BigQuery Partitioned Tables
Google supports partitioned tables in BigQuery. Partitioning your tables makes it easier to manage the data and improves query performance. Partitioning can decrease the costs of writing to and querying from your BigQuery warehouse. For more information about partitioned tables, see BigQuery's partitioned table documentation.
There are three types of table partitioning you can use in BigQuery:
- Tables partitioned by ingestion time: Tables partitioned based on the data's ingestion (load) date or arrival date
- Tables partitioned by date/timestamp/datetime: Tables that are partitioned based on a TIMESTAMP, or DATE, or DATETIME column
- Tables partitioned by integer range: Tables that are partitioned based on an INTEGER column
Fivetran supports ingestion time partitioned tables, column-partitioned tables, and integer-range partitioned tables.
Fivetran only supports time partitioning based on daily (DAY) granularity. We don't support hourly, monthly, or yearly granularity.
If your partition key is not based on your source's primary key, we perform full table scans to avoid writing duplicates to different partitions within the same table. If your partition key is based on your source's primary key, we automatically optimize how we write data to BigQuery.
BigQuery supports single-column partitioning. If you have a composite primary key, you must choose a column from the primary key list as the partition key. We use this partition key to optimize our write query.
Create ingestion-time partitioned tables
To create tables partitioned by ingestion time, do the following:
Go to the BigQuery web UI in the GCP console.
In the navigation bar, select your project.
Find the dataset that Fivetran will use as your destination. If you don’t have a dataset, create a new dataset.
When you create the connection that will use this dataset, you must name your destination schema (which also becomes the connection name) with the same name as the dataset.
Grant
bigquery.dataOwneraccess for this dataset to the service account so that it can create, delete, and update tables in the dataset. For detailed instructions, see BigQuery's documentation on controlling access to datasets.In the details panel, select + Create Table.
In the Create table window:
- in the Source section, retain the default value.
- in the Destination section, retain the default values for Project name, Dataset name, and Table type.
- in the Schema section, retain the default value.
In the Table name field, enter the same name as the corresponding table in Fivetran's ERD for your connector.
If your connector doesn't have an ERD, you must determine the table name in your source, and use that name for your BigQuery destination table.
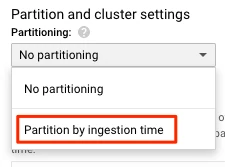
In Partition and cluster settings section, select Partition by ingestion time.
Select Create table.
For more information, see BigQuery's Create an ingestion-time partitioned table documentation.
Create time-unit column-partitioned or integer-range partitioned tables
To convert a BigQuery non-partitioned table into a column-partitioned or an integer-range partitioned table, do the following:
Pause the connection
Go to your Fivetran dashboard and select the connection for which you want to convert your non-partitioned tables into partitioned tables.
Check the connection sync status in the top right corner of your dashboard: ENABLED or PAUSED.
If your connection is already paused, skip to Step 2.
Set the connection status toggle to PAUSED.
Convert to partitioned tables
To convert an existing table to a partitioned table, in the BigQuery console, execute one of the following SQL statements. The following statements will create a partitioned table, insert data from the original table, and then drop the original table:
- If you want to partition the table based on a TIMESTAMP column, use:
create table [schema-name].copy partition by date([timestamp-column]) as select * from [schema-name].[table-name]; drop table [schema-name].[table-name];- If you want to partition the table based on a DATE column, use:
create table [schema-name].copy partition by [date-column] as select * from [schema-name].[table-name]; drop table [schema-name].[table-name];- If you want to partition the table based on a DATETIME column, use:
create table [schema-name].copy partition by [datetime-column] as select * from [schema-name].[table-name]; drop table [schema-name].[table-name];- If you want to partition the table based on an INTEGER column, use:
create table [schema-name].copy partition by range_bucket([integer-column],GENERATE_ARRAY([start],[end],[interval])) as select * from [schema-name].[table-name]; drop table [schema-name].[table-name];Go to the BigQuery web UI in the GCP console.
In the navigation bar, select your project.
Select your dataset. In the dataset, find and select the copy table you created.
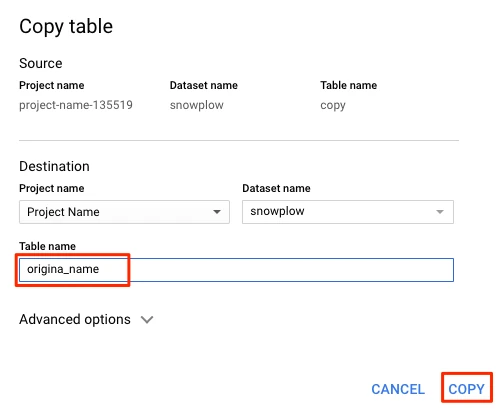
Rename the copy table to have the original table's name. In the details panel, click Copy Table.

In the Table name field, enter your original table's name and click Copy.
Drop the copy table. Execute the following SQL command in the BigQuery query editor:
drop table [schema-name].copy;
Repeat the above instructions for every table you want to convert.
For more information, see BigQuery's Create a time-unit column-partitioned table and create an integer-range partitioned table documentation.
Enable the connection
Go to your Fivetran dashboard and set the connection status toggle to ENABLED.