Recurly dbt package (Docs)
![]()
![]()
![]()
![]()
What does this dbt package do?
Produces modeled tables that leverage Recurly data from Fivetran's connector in the format described by this ERD and build off the output of our Recurly source package.
Enables you to better understand your Recurly data. The package achieves this by performing the following:
- Enhance the balance transaction entries with useful fields from related tables.
- Create customized analysis tables to examine churn by subscriptions and monthly recurring revenue by account.
- Generate a metrics table that allows you to better understand your account activity over time or at a customer level. These time-based metrics are available on a daily level.
Generates a comprehensive data dictionary of your source and modeled Recurly data through the dbt docs site.
The following table provides a detailed list of all tables materialized within this package by default.
TIP: See more details about these tables in the package's dbt docs site.
| Table | Description |
|---|---|
| recurly__account_daily_overview | Each record is a day in an account and its accumulated balance totals based on all line item transactions up to that day. |
| recurly__account_overview | Each record represents an account, enriched with metrics about their associated transactions. |
| recurly__balance_transactions | Each record represents a specific line item charge, credit, or other balance change that accumulates into the final invoices. |
| recurly__churn_analysis | Each record represents a subscription and their churn status and details. |
| recurly__monthly_recurring_revenue | Each record represents an account and MRR generated on a monthly basis. |
| recurly__subscription_overview | Each record represents a subscription, enriched with metrics about time, revenue, state, and period. |
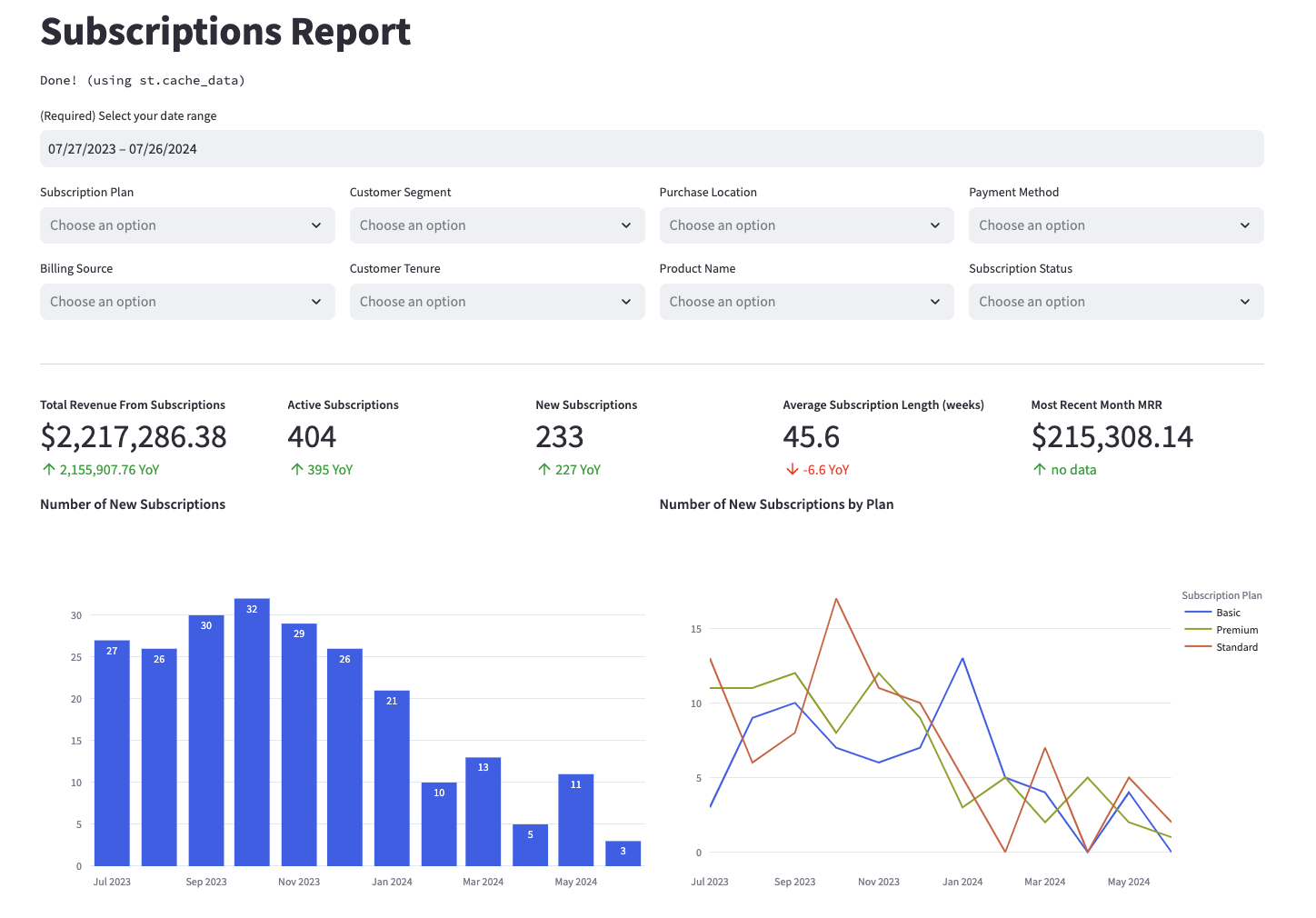
| recurly__line_item_enhanced | This model constructs a comprehensive, denormalized analytical table that enables reporting on key revenue, subscription, customer, and product metrics from your billing platform. It’s designed to align with the schema of the *__line_item_enhanced model found in Recurly, Recharge, Stripe, Shopify, and Zuora, offering standardized reporting across various billing platforms. To see the kinds of insights this model can generate, explore example visualizations in the Fivetran Billing Model Streamlit App. Visit the app for more details. |
Example Visualizations
Curious what these models can do? Check out example visualizations from the recurly__line_item_enhanced model in the Fivetran Billing Model Streamlit App, and see how you can use these models in your own reporting. Below is a screenshot of an example report—explore the app for more.
Materialized Models
Each Quickstart transformation job run materializes 47 models if all components of this data model are enabled. This count includes all staging, intermediate, and final models materialized as view, table, or incremental.
How do I use the dbt package?
Step 1: Prerequisites
To use this dbt package, you must have the following:
- At least one Fivetran Recurly connection syncing data into your destination.
- A BigQuery, Snowflake, Redshift, PostgreSQL, Databricks destination.
Databricks Dispatch Configuration
If you are using a Databricks destination with this package you will need to add the below (or a variation of the below) dispatch configuration within your dbt_project.yml. This is required for the package to accurately search for macros within the dbt-labs/spark_utils then the dbt-labs/dbt_utils packages respectively.
dispatch: - macro_namespace: dbt_utils search_order: ['spark_utils', 'dbt_utils']
Step 2: Install the package
Include the following recurly package version in your packages.yml file.
TIP: Check dbt Hub for the latest installation instructions or read the dbt docs for more information on installing packages.
packages: - package: fivetran/recurly version: [">=1.2.0", "<1.3.0"]
All required sources and staging models are now bundled into this transformation package. Do not include
fivetran/recurly_sourcein yourpackages.ymlsince this package has been deprecated.
Step 3: Define database and schema variables
Option A: Single connection
By default, this package runs using your destination and the recurly schema. If this is not where your Recurly data is (for example, if your Recurly schema is named recurly_fivetran), add the following configuration to your root dbt_project.yml file:
vars: recurly: recurly_database: your_database_name recurly_schema: your_schema_name
Option B: Union multiple connections
If you have multiple Recurly connections in Fivetran and would like to use this package on all of them simultaneously, we have provided functionality to do so. For each source table, the package will union all of the data together and pass the unioned table into the transformations. The source_relation column in each model indicates the origin of each record.
To use this functionality, you will need to set the recurly_sources variable in your root dbt_project.yml file:
# dbt_project.yml vars: recurly: recurly_sources: - database: connection_1_destination_name # Required schema: connection_1_schema_name # Required name: connection_1_source_name # Required only if following the step in the following subsection - database: connection_2_destination_name schema: connection_2_schema_name name: connection_2_source_name
Recommended: Incorporate unioned sources into DAG
If you are running the package through Fivetran Transformations for dbt Core™, the below step is necessary in order to synchronize model runs with your Recurly connections. Alternatively, you may choose to run the package through Fivetran Quickstart, which would create separate sets of models for each Recurly source rather than one set of unioned models.
By default, this package defines one single-connection source, called recurly, which will be disabled if you are unioning multiple connections. This means that your DAG will not include your Recurly sources, though the package will run successfully.
To properly incorporate all of your Recurly connections into your project's DAG:
- Define each of your sources in a
.ymlfile in your project. Utilize the following template for thesource-level configurations, and, most importantly, copy and paste the table and column-level definitions from the package'ssrc_recurly.ymlfile.
# a .yml file in your root project version: 2 sources: - name:# ex: Should match name in recurly_sources schema: database: loader: fivetran config: loaded_at_field: _fivetran_synced freshness: # feel free to adjust to your liking warn_after: {count: 72, period: hour} error_after: {count: 168, period: hour} tables: # copy and paste from recurly/models/staging/src_recurly.yml - see https://support.atlassian.com/bitbucket-cloud/docs/yaml-anchors/ for how to use anchors to only do so once
Note: If there are source tables you do not have (see Step 4), you may still include them, as long as you have set the right variables to
False.
- Set the
has_defined_sourcesvariable (scoped to therecurlypackage) toTrue, like such:
# dbt_project.yml vars: recurly: has_defined_sources: true
Step 4: Disable models for non-existent sources
Your Recurly connection may not sync every table that this package expects. This might be because you are excluding those tables. If you are not using those tables, you can disable the corresponding functionality in the package by specifying the variable in your dbt_project.yml. By default, all packages are assumed to be true. You only have to add variables for tables you want to disable, like so:
vars: recurly__using_credit_payment_history: false # Disable if you do not have the credit_payment_history table recurly__using_subscription_add_on_history: false # Disable if you do not have the subscription_add_on_history table recurly__using_subscription_change_history: false # Disable if you do not have the subscription_change_history table
(Optional) Step 5: Additional configurations
Expand to view configurations
Enabling Standardized Billing Model
This package contains the recurly__line_item_enhanced model which constructs a comprehensive, denormalized analytical table that enables reporting on key revenue, subscription, customer, and product metrics from your billing platform. It’s designed to align with the schema of the *__line_item_enhanced model found in Recurly, Recharge, Stripe, Shopify, and Zuora, offering standardized reporting across various billing platforms. To see the kinds of insights this model can generate, explore example visualizations in the Fivetran Billing Model Streamlit App. This model is enabled by default. To disable it, set the recurly__standardized_billing_model_enabled variable to false in your dbt_project.yml:
vars: recurly__standardized_billing_model_enabled: false # true by default.
Passing Through Additional Fields
This package includes all source columns defined in the macros folder. You can add more columns using our pass-through column variables. These variables allow for the pass-through fields to be aliased (alias) and casted (transform_sql) if desired, but not required. Datatype casting is configured via a sql snippet within the transform_sql key. You may add the desired sql while omitting the as field_name at the end and your custom pass-though fields will be casted accordingly. Use the below format for declaring the respective pass-through variables:
vars: recurly_account_pass_through_columns: - name: "new_custom_field" alias: "custom_field" transform_sql: "cast(custom_field as string)" - name: "another_one" recurly_subscription_pass_through_columns: - name: "this_field" alias: "cool_field_name"
Change the build schema
By default, this package builds the Recurly staging models within a schema titled (<target_schema> + _recurly_source) and the Recurly transformation models within a schema titled (<target_schema> + _recurly) in your destination. If this is not where you would like your recurly staging data to be written to, add the following configuration to your root dbt_project.yml file:
models: recurly: +schema: my_new_schema_name # Leave +schema: blank to use the default target_schema. staging: +schema: my_new_schema_name # Leave +schema: blank to use the default target_schema.
Change the source table references
If an individual source table has a different name than the package expects, add the table name as it appears in your destination to the respective variable:
IMPORTANT: See this project's
dbt_project.ymlvariable declarations to see the expected names.
vars:_identifier: your_table_name
(Optional) Step 6: Orchestrate your models with Fivetran Transformations for dbt Core™
Expand to view details
Fivetran offers the ability for you to orchestrate your dbt project through Fivetran Transformations for dbt Core™. Learn how to set up your project for orchestration through Fivetran in our Transformations for dbt Core setup guides.
Does this package have dependencies?
This dbt package is dependent on the following dbt packages. These dependencies are installed by default within this package. For more information on the following packages, refer to the dbt hub site.
IMPORTANT: If you have any of these dependent packages in your own
packages.ymlfile, we highly recommend that you remove them from your rootpackages.ymlto avoid package version conflicts.
packages: - package: fivetran/fivetran_utils version: [">=0.4.0", "<0.5.0"] - package: dbt-labs/dbt_utils version: [">=1.0.0", "<2.0.0"] - package: dbt-labs/spark_utils version: [">=0.3.0", "<0.4.0"]
How is this package maintained and can I contribute?
Package Maintenance
The Fivetran team maintaining this package only maintains the latest version of the package. We highly recommend that you stay consistent with the latest version of the package and refer to the CHANGELOG and release notes for more information on changes across versions.
Contributions
A small team of analytics engineers at Fivetran develops these dbt packages. However, the packages are made better by community contributions.
We highly encourage and welcome contributions to this package. Check out this dbt Discourse article to learn how to contribute to a dbt package.
Are there any resources available?
- If you have questions or want to reach out for help, see the GitHub Issue section to find the right avenue of support for you.
- If you would like to provide feedback to the dbt package team at Fivetran or would like to request a new dbt package, fill out our Feedback Form.