Hvrcompare
Name
hvrcompare - Compare data in tables.
Synopsis
hvrcompare [-options] hubdb chn
Description
Command hvrcompare compares the data in different locations of channel chn. The locations must be databases, not file locations.
The argument hubdb specifies the connection to the hub database. For more information about supported hub databases and the syntax for using this argument, see Calling HVR on the Command Line.
HVR Compare Granularity
Table compare can be performed as a bulk or row-by-row operation, depending on the option -g supplied with command hvrcompare.
Bulk Compare
During bulk compare, HVR calculates the checksum for each table in the channel and compares this checksum to report whether the replicated tables are identical.
Row by Row Compare
During row by row compare, HVR extracts the data from a source (read) location, compresses it, and transfers the data to a target (write) location(s) to perform row by row compare. Each individual row is compared to produce a 'diff' result. For each difference detected an SQL statement is written: an insert, update or delete.
If hvrcompare is connecting between different DBMS types, then an ambiguity can occur because of certain data type coercions. For example, HVR's coercion maps an empty string from other DBMS's into a null in an Oracle varchar. If Ingres location ing contains an empty string and Oracle location ora contains a null, then should HVR report that these tables are the same or different? Command hvrcompare allows both behaviors by applying the sensitivity of the 'write' location, not the 'read' location specified by option -r. This means that comparing from location ing to location ora will report the tables as identical, but comparing from ora to ing will say the tables are different.
Options
This section describes the options available for command hvrcompare.
| Parameter | Description | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
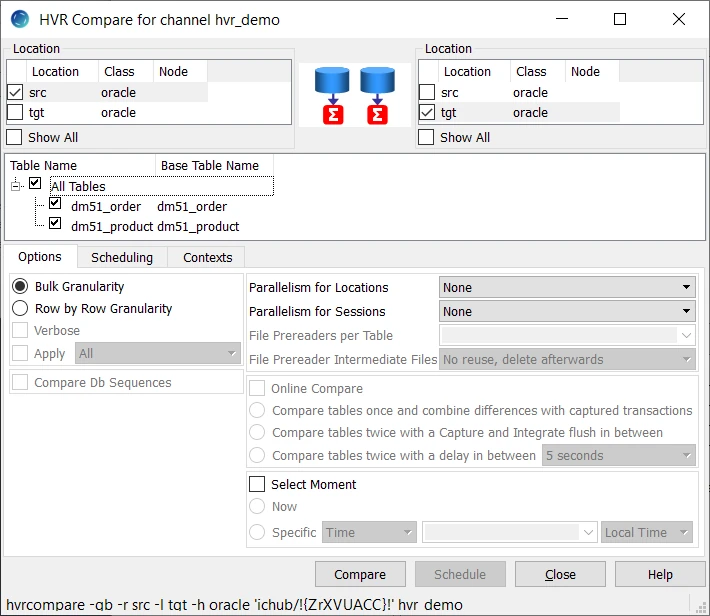
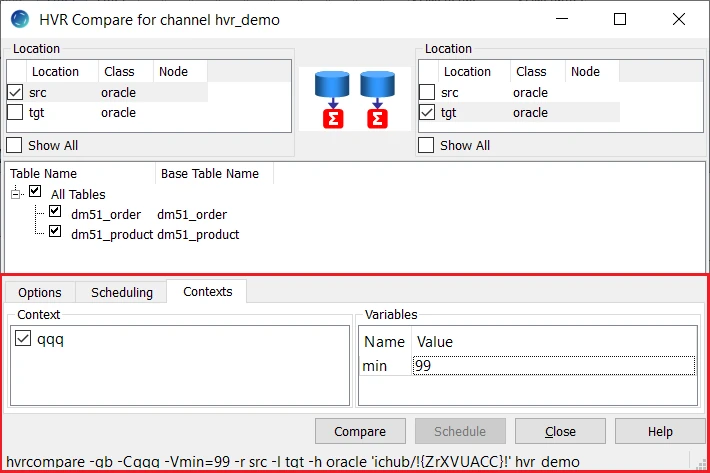
| -Ccontext | Enable context. This controls whether actions defined with parameter Context are effective or are ignored. Defining an action with Context can have different uses. For example, if action Restrict /CompareCondition="{id}>22" /Context=qqq is defined, then normally all data will be compared, but if context qqq is enabled (-Cqqq), then only rows where id>22 will be compared. Variables can also be used in the restrict condition, such as "{id}>{hvr_var_min}". This means that hvrcompare -Cqqq -Vmin=99 will compare only rows with id>99. To supply variables for restrict condition use option -V. Parameter /Context can also be defined on action ColumnProperties. This can be used to define /CaptureExpression parameters which are only activated if a certain context is supplied. For example, to define a context for case-sensitive compares. Option -C corresponds to the Contexts tab in the HVR GUI.
| ||||||||||||
-DSince v5.5.5/6 | Duplicate an existing compare event. This option is used for repeating a compare operation, using the same arguments. | ||||||||||||
| -d | Remove (drop) scripts and scheduler jobs & job groups generated by the previous hvrcompare command. When this option is used with option -e it cancels (FAILED) events that are in a PENDING or RUNNING state. Since v5.5.5/6 | ||||||||||||
-e | Perform event-driven compare. In event-driven compare, the compare operation is managed using HVR's event system. For each compare operation performed, HVR maintains a record in the following catalog tables - hvr_event and hvr_event_result. In HVR GUI, the option to perform event-driven compare (Generate Compare Event) is available in the Scheduling tab. HVR creates a compare job in the HVR Scheduler and the compare operation is started under a compare event. While performing event-driven compare, if a compare event with the same job name exists in a PENDING or RUNNING state then it is automatically canceled (FAILED) by the new compare event. The results for event-driven compare are displayed in Insight Events. In HVR GUI, by default, the event-driven compare is scheduled to Start Immediately. In CLI, to start the event-driven compare immediately, execute the command hvrstart immediately after executing the command for event-driven compare. This option is also required to run the following compare operations:
| ||||||||||||
| -gx | Granularity of compare operation in database locations. Valid values of x are:
| ||||||||||||
| -hclass | Location class of the hub database. Valid values for class are db2, db2i, ingres, mysql, oracle, postgresql, sqlserver, or teradata. For more information, see Calling HVR on the Command Line. | ||||||||||||
-ixSince v5.6.5/0 | Retain and reuse intermediate files. This option allows you to retain the intermediate files that are generated during a direct file compare. It also allows you to reuse the retained intermediate files that were generated earlier by a similar compare. A compare is similar if the location, channel, tables, and Restrict /SliceCondition (if any) are identical. In HVR GUI, the default value for this option (File Prereader Intermediate Files) is No reuse, delete afterwards. This option is applicable only for direct file compare. Valid values of x are:
| ||||||||||||
-IsrangeSince v5.5.5/6 | Compare event only perform subset of slices implied by -S (table slices) option. This option is only allowed with options -e and -S. Value srange should be a comma-separated list of one of the following:
| ||||||||||||
-jnum_jobsSince v5.3.1/6 | Sets quota_run compare job group attribute. It defines a number of jobs that can be run simultaneously. The option cannot be used without scheduling turned on (-s) | ||||||||||||
| -lx | Target location of compare. The other (read location) is specified with option -r. If this option is not supplied then all locations except the read location are targets. Values of x maybe one of the following:
| ||||||||||||
| -mmask | Mask (ignore) some differences between the tables that are being compared. Valid values of mask can be:
| ||||||||||||
| -Mmoment | Select data from each table of source from same consistent moment in time. Value moment can be one of the following:
| ||||||||||||
-nnumtabsSince v5.3.1/6 | Create 'sub-jobs' which each compare a bundle of no more than numtabs tables. In HVR GUI, this option is displayed as Limit Tables per Job in the Scheduling tab. For example, if a channel contains 6 tables then option -n1 will create 6 jobs whereas were option -n4 to be used on the same channel then only 2 jobs will be created (the first with 4 tables, the last with just 2). If tables are excluded (using option -t) then these will not count for the bundling. Jobs are named by adding a number (starting at 0) to the task name which defaults cmp (although the task name can always be overridden using option -T). Normally the first slice's job is named chn-cmp0-x-y but numbers are left-padded with zeros, so if 10 slices are needed the first is named chn-cmp00-x-y instead. One technique is to generate lots of jobs for compare of a big channel (using this option and option -s) and add 'scheduler attribute' quota_run to the job group (named CHN-CMP) so that only a few (say 3) can run simultaneously. Scheduler attributes can be added by right-clicking on the job group and selecting Add Attribute. Another technique to manage the compare of a channel with thousands of tables is to use this option along with options -R (ranges) and -T (task name) to do 'power of ten' naming and bundling, in case a single table encounters a problem. The following illustrates this technique; First use [-n100] so each job tries to compare 100 tables. If one of these jobs fails (say job chn-cmp03-x-y) then use options [-n10 -R30-39 -Tcmp03] to replace it with 10 jobs which each do 10 tables. Finally if one of those jobs fails (say chn-cmp037-x-y) then use options [-n1 -R370-379 -Tcmp037] to replace it with 10 'single table' jobs. | ||||||||||||
-NsecsSince v5.5.5/8 | Compare tables twice with a delay in between. In CLI, this option can only be used along with option -o diff_diff. Capture and Integrate jobs are not required for performing this mode of online compare. This online compare mode is similar to Compare tables twice with a Capture and Integrate flush in between (option -o diff_diff) however, with one difference. HVR performs a regular compare which produces a result (also known as diff). HVR then waits for secs seconds after which it again performs the regular compare which produces a second result (diff). The compare results generated in the first and second compare are combined to produce a final compare result. Example: hvrcompare -gr -o diff_diff -N 5 -e -r src -l tgt -h oracle 'myhub/myhub' mychannel | ||||||||||||
-omode | Online compare. Performs live compare between locations where data is rapidly changing. This option can only be used if Row by Row Granularity (option -gr) and Generate Compare Event (option -e) is selected (or supplied). The results of the online compare are displayed in Insight Events. Value mode can be either:
| ||||||||||||
-OSince v5.3.1/6 | Only show OS command implied by options -n (jobs for bundles of tables) or -S (table slices), instead of executing them. This can be used to generate a shell script of 'simpler' hvrcompare commands; For example, if a channel only contains tables tab1, tab2, tab3, and tab4 then this command;
| ||||||||||||
| -pN | Parallelism for Locations. Perform compare on different locations in parallel using N sub-processes. This cannot be used with option -s. | ||||||||||||
| -PM | Parallelism for Sessions. Perform compare for different tables in parallel using M sub-processes. The compare will start processing M tables in parallel; when the first of these is finished the next table will be processed, and so on. | ||||||||||||
| -Q | No compare of database sequences matched by action DbSequence. If this option is not specified, then the database sequence in the source database will be compared with matching sequences in the target database. Sequences that only exist in the target database are ignored. | ||||||||||||
| -rloc | Read location. This means that location loc is passive; the data is piped from here to the other location(s) and the work of comparing the data is performed there instead. | ||||||||||||
-RrangeexprSince v5.3.1/6 | Only perform certain 'sub jobs' implied by either options -N (job for bundles of tables) or -S (table slices). This option cannot be used without one of those options. Value rangeexpr should be a comma-separated list of one of the following:
| ||||||||||||
| -s | Schedule invocation of compare scripts using the HVR Scheduler. In HVR GUI, this option is displayed as Schedule Classic Job in the Scheduling tab. Without this option the default behavior is to perform the compare immediately (in HVR GUI, Run Interactively). This option creates compare job for comparing the tables. By default, this compare job is created in SUSPEND state and they are named chn-cmp-source-target. This compare job can be invoked using command Hvrstart as in the following example:
Once a compare job has been created with option -s then it can also be run manually on the command line (without using HVR Scheduler) as follows:
 | ||||||||||||
-Ssliceexpr | Compare large tables using slicing. Value sliceexpr can be used to split table into multiple slices. In HVR GUI, this option is displayed as Slice Table in the Scheduling tab.
If performing Schedule Classic Job (option -s), per slice a compare job is created for comparing only rows contained in the slice. These compare jobs can be run in parallel to improve the overall speed of the compare. Slicing can only be used for a single table (defined with option -t). If performing an event driven compare - Generate Compare Event (option -e), only a single compare job is created for all slices. If performing event-driven compare (option -e), multiple tables can be sliced simultaneously (same job) by supplying the table name with the sliceexpr. The format is tablename.sliceexpr. As with option -n (bundles of tables), jobs are named by adding a number (starting at 0) to the task name which defaults cmp (although this task name can always be overridden using option -T). Normally the first slice's job is named chn-cmp0-source-target but numbers are left-padded with zeros, so if 10 slices are needed the first is named chn-cmp00-source-target instead. The column used to slice a table must be 'stable', because if it is updated then a row could 'move' from one slice to another while the compare is running. The row could be compared in two slices (which will cause errors) or no slices (data-loss). If the source database is Oracle then this problem can be avoided using a common Select Moment (option -M). For more information on slicing limitations, see section Slicing Limitations below. Value sliceexpr must have one of the following forms:
| ||||||||||||
| -ty | Only compare tables specified by y. Values of y may be one of the following:
| ||||||||||||
| -Ttsk | Specify an alternative name for a compare task used for naming scripts and jobs. The task name must start with a 'c'. The default task name is cmp, so without option -T, compare jobs are named chn-cmp-l1-l2. | ||||||||||||
| -uuser[/pwd] | Connect to hub database using DBMS account user. For some databases (e.g. SQL Server) a password must also be supplied. | ||||||||||||
-v | Verbose. This causes row-wise compare to display each difference detected. Differences are presented as SQL statements. This option requires that option -gr (row-wise granularity) is supplied. This option creates binary diff files containing individual differences detected. The diff files can be viewed using command hvrrouterview. Section Analyzing Diff File explains how to view and interpret the contents of a diff file. | ||||||||||||
| -Vnm=val | Supply variable for restrict condition. This should be supplied if a Restrict /CompareCondition parameter contains string {hvr_var_name}. This string is replaced with val. In HVR GUI, the option to supply variable for restrict condition is available under Contexts tab. | ||||||||||||
-wNSince v5.5.5/6 | File prereaders per table. Define the number of prereader subtasks per table while performing direct file compare. This option is only allowed if the source or target is a file location. |
Direct File Compare
Since v5.5.5/6
A direct file compare is a compare performed against a file location. This compare method is a faster alternative for file compare via Hive External Tables and also helps to avoid compare mismatches caused by data type coercion through Hive deserializer.
During direct file compare, HVR reads and parses (deserialize) files directly from the file location instead of using the HIVE external tables (even if it is configured for that location). In direct file compare, the files of each table are sliced and distributed to prereader sub tasks. Each prereader subtasks reads, sorts and parses (deserialize) the files to generate compressed(encrypted) intermediate files. These intermediate files are then compared with the database on the other side.
- The number of prereader subtasks used during direct file compare can be configured using the compare option -w.
- The location to store the intermediate files generated during compare can be configured using LocationProperties /IntermediateDirectory.
To perform a direct file compare:
- against a source file location, Capture /Pattern should be defined.
- against a target file location, Integrate /ComparePattern should be defined.
Limitations
Direct file compare does not support Avro, Parquet or JSON file formats.
Direct file compare is not supported if Restrict /RefreshCondition is defined on a file location involved in the compare.
Direct file compare is not supported when the channel is a 'blob' file channel. A blob file channel has no table information and simply treats each file as a sequence of bytes without understanding their file format.
Direct file compare for XML files requires each XML file to contain a single table.
Slicing Limitations
This section lists the limitations of slicing when using hvrcompare.
Modulo
Following are the limitations when using slicing with modulo of numbers (col%num):
- Only works on numeric data types. It may work with binary float values depending on DBMS data type handling (e.g. works on MySQL but not on PostgreSQL).
- A diverse Modulo syntax on source and target (e.g. “where col%5=2” and “where mod(col,5)=2”) may produce inaccurate results. This limitation applies only to classic compare and refresh. Since HVR 5.5.5/6, the event-driven compare can handle it.
- Heterogeneous compare (between different DBMSes or file locations) has a limitation with Modulo slicing on the Oracle’s NUMBER(*) column: if a value has an exponent larger than 37 (e.g. if a number is larger than 1E+37 or smaller than -1E+37), then this row might be associated with a wrong slice. This column should not be used for Modulo slicing. (The exact limits of the values depend on the number of slices).
- For some supported DBMSes (SQL Server, PostgreSQL, Greenplum, Redshift), Modulo slicing on a float column is not allowed (may result in SQL query error).
- For some DBMSes, float values above the limits of DBMS’s underlying precision ("big float values") may produce inaccurate results during Modulo slicing. This affects only heterogeneous environments.
- Compare with Modulo slicing on a column with "big float values" may produce inaccurate results in HANA even in a homogeneous environment (HANA-to-HANA).
A workaround for the above limitations is to use Boundaries slicing or Count slicing with custom SQL expressions.
Boundaries
Boundaries slicing of dates does not work in heterogeneous DBMSes.
Slicing with Direct File Compare
An Oracle’s NUMBER(*) column or a similar column with big numbers (namely, if a number is larger than 1E+37 or smaller than -1E+37) cannot be used in direct file compare with slicing. A workaround is to use another column for slicing.
Examples
By default, HVR performs bulk compare. It is not required to explicitly define option -gb.
Example command to compare all tables in locations src and tgt:
hvrcompare -rsrc -ltgt myhub/myhubpasswd mychannelExample command to compare table order in location src and location tgt:
hvrcompare -rsrc -ltgt -torder myhub/myhubpasswd mychannel
Files