Staging for Snowflake
While running Burst Integrate or Bulk Refresh, Fivetran HVR can put data into a temporary directory (‘staging file') before loading data into a target database. For more information about staging files on Snowflake, see Snowflake Documentation.
For best performance, HVR performs Burst Integrate and Bulk Refresh into Snowflake using staging files. HVR implements the file staging in Snowflake as follows:
- HVR first writes data into the staging directory on the configured platform. Since 6.2.5/4, the staging files can be stored in CSV or Parquet format.The following interfaces are used by HVR on each platform for staging data:
Known issues with Parquet: Dates and timestamps before year 1583 can be replicated incorrectly due to the shift from the Gregorian to the Julian calendar.
- Snowflake Internal Staging using Snowflake ODBC driver
- AWS or Google Cloud Storage using cURL library
- Azure Blob FS using HDFS-compatible libhdfs API
- HVR then uses the Snowflake SQL command
copy intoto ingest data into the Snowflake target tables from the staging directory.
HVR supports the following platforms for staging files:
- Snowflake Internal Staging
- Snowflake on AWS
- Snowflake on Azure
- Snowflake on Google Cloud Storage
Snowflake Internal Staging
HVR can stage data on the Snowflake internal staging before loading it into Snowflake while performing Burst Integrate and Bulk Refresh. For more information about Snowflake internal staging, refer to the Snowflake Documentation.
To use the Snowflake internal staging, while creating a location or by editing the existing location's source and target properties deselect the Integrate Staging Directory option in the User Interface (same as not defining the location property Staging_Directory) on the corresponding integrate/target location.
Snowflake on AWS
HVR must be configured to stage the data on AWS S3 before loading it into Snowflake. For staging the data on AWS S3 and perform Burst Integrate and Bulk Refresh, the following are required:
An AWS S3 location (bucket) to store temporary data to be loaded into Snowflake. For more information about creating and configuring an S3 bucket, refer to the AWS Documentation.
An AWS user with AmazonS3FullAccess permission policy to access the S3 bucket. Alternatively, an AWS user with minimal set of permission can also be used:
Click here for minimal set of permissions.
- s3:GetBucketLocation
- s3:ListBucket
- s3:ListBucketMultipartUploads
- s3:AbortMultipartUpload
- s3:GetObject
- s3:PutObject
- s3:DeleteObject
Sample JSON with a user role permission policy for S3 location
{ "Statement": [ { "Sid": <identifier>, "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::<account_id>:<user>/<username>", }, "Action": [ "s3:GetObject", "s3:GetObjectVersion", "s3:PutObject", "s3:DeleteObject", "s3:DeleteObjectVersion", "s3:AbortMultipartUpload" ], "Resource": "arn:aws:s3:::<bucket_name>/*" }, { "Sid": <identifier>, "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::<account_id>:<user>/<username>" }, "Action": [ "s3:ListBucket", "s3:GetBucketLocation", "s3:ListBucketMultipartUploads" ], "Resource": "arn:aws:s3:::<bucket_name>" } ] }For minimal permission, HVR also supports the AWS temporary security credentials in IAM. There are two ways to request for the AWS Security Token Service (STS) temporary credentials:
Using a combination of AWS STS Role ARN, AWS Access Key Id, and AWS Secret Access Key
Sample JSON
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::<account_id>:<user>/<username>" }, "Action": "sts:AssumeRole" } ] }Using a combination of AWS STS Role ARN and AWS IAM Role (a role that has access to an EC2 machine)
Sample JSON
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::<account_id>:<user>/<username>", "arn:aws:iam::<account_id>:<role>/<username>" ] }, "Action": "sts:AssumeRole" } ] }
For more information on the Amazon S3 permissions policy, refer to the AWS S3 documentation.
For more information, refer to the following AWS documentation:
Define the following location properties (while creating a location or by editing the existing location's source and target properties) for the Snowflake location:
- The Location Property equivalent to the UI field is shown inside (bracket) below.
- If the managed secrets feature is enabled, option USE TOKEN INSTEAD is displayed in the fields designated for entering secrets.
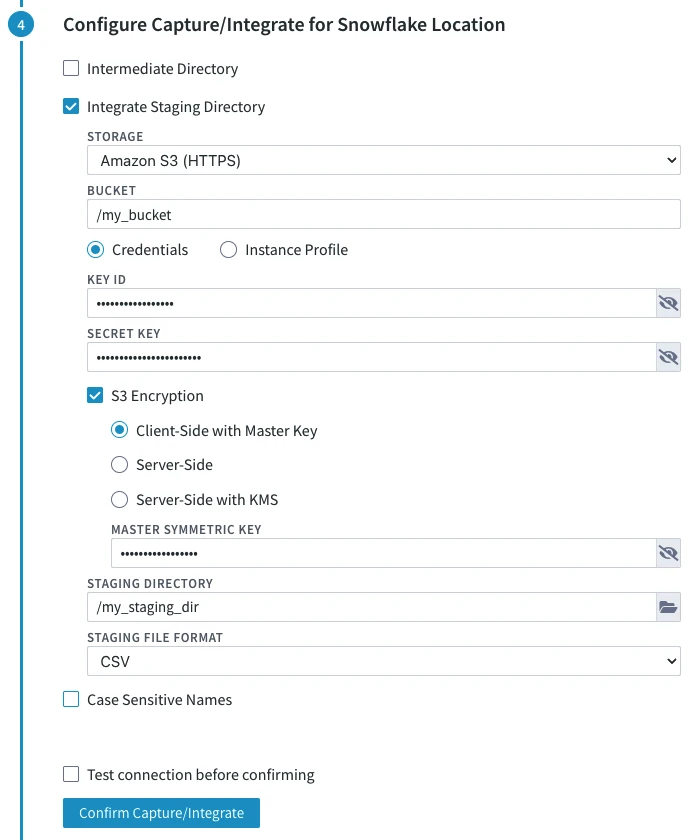
STORAGE (File_Scheme): protocol for connecting HVR to S3.
Select either of the following options:
- Amazon S3 (HTTPS)
- Amazon S3 (HTTP)
BUCKET (S3_Bucket): Name or IP address of the Amazon S3 bucket.
Credentials or Instance Profile: AWS security credentials. For more information about getting your AWS credentials or Instance Profile Role, refer to the AWS Documentation.
- If Credentials is selected, the location property KEY ID (AWS_Access_Key_Id) and SECRET KEY (AWS_Secret_Access_Key) must be supplied.
KEY ID: Access key ID of IAM user for connecting HVR to Amazon S3.
SECRET KEY: Secret access key of IAM user for connecting HVR to Amazon S3.
- If Instance Profile is selected, the location property IAM ROLE (AWS_IAM_Role) must be supplied.
- IAM ROLE: AWS IAM role name for connecting HVR to Amazon S3.
- If Credentials is selected, the location property KEY ID (AWS_Access_Key_Id) and SECRET KEY (AWS_Secret_Access_Key) must be supplied.
Optionally, S3 Encryption can be enabled. For more information about S3 data encryption, refer to the AWS Documentation.
The available options are:
Client-Side with Master Key: Enables client-side encryption using a master symmetric key for AES. The MASTER SYMMETRIC KEY (S3_Encryption_Master_Symmetric_Key) must be supplied for this encryption method.
Server-Side (S3_Encryption_SSE): Enables server-side encryption with Amazon S3 managed keys.
Server-Side with KMS (S3_Encryption_SSE_KMS): Enables server-side encryption with customer master keys (CMKs) stored in AWS key management service (KMS). If CUSTOMER MASTER KEY ID (S3_Encryption_KMS_Customer_Master_Key_Id) is not specified, a KMS managed CMK is used.
STAGING DIRECTORY (Staging_Directory): location where HVR will create the temporary staging files inside the S3 bucket (e.g. /my_staging_dir).
Since 6.2.5/4, in the STAGING FILE FORMAT drop-down menu (Staging_File_Format), select the format for storing the staging files:
- CSV
- Parquet
Known issues with Parquet: Dates and timestamps before year 1583 can be replicated incorrectly due to the shift from the Gregorian to the Julian calendar.
Sample screenshot
By default, HVR connects to us-east-1 once for determining your S3 bucket region. If a firewall restriction or a service such as Amazon Private Link is preventing the determination of your S3 bucket region, you can change this region (us-east-1) to the region where your S3 bucket is located by defining the following action:
| Group | Table | Action/Parameter(s) |
|---|---|---|
| Snowflake | * | Environment - Name=HVR_S3_BOOTSTRAP_REGION, Value=s3_bucket_region |
Snowflake on Azure
Due to technical limitations, external staging on Azure for Snowflake is not supported in the HVR releases since 6.1.5/3 to 6.1.5/9.
HVR must be configured to stage the data on Azure BLOB storage before loading it into Snowflake. For staging the data on Azure BLOB storage and perform Burst Integrate and Bulk Refresh , the following are required:
An Azure BLOB storage location (container) to store temporary data to be loaded into Snowflake.
An Azure user (storage account) to access the container. For more information, refer to the Azure Blob storage documentation.
Define the following location properties (while creating a location or by editing the existing location's source and target properties) for the Snowflake location:
- The Location Property equivalent to the UI field is shown inside (bracket) below.
- If the managed secrets feature is enabled, option USE TOKEN INSTEAD is displayed in the fields designated for entering secrets.
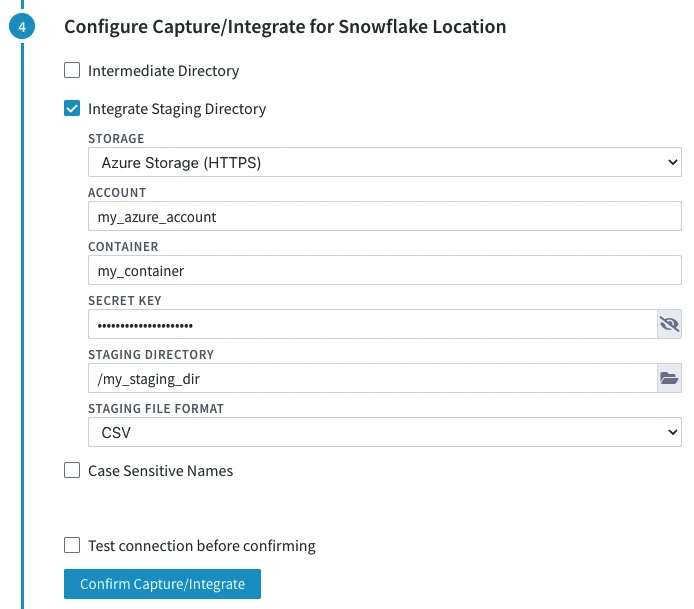
- STORAGE (File_Scheme): Protocol for connecting HVR to Azure.
Select either of the following options:- Azure Storage (HTTPS)
- Azure Storage (HTTP)
- ACCOUNT (WASB_Account): Name of the Azure Blob Storage account.
- CONTAINER (WASB_Container): Name of the container available within the Azure Blob Storage account.
- SECRET KEY (Azure_Shared_Secret_Key): Access key of the Azure storage ACCOUNT.
- STAGING DIRECTORY (Staging_Directory): Location where HVR will create the temporary staging files inside the Azure container (e.g. /my_staging_dir).
- Since 6.2.5/4, in the STAGING FILE FORMAT drop-down menu (Staging_File_Format), select the format for storing the staging files:
- CSV
- Parquet Known issues with Parquet: Dates and timestamps before year 1583 can be replicated incorrectly due to the shift from the Gregorian to the Julian calendar.
Sample screenshot
For Linux (x64) and Windows (x64), it is not required to install and configure the Hadoop client. However, if you want to use the Hadoop client, set the environment variable HVR_AZURE_USE_HADOOP=1 and follow the Hadoop client configuration steps mentioned below.
Click here for the Hadoop client configuration steps.
Internally, HVR uses the WebHDFS REST API to connect to the Azure Blob FS. Azure Blob FS locations can only be accessed through HVR running on Linux or Windows, and it is not required to run HVR installed on the Hadoop NameNode although it is possible to do so. For more information about installing Hadoop client, refer to Apache Hadoop Releases.
Hadoop Client Configuration
The following are required on the machine from which HVR connects to Azure Blob FS:
- Hadoop 2.6.x client libraries with Java 7 Runtime Environment or Hadoop 3.x client libraries with Java 8 Runtime Environment. For downloading Hadoop, refer to Apache Hadoop Releases.
- Set the environment variable $JAVA_HOME to the Java installation directory. Ensure that this is the directory that has a bin folder, e.g. if the Java bin directory is d:\java\bin, $JAVA_HOME should point to d:\java.
- Set the environment variable $HADOOP_COMMON_HOME or $HADOOP_HOME or $HADOOP_PREFIX to the Hadoop installation directory, or the hadoop command line client should be available in the path.
- One of the following configuration is recommended,
Set $HADOOP_CLASSPATH=$HADOOP_HOME/share/hadoop/tools/lib/*
Create a symbolic link for $HADOOP_HOME/share/hadoop/tools/lib in $HADOOP_HOME/share/hadoop/common or any other directory present in classpath.
Since the binary distribution available in Hadoop website lacks Windows-specific executables, a warning about unable to locate winutils.exe is displayed. This warning can be ignored for using Hadoop library for client operations to connect to a HDFS server using HVR. However, the performance on integrate location would be poor due to this warning, so it is recommended to use a Windows-specific Hadoop distribution to avoid this warning. For more information about this warning, refer to Hadoop Wiki and Hadoop issue HADOOP-10051.
Verifying Hadoop Client Installation
To verify the Hadoop client installation,
The HADOOP_HOME/bin directory in Hadoop installation location should contain the hadoop executables in it.
Execute the following commands to verify Hadoop client installation:
$JAVA_HOME/bin/java -version $HADOOP_HOME/bin/hadoop version $HADOOP_HOME/bin/hadoop classpathIf the Hadoop client installation is verified successfully then execute the following command to check the connectivity between HVR and Azure Blob FS:
To execute this command successfully and avoid the error "ls: Password fs.adl.oauth2.client.id not found", few properties needs to be defined in the file core-site.xml available in the hadoop configuration folder (for e.g., <path>/hadoop-2.8.3/etc/hadoop). The properties to be defined differs based on the Mechanism (authentication mode). For more information, refer to section 'Configuring Credentials' in Hadoop Azure Blob FS Support documentation.
$HADOOP_HOME/bin/hadoop fs -ls wasbs://containername@accountname.blob.core.windows.net/
Verifying Hadoop Client Compatibility with Azure Blob FS
To verify the compatibility of Hadoop client with Azure Blob FS, check if the following JAR files are available in the Hadoop client installation location ( $HADOOP_HOME/share/hadoop/tools/lib ):
hadoop-azure-<version>.jar azure-storage-<version>.jar
Snowflake on Google Cloud Storage
HVR must be configured to stage the data on Google Cloud Storage before loading it into Snowflake. For staging the data on Google Cloud Storage and perform Burst Integrate and Bulk Refresh, the following are required:
A Google Cloud Storage location (bucket) to store temporary data to be loaded into Snowflake.
A Google Cloud user (storage account) to access the bucket.
Configure the storage integrations to allow Snowflake to read and write data into a Google Cloud Storage bucket. For more information, refer to the section Configuring an Integration for Google Cloud Storage in Snowflake documentation.
Define the following location properties (while creating a location or by editing the existing location's source and target properties) for the Snowflake location:
- The Location Property equivalent to the UI field is shown inside (bracket) below.
- If the managed secrets feature is enabled, option USE TOKEN INSTEAD is displayed in the fields designated for entering secrets.
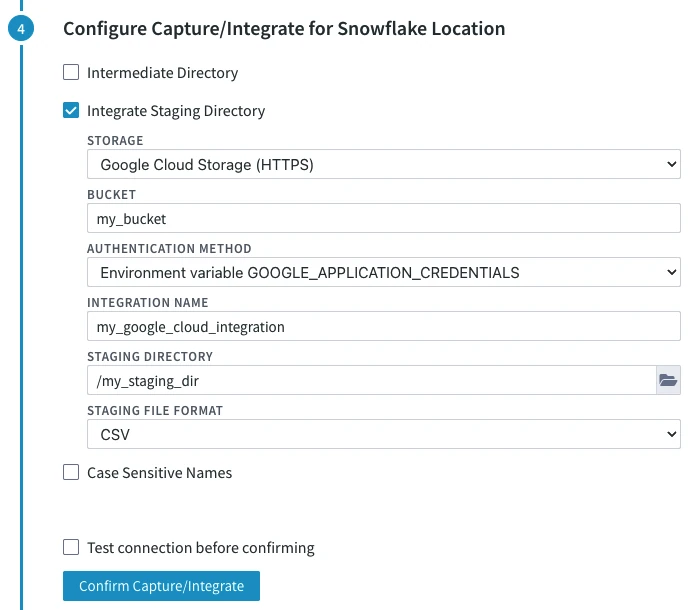
- STORAGE (File_Scheme): Protocol for connecting HVR to Google Cloud Storage.
Select either of the following options:- Google Cloud Storage (HTTPS)
- Google Cloud Storage (HTTP)
- BUCKET (GS_Bucket): Name or IP address of the Google Cloud Storage bucket.
- AUTHENTICATION METHOD (GCloud_Authentication_Method): Authentication method for connecting HVR to the Google Cloud server.
Select either of the following authentication methods and enter value for the available dependent fields:- Environment variable GOOGLE_APPLICATION_CREDENTIALS: Authenticate using the credentials fetched from the environment variable GOOGLE_APPLICATION_CREDENTIALS.
- OAuth 2.0 credentials file: Authenticate using the credentials supplied in the service account key file.
Enter value for the following field:- CREDENTIALS FILE (GCloud_OAuth_File): Directory path for the service account key file.
- HMAC: Authenticate using the credentials supplied as HMAC keys.
Enter value for the following fields:- ACCESS KEY (GS_HMAC_Access_Key_Id): The HMAC access ID of the service account.
- SECRET KEY (GS_HMAC_Secret_Access_Key): The HMAC secret of the service account.
- INTEGRATION NAME (GS_Storage_Integration): Integration name of the google cloud storage.
- STAGING DIRECTORY (Staging_Directory): Location where HVR will create the temporary staging files inside the Google Cloud Storage bucket (e.g. /my_staging_dir).
- Since 6.2.5/4, in the STAGING FILE FORMAT drop-down menu (Staging_File_Format), select the format for storing the staging files:
- CSV
- Parquet
Known issues with Parquet: Dates and timestamps before year 1583 can be replicated incorrectly due to the shift from the Gregorian to the Julian calendar.
Sample screenshot