LinkedIn Ad Analytics dbt Package (docs)
![]()
![]()
![]()
![]()
What does this dbt package do?
- Produces modeled tables that leverage Linkedin Ad Analytics data from Fivetran's connector in the format described by this ERD.
- Enables you to better understand the performance of your ads across varying grains:
- Providing an account, campaign (ad groups in other ad platforms), campaign group (campaigns in other ad platforms), creative, and utm/url level reports.
- Materializes output models designed to work simultaneously with our multi-platform Ad Reporting package.
- Generates a comprehensive data dictionary of your source and modeled Linkedin Ad Analytics data through the dbt docs site.
The following table provides a detailed list of all tables materialized within this package by default.
TIP: See more details about these tables in the package's dbt docs site.
| Table | Details |
|---|---|
linkedin_ads__account_report | Represents daily performance aggregated at the account level, including spend, clicks, impressions, and conversions.Example Analytics Questions:
|
linkedin_ads__campaign_report | Represents daily performance aggregated at the campaign level (equivalent to ad groups in other platforms), including spend, clicks, impressions, and conversions.Example Analytics Questions:
|
linkedin_ads__monthly_campaign_country_report | Represents monthly performance aggregated at the campaign level by country, including spend, clicks, impressions, and conversions, enriched with geographic context.Example Analytics Questions:
|
linkedin_ads__monthly_campaign_region_report | Represents monthly performance aggregated at the campaign level by region, including spend, clicks, impressions, and conversions, enriched with geographic context.Example Analytics Questions:
|
linkedin_ads__campaign_group_report | Represents daily performance aggregated at the campaign group level (equivalent to campaigns in other platforms), including spend, clicks, impressions, and conversions.Example Analytics Questions:
|
linkedin_ads__creative_report | Represents daily performance at the individual creative level (equivalent to ads in other platforms), including spend, clicks, impressions, and conversions.Example Analytics Questions:
|
linkedin_ads__url_report | Represents daily performance at the individual URL level, including spend, clicks, impressions, and conversions, enriched with creative context.Example Analytics Questions:
|
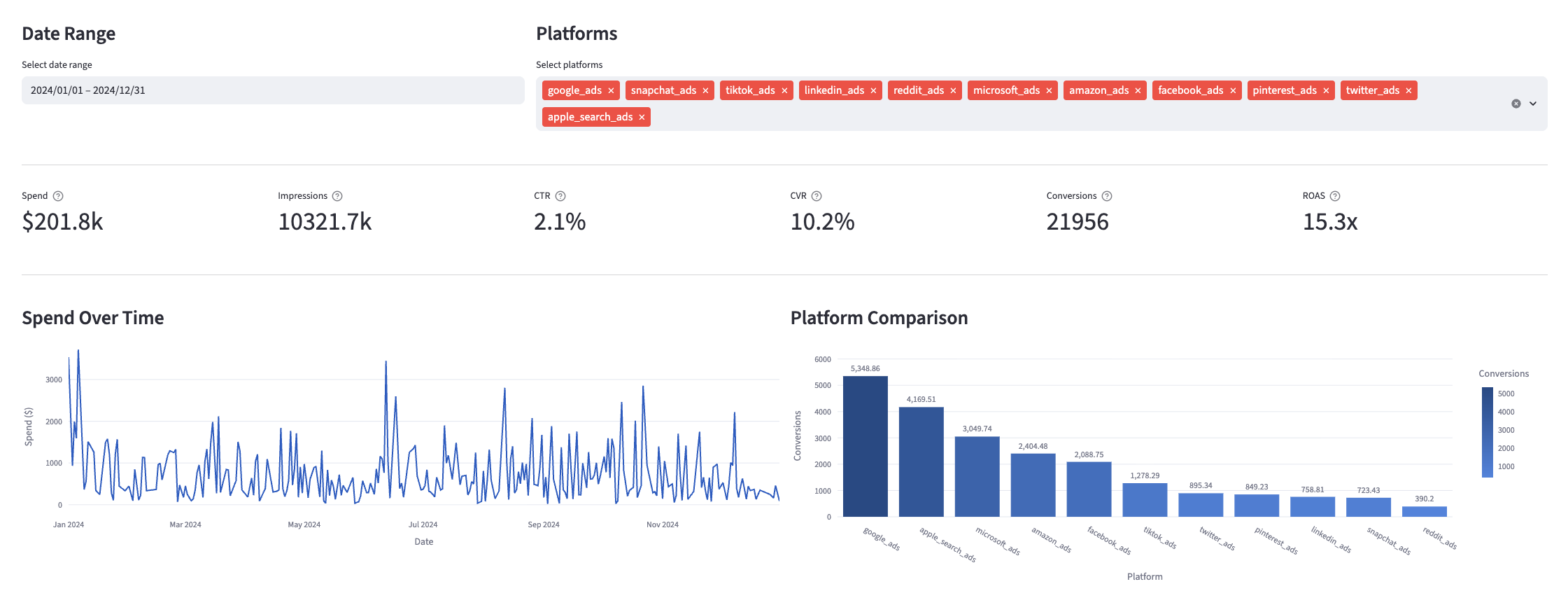
Many of the above reports are now configurable for visualization via Streamlit. Check out some sample reports here.
Example Visualizations
Curious what these tables can do? The Linkedin models provide advertising performance data that can be visualized to track key metrics like spend, impressions, click-through rates, conversion rates, and return on ad spend across different campaign structures and time periods. Check out example visualizations in the Fivetran Ad Reporting Streamlit App, and see how you can use these tables in your own reporting. Below is a screenshot of an example dashboard; explore the app for more.
Materialized Models
Each Quickstart transformation job run materializes 25 models if all components of this data model are enabled. This count includes all staging, intermediate, and final models materialized as view, table, or incremental.
How do I use the dbt package?
Step 1: Prerequisites
To use this dbt package, you must have the following:
- At least one Fivetran Linkedin Ad Analytics connection syncing data into your destination.
- A BigQuery, Snowflake, Redshift, PostgreSQL, or Databricks destination.
Databricks Dispatch Configuration
If you are using a Databricks destination with this package you will need to add the below (or a variation of the below) dispatch configuration within your dbt_project.yml. This is required in order for the package to accurately search for macros within the dbt-labs/spark_utils then the dbt-labs/dbt_utils packages respectively.
dispatch: - macro_namespace: dbt_utils search_order: ['spark_utils', 'dbt_utils']
Step 2: Install the package (skip if also using the ad_reporting combination package)
Include the following Linkedin Ads package version in your packages.yml file:
TIP: Check dbt Hub for the latest installation instructions or read the dbt docs for more information on installing packages
# packages.yml packages: - package: fivetran/linkedin version: [">=1.1.0", "<1.2.0"]
All required sources and staging models are now bundled into this transformation package. Do not include
fivetran/linkedin_sourcein yourpackages.ymlsince this package has been deprecated.
Step 3: Define database and schema variables
By default, this package runs using your destination and the linkedin_ads schema. If this is not where your Linkedin Ad Analytics data is (for example, if your Linkedin schema is named linkedin_ads_fivetran), add the following configuration to your root dbt_project.yml file:
# dbt_project.yml vars: linkedin_ads_schema: your_schema_name linkedin_ads_database: your_destination_name
(Optional) Step 4: Additional configurations
Union multiple connections
If you have multiple linkedin connections in Fivetran and would like to use this package on all of them simultaneously, we have provided functionality to do so. The package will union all of the data together and pass the unioned table into the transformations. You will be able to see which source it came from in the source_relation column of each model. To use this functionality, you will need to set either the linkedin_ads_union_schemas OR linkedin_ads_union_databases variables (cannot do both) in your root dbt_project.yml file:
vars: linkedin_ads_union_schemas: ['linkedin_usa','linkedin_canada'] # use this if the data is in different schemas/datasets of the same database/project linkedin_ads_union_databases: ['linkedin_usa','linkedin_canada'] # use this if the data is in different databases/projects but uses the same schema name
NOTE: The native
src_linkedin.ymlconnection set up in the package will not function when the union schema/database feature is utilized. Although the data will be correctly combined, you will not observe the sources linked to the package models in the Directed Acyclic Graph (DAG). This happens because the package includes only one definedsrc_linkedin.yml.
To connect your multiple schema/database sources to the package models, follow the steps outlined in the Union Data Defined Sources Configuration section of the Fivetran Utils documentation for the union_data macro. This will ensure a proper configuration and correct visualization of connections in the DAG.
Disable Country and Region Reports
This package leverages the geo, monthly_ad_analytics_by_member_country, and monthly_ad_analytics_by_member_region tables to help report on campaign performance by country and region. However, if you are not actively syncing these reports from your LinkedIn Ads connection, you may disable relevant transformations by adding the following variable configuration to your root dbt_project.yml file:
vars: linkedin_ads__using_geo: False # True by default linkedin_ads__using_monthly_ad_analytics_by_member_country: False # True by default linkedin_ads__using_monthly_ad_analytics_by_member_region: False # True by default
Switching to Local Currency
Additionally, the package allows you to select whether you want to add in costs in USD or the local currency of the ad. By default, the package uses USD. If you would like to have costs in the local currency, add the following variable to your dbt_project.yml file:
# dbt_project.yml vars: linkedin_ads__use_local_currency: True # false by default -- uses USD
Note: Unlike cost, conversion values are only available in the local currency. The package will only use the conversion_value_in_local_currency field for conversion values, while it may draw from the cost_in_local_currency and cost_in_usd source fields for cost.
Passing Through Additional Metrics
By default, this package will select clicks, impressions, cost and conversion_value_in_local_currency (as well as fields set via linkedin_ads__conversion_fields in the next section) from the source reporting tables ad_analytics_by_campaign, ad_analytics_by_creative, monthly_ad_analytics_by_member_country, and monthly_ad_analytics_by_member_region to store into the corresponding staging models. If you would like to pass through additional metrics to the staging models, add the below configurations to your dbt_project.yml file. These variables allow for the pass-through fields to be aliased (alias) and transformed (transform_sql) if desired, but not required. Only the name of each metric field is required. Use the below format for declaring the respective pass-through variables:
# dbt_project.yml vars: linkedin_ads__campaign_passthrough_metrics: # pulls from ad_analytics_by_campaign - name: "new_custom_field" alias: "custom_field_alias" transform_sql: "coalesce(custom_field_alias, 0)" # reference the `alias` here if you are using one - name: "unique_int_field" alias: "field_id" - name: "another_one" transform_sql: "coalesce(another_one, 0)" # reference the `name` here if you're not using an alias - name: "that_field" linkedin_ads__creative_passthrough_metrics: # pulls from ad_analytics_by_creative - name: "new_custom_field" alias: "custom_field" - name: "unique_int_field" linkedin_ads__monthly_ad_analytics_by_member_country_passthrough_metrics: # pulls from monthly_ad_analytics_by_member_country - name: "country_custom_field" alias: "country_field" linkedin_ads__monthly_ad_analytics_by_member_region_passthrough_metrics: # pulls from monthly_ad_analytics_by_member_region - name: "region_custom_field" alias: "region_field" - name: "region_field_two"
Note Please ensure you exercised due diligence when adding metrics to these models. The metrics added by default (clicks, impressions, and spend) have been vetted by the Fivetran team maintaining this package for accuracy. There are metrics included within the source reports, for example metric averages, which may be inaccurately represented at the grain for reports created in this package. You will want to ensure whichever metrics you pass through are indeed appropriate to aggregate at the respective reporting levels provided in this package. (Important: You do not need to add conversions in this way. See the following section for an alternative implementation.)
Adding in Conversion Fields Variable
Separate from the above passthrough metrics, the package will also include conversion metrics based on the linkedin_ads__conversion_fields variable, in addition to the conversion_value_in_local_currency field within the ad_analytics_by_campaign, ad_analytics_by_creative, monthly_ad_analytics_by_member_country and monthly_ad_analytics_by_member_region data models.
By default, the data models consider external_website_conversions and one_click_leads to be conversions. These should cover most use cases, but if you wanted to adjust this to your business case, you would apply the following configuration with the original source names of the conversion fields (not aliases you provided in the section above):
# dbt_project.yml vars: linkedin_ads__conversion_fields: ['external_website_pre_click_conversions', 'one_click_leads', 'external_website_post_click_conversions', 'landing_page_clicks']
Make sure to follow best practices in configuring fields in the conversion field variables! See the DECISIONLOG for more details.
We introduced support for conversion fields in our
reportdata models in the v0.9.0 release of the package, but customers might have been bringing in these conversion fields earlier using the passthrough fields variables. The data models will avoid "duplicate column" errors automatically if this is the case.
Changing the Build Schema
By default this package will build the LinkedIn Ad Analytics staging models within a schema titled (<target_schema> + _linkedin_ads_source) and the LinkedIn Ad Analytics final models within a schema titled (<target_schema> + _linkedin_ads) in your target database. If this is not where you would like your modeled LinkedIn data to be written to, add the following configuration to your dbt_project.yml file:
# dbt_project.yml models: linkedin: +schema: my_new_schema_name # Leave +schema: blank to use the default target_schema. staging: +schema: my_new_schema_name # Leave +schema: blank to use the default target_schema.
Change the source table references
If an individual source table has a different name than the package expects, add the table name as it appears in your destination to the respective variable. This is not available when running the package on multiple unioned connections.
IMPORTANT: See this project's
dbt_project.ymlvariable declarations to see the expected names.
# dbt_project.yml vars: linkedin_ads__identifier: your_table_name
(Optional) Step 5: Orchestrate your models with Fivetran Transformations for dbt Core™
Expand for more details
Fivetran offers the ability for you to orchestrate your dbt project through Fivetran Transformations for dbt Core™. Learn how to set up your project for orchestration through Fivetran in our Transformations for dbt Core™ setup guides.
Does this package have dependencies?
This dbt package is dependent on the following dbt packages. These dependencies are installed by default within this package. For more information on the following packages, refer to the dbt hub site.
IMPORTANT: If you have any of these dependent packages in your own
packages.ymlfile, we highly recommend that you remove them from your rootpackages.ymlto avoid package version conflicts.
packages: - package: fivetran/fivetran_utils version: [">=0.4.0", "<0.5.0"] - package: dbt-labs/dbt_utils version: [">=1.0.0", "<2.0.0"] - package: dbt-labs/spark_utils version: [">=0.3.0", "<0.4.0"]
How is this package maintained and can I contribute?
Package Maintenance
The Fivetran team maintaining this package only maintains the latest version of the package. We highly recommend you stay consistent with the latest version of the package and refer to the CHANGELOG and release notes for more information on changes across versions.
Contributions
A small team of analytics engineers at Fivetran develops these dbt packages. However, the packages are made better by community contributions.
We highly encourage and welcome contributions to this package. Check out this dbt Discourse article on the best workflow for contributing to a package.
Contributors
We thank everyone who has taken the time to contribute. Each PR, bug report, and feature request has made this package better and is truly appreciated.
A special thank you to Seer Interactive, who we closely collaborated with to introduce native conversion support to our Ad packages.
Are there any resources available?
- If you have questions or want to reach out for help, see the GitHub Issue section to find the right avenue of support for you.
- If you would like to provide feedback to the dbt package team at Fivetran or would like to request a new dbt package, fill out our Feedback Form.