Architecture Overview
HVR supports a distributed architecture for database and file replication. HVR is a comprehensive software system that has all of the needed modules to run replication. This includes a mechanism called HVR Refresh for the initial loading of the database, a continuous capture process to acquire all the changes in the source location, an integrate (or apply) process that applies the changes to the target location, and a compare feature that compares the source and target locations to ensure that the data is the same on both sides. A location is a storage place (for example, database or file storage) from where HVR captures (source location) or integrates (target location) changes. Locations can be either local (i.e. residing on the same machine as the HVR hub) or remote (residing on a remote machine, other than the hub).
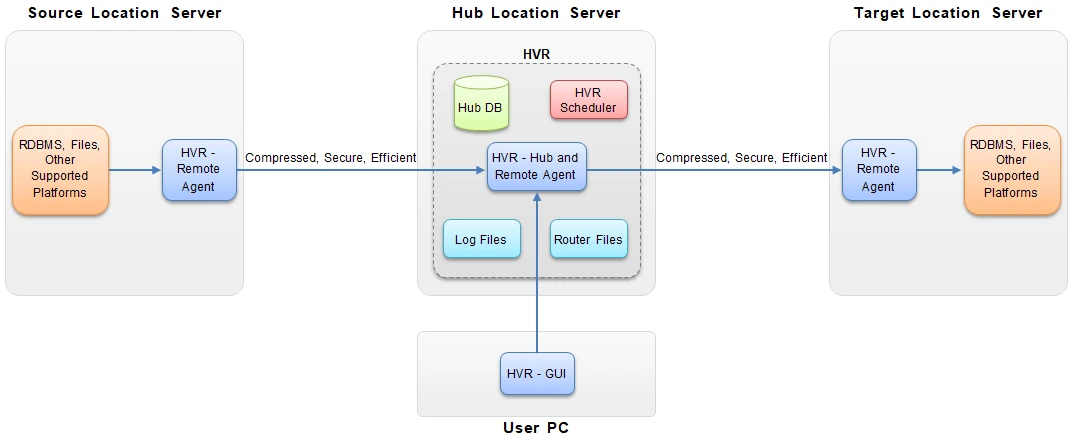
HVR software may be installed on the most commonly used operating systems. HVR reads the transaction logs of the source location(s) in real time. That data is then compressed, optionally encrypted, and sent to a 'hub machine'. The hub then routes the data and then integrates (applies) the data into the target location(s).
HVR Hub
The HVR hub is an installation of HVR on a server machine (hub server). The HVR hub orchestrates replication in logical entities called channels. A channel groups together locations and tables that are involved in the replication. It also contains actions that control the replication. The channel must contain at least two locations. The channel also contains location groups - one for the source location(s) and one for the target location(s). Location groups are used for defining actions on the locations. Each location group can contain multiple locations.
The hub machine contains the HVR hub database, Scheduler, Log Files, and Router Files.
Hub Database
This is a database which HVR uses to control replication between source and target locations. For the list of databases that HVR supports as a hub database, see section Hub Database in Capabilities. The hub database contains HVR catalog tables that hold all specifications of replication such as the names of replicated databases, replication direction and the list of tables to be replicated.
HVR Scheduler
The hub runs an HVR Scheduler service to manage replication jobs (Capture jobs, Integrate jobs, Refresh jobs, Compare jobs) that move data flow between source location(s) and target location(s). To either capture or apply (integrate) changes, the HVR Scheduler on the hub machine starts the capture and integrate jobs that connect out to source and target locations.
Log Files
Log files are files that HVR creates internally to store information from scheduled jobs (like Capture jobs, Integrate jobs, Refresh jobs, Compare jobs) containing a record of all events such as transport, routing and integration.
Router Files
Router files are files that HVR creates internally on the hub machine to store a history of what HVR captured and submitted for integration, including information about timestamps and states of the capture and integrate jobs, transactions, channel locations and tables, instructions for a replication job, etc.
HVR Remote Agent
Any installation of the HVR software can play the role of the HVR hub and/or an HVR remote agent. The HVR remote agent is an installation of the HVR software on a remote source and/or target machine that allows to implement a distributed setup. The HVR hub can also be configured to work as a HVR remote agent to enable the HVR GUI on a user's PC to connect to the HVR hub.
The HVR remote agent is quite passive and acts as a child process for the hub machine. Replication is entirely controlled by the hub machine.
Even though HVR recommends using HVR remote agent with the distributed setup, HVR can also support an agent-less architecture.
To access a remote location, the HVR hub normally connects to the HVR remote agent using a special TCP/IP port number.
- If the remote machine is Unix or Linux, then the system process (daemon) is configured on the remote machine to listen on this TCP/IP port. For more information, refer to section Configuring Remote Installation of HVR on Unix or Linux.
- If the remote machine is a Windows machine, then HVR listens using HVR Remote Listener (a Windows service). For more information, refer to section Configuring Remote Installation of HVR on Windows.
Alternatively, HVR can connect to a remote database location using a DBMS protocol such as Oracle TNS.
HVR GUI
HVR can be managed using a Graphical User Interface (GUI). The HVR GUI can run directly on the hub machine if the hub machine is Windows or Linux.
Otherwise, it should be run on the user's PC and connect to the remote hub machine. In this case, the HVR installation on the hub machine will play dual role:
- Works as an HVR hub which will connect to the HVR remote agent available on the source and target locations.
- Works as an HVR remote agent to enable the HVR GUI on the user's PC to connect to the HVR hub.
HVR Refresh
The HVR Refresh feature allows users to initially load data directly from source tables to target tables or files. To perform the initial materialization of tables, users simply create target tables based on the source layouts, and then move the data from the source tables to the target. HVR provides built-in performance options to help reduce the time it takes to initially load the tables. HVR can run jobs in parallel, either by table or location. For large tables, you can instruct HVR to slice the data into data ranges for improved parallelism. Behind the scenes, HVR further improves initial load performance by using the native bulk load capabilities of the database vendor, which typically offer the most efficient way to load the data without requiring HVR users to configure utilities or write scripts.
HVR Compare
The HVR Compare feature ensures that the source and target locations are both 100% the same. HVR has two methods of comparing data: bulk and row by row. During the bulk compare, HVR calculates the checksum for each table in the channel and compares these checksums to report whether the replicated tables are identical. During the row by row compare, HVR extracts data from a source (read) location, compresses it, and transfers the data to a target (write) location(s) to perform the row by row compare. Each individual row is compared to produce a 'diff' result. HVR also has a repair feature. For each difference detected, an SQL statement is written: an insert, update or delete. This SQL statement can then be executed to repair so that the source and targets are the same. For large tables, you can instruct HVR to slice the data into data ranges for improved parallelism.