Book');
insert into sourcedb.dm51_order values (100, 123, 'Customer1', 'P.O. Box 122, Anytown, Anycountry');
Create the Hub Database
This section describes how to create a hub database (schema). The hub database is a repository database that HVR uses to control its replication activities. It contains HVR catalog tables that hold all specifications of replication such as the names of the replicated databases, the replication direction and the list of tables to be replicated. For more information about HVR hub server and database, see section Hub Server in System Requirements.
HVR supports the creation of a hub database on certain databases (location classes) only. For the list of supported location classes, see section Hub Database in Capabilities.
For this demonstration, the hub database (e.g. hvrhub) is created in Oracle.
Create the hub database (hvrhub) with password (hvr).
create user hvrhub identified by hvr default tablespace users temporary tablespace temp quota unlimited on users;
Download and Install HVR
An HVR distribution is available for download at the Fivetran.com website. For more information, see Downloading HVR.
Install HVR on a hub machine. For details on installing HVR, see the respective operating system sections:
The HVR distribution requires a license key in order for the software to operate. Please see the HVR licensing page for more details on how to install the HVR license.
After the installation, you can control HVR using the HVR graphical user interface (HVR GUI).
- If the hub machine is Windows, then HVR GUI can be executed directly on the hub machine.
- To control HVR remotely from your PC, connect to the hub machine using Windows Remote Desktop Connection and launch HVR GUI on the hub machine.
- If the hub machine is Linux, then HVR GUI can be executed directly on the hub machine. However, an application like X Server or VNC viewer must be installed to run HVR GUI directly on Linux.
- To control HVR remotely from your PC, install HVR on the PC (with Windows or macOS) and configure the HVR Remote Listener on the hub machine.
- If the hub machine is Unix, then HVR GUI should typically be run remotely from a PC to control HVR installed on the hub machine. To do this, install HVR on the PC (with Windows or macOS) and configure the HVR Remote Listener on the hub machine.
The HVR Remote Listener allows you to connect HVR GUI available on your PC to the remote HVR hub machine. For more information about connecting to remote HVR installation, see Configuring Remote Installation of HVR on Unix or Linux and Configuring Remote Installation of HVR on Windows.
Launch HVR GUI
This section describes how to launch HVR GUI on various operating systems.
On Windows and macOS, double-click the HVR shortcut icon available on the desktop or execute command hvrgui in the CLI.
On Linux, double-click the hvrgui file available in the HVR_extracted_path/bin directory or execute command hvrgui in the CLI.
Linux requires applications like X server or VNC viewer to execute HVR GUI.
On Unix, HVR GUI is not supported. So, HVR GUI should be run on a remote PC (with Windows, Linux, or macOS) to control HVR installed on the Unix machine.
Register Hub
This section describes how to connect HVR GUI to the hub database.
When you launch HVR GUI for the first time, the Register Hub dialog is displayed automatically. The Register Hub dialog can also be accessed from menu File by selecting Register Hub. Skip steps 1 to 4 if you want to run HVR GUI directly on the hub machine.
Click Connect to HVR on remote machine.
To connect HVR GUI on a PC to a remote HVR hub machine, the HVR Remote Listener must be configured and running on the HVR hub machine.
Enter the name or IP address of the hub machine in the Node field (e.g. myserver).
Enter the port number (defined in the HVR Remote Listener of the hub machine) in the Port field (e.g. 4343).
Enter the Login (e.g. myserveradmin) and Password for the hub machine. By default, this is the operating system login credentials of the hub machine.
Select Oracle in the Class pane.
Specify Database Connection details.
- Enter the directory path in ORACLE_HOME. You can also click the browse button to select the directory path.
- Enter the Oracle System ID in ORACLE_SID or TNS credentials.
- Enter the user name of the hub database in User (e.g. hvrhub).
- Enter the password for the hub database in Password (e.g. hvr).
Click Connect.

Click Yes in the prompt dialog asking to create catalog tables in the hub database.
HVR displays this prompt when connecting to a hub database for the first time.
On connecting successfully to the hub database, the navigation tree pane displays the hub machine and the hub database. Location Configuration, Channel Definitions, and Scheduler are displayed under the hub database.
Create Locations
This section describes how to create locations in HVR GUI. A location is a storage place (for example, database or file storage) from where HVR captures (source location) or integrates (target location) changes.
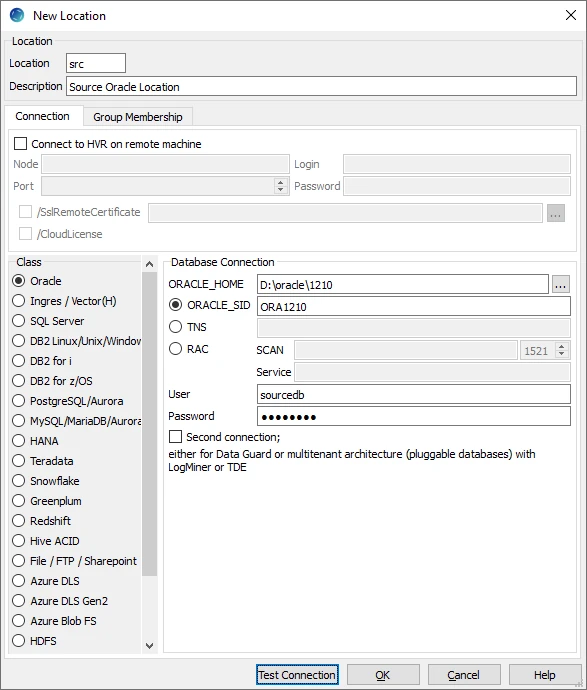
Create Oracle Location
- In navigation tree pane, right-click Location Configuration ▶ New Location.
- Enter Location name and Description for the location.
- Select Oracle in Class.
- Provide Database Connection details. For more information on Database Connection fields, see section Location Connection.
Enter directory path for ORACLE_HOME. You can also click browse to select directory path.
Enter Oracle System ID in ORACLE_SID or TNS credential or RAC credential.
For RAC connectivity, ensure to provide remote machine connection details under Connection tab.
Enter user name of schema in User. For example, sourcedb.
Enter password for schema in Password. For example, hvr.
- Click Test Connection to verify the connection to location database.
- Click OK.
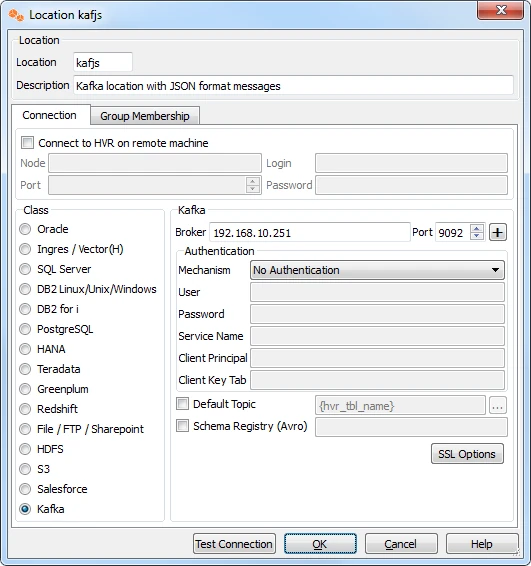
Create Kafka Locations
To create a Kafka location, right-click on Location Configuration ▶ New Location.
- HVR creates a Kafka location that sends messages in JSON format by default.
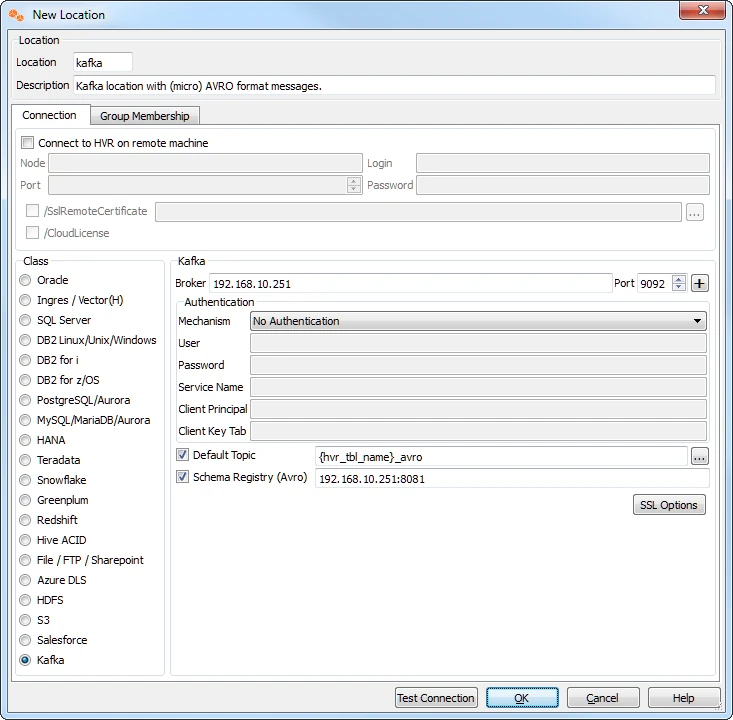
- To create a Kafka location that sends messages in (micro) AVRO format, select Schema Registry (Avro) and provide the URL for Schema Registry.
Create Channel
The next step is to create a channel. For a relational database, the channel represents a group of tables that is captured as a unit. To create a channel, perform the following procedure:
- Right-click on Channel Definitions ▶ New Channel.
- Enter a channel name (for example hvr_demo01).
- Click OK to create a channel.
Create Location Groups
The channel must have two location groups (for example SRC and KAFKA). Perform the following procedure to create a location group:
- Right-click the Location Groups ▶ New Group.
- Enter a group name (for example SRC).
- Select the location (for example src) to add it as a member of the group.
- Click OK to save.
To create the second location group: - Right-click the Location Groups ▶ New Group.
- Enter a group name (for example KAFKA).
- Select the location (for example kafjs and kafav) to add it as a member of the group.
- Click OK to save.
Create Tables
The new channel also needs a list of tables to replicate. Perform the following procedure to create tables:
- Right-click on Tables ▶ Table Explore.
- Choose the database location and click Connect.
- In the Table Explore window, select the table(s) and click Add.
- In new dialog HVR Table Name click OK.
- Close the Table Explore window.
Define Actions
The new channel needs actions to define the replication. To define actions:
- Right-click on group SRC ▶ New Action ▶ Capture.
- Right-click on group KAFKA ▶ New Action ▶ Integrate.
- Select /Topic=Test
- Right-click on group KAFKA ▶ New Action ▶ ColumnProperties.
- Select /Name=op_val.
- Select /Extra.
- Select /IntegrateExpression={hvr_op}.
- Select /Datatype=number.
- Click OK to save and close the New Action window.
- Right-click on group KAFKA ▶ New Action ▶ ColumnProperties.
- Select /Name=integ_seq.
- Select /Extra.
- Select /IntegrateExpression={hvr_integ_seq}.
- Select /Timekey.
- Select /Datatype=varchar.
- Select /Length=32
- Click OK to save and close the New Action window.
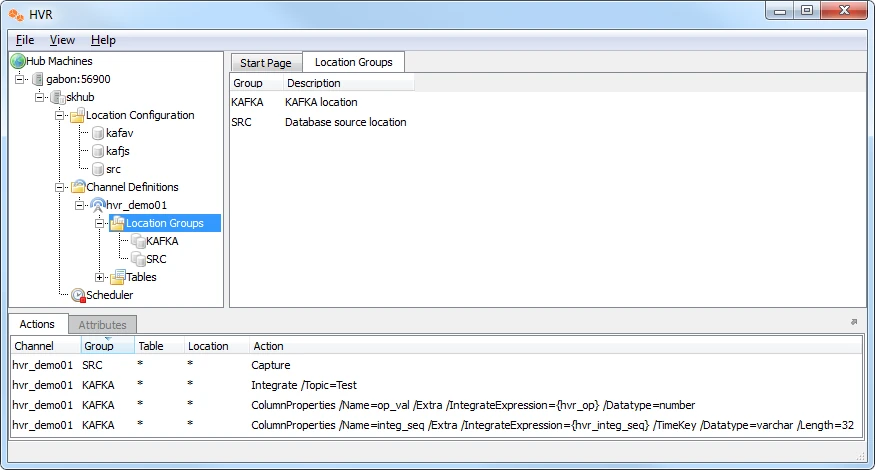
Note that the Actions pane only displays actions related to the object selected in the left–hand pane. So click on channel hvr_demo01 to see both actions.
Initialize
Now that the channel definition is complete, proceed to create the runtime replication system with HVR initialize.
- Right-click on channel hvr_demo01 ▶ HVR Initialize.
- Select Create or Replace Objects.
- Click Initialize.
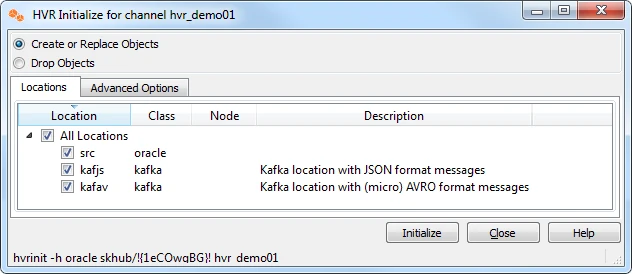
After initializing the channel hvr_demo01, all new transactions that start on the database testdb1 will be captured by HVR (when its capture job looks inside the transaction logs).
HVR Initialize also creates two replication jobs under the Schedulernode.
Start Scheduler and Capture Job
Next, perform the following procedure to start scheduling of the capture job:
- Right-click the Scheduler node of the hub database.
- Click Start to start the scheduler.
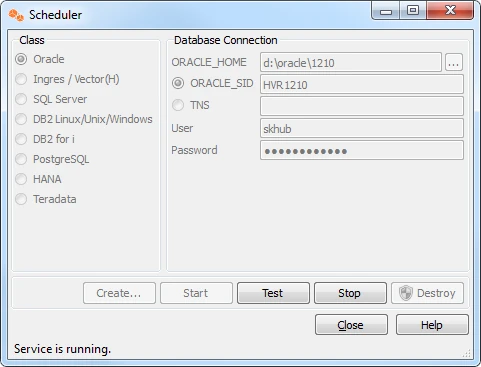
- Right-click the capture job group hvr_demo01-cap ▶ Start to start the capture job.
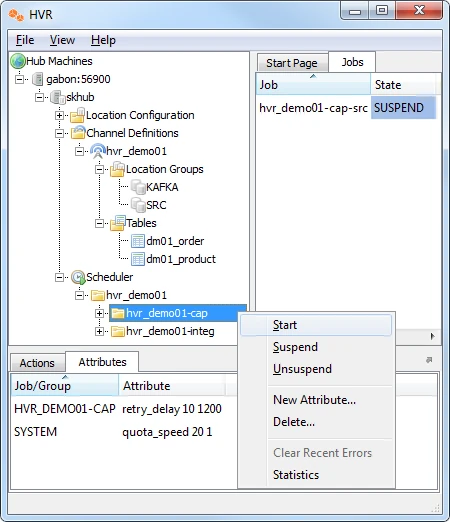
The capture job inside the Scheduler executes a script under $HVR_CONFIG/job/hvrhub/hvr_demo01 that has the same name as the job. So job hvr_demo01–cap–src detects changes on database testdb1 and stores these as transactions files on the hub machine.
Refresh
Perform the following procedure for the initial load from OLTP database into Kafka using HVR Refresh.
- Right-click the channel hvr_demo01 ▶ HVR Refresh.
- Select the target locations Kafav and Kafjs.
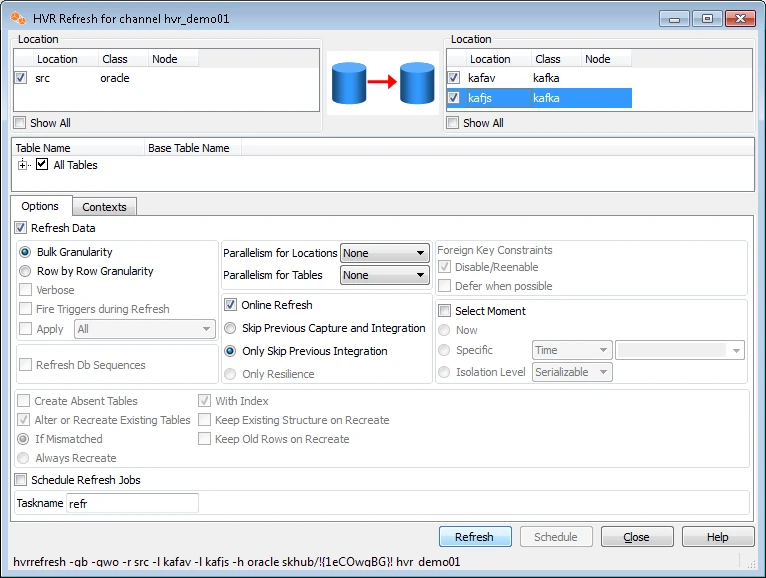
- You can optionally set Parallelism for Tables.
- Click Refresh to begin HVR Refresh.
Start Integrate Job
Perform the following procedure to unsuspend the integrate job in HVR Scheduler to push changes into Kafka according to the defined schedule.
- Right-click the integrate job group hvr_demo01-integ ▶ Unsuspend to resume the integrate job.
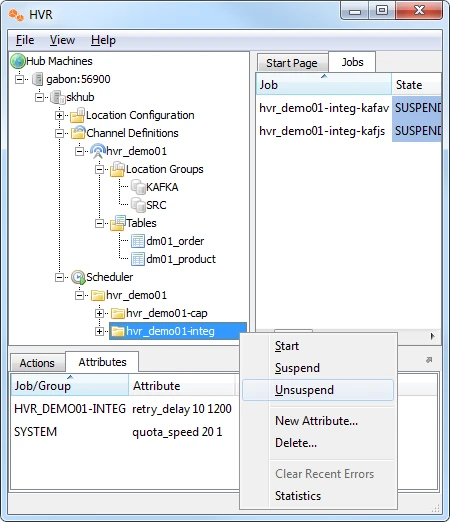
The integrate job inside the Scheduler executes a script under $HVR_CONFIG/job/hvrhub/hvr_demo01 that has the same name as the job. So the jobs hvr_demo01–integ-kafav and hvr_demo01–integ-kafjs pick up transaction files on the hub on a defined schedule and create files on Kafka containing these changes.
A scheduled job that is not running is in a PENDING state.