Best Practices for Snowflake with HVR
Question
What are some best practices for using Snowflake with HVR?
Environment
HVR 5
Answer
Our Professional service group is a skilled group of consultants who can help to optimize your practice.
Looking at best practices for replicating data in Snowflake there are two angles:
- Keep the cost within budget as Snowflake is a consumption-based priced data warehouse.
- Keep the latency as low as possible.
Keeping the Cost Within Budget
To balance your business requirements between quick access to replicated data and minimizing costs in Snowflake, the following best practices need to be applied.
In the Integrate action of HVR, the following parameters should be set:
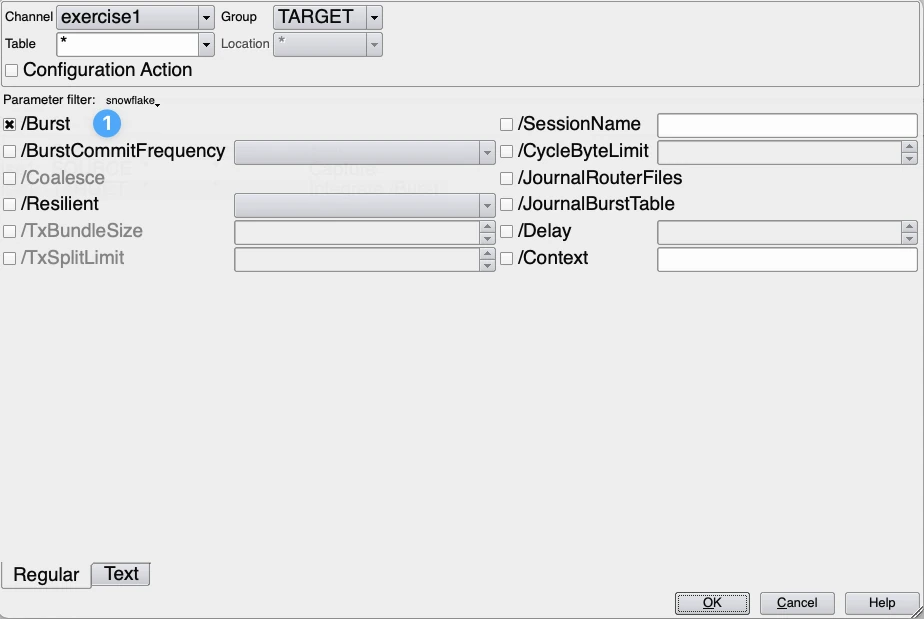
- Burst should be always selected. Burst integrate will improve the performance and lower costs as we create a minimum of records to be integrated by coalescing. In addition, it does explicit filtering of boundary values for set-base operation. All DML statements are applied in a single merge statement, which lowers the cloud services costs.
- BurstCommitFrequency should be set to Cycle (2). in HVR, this is done by default. In this case, all changes for the integrate job cycle are committed in a single transaction. This will reduce cloud service costs. BurstCommitFrequency is the default setting for Snowflake in HVR.
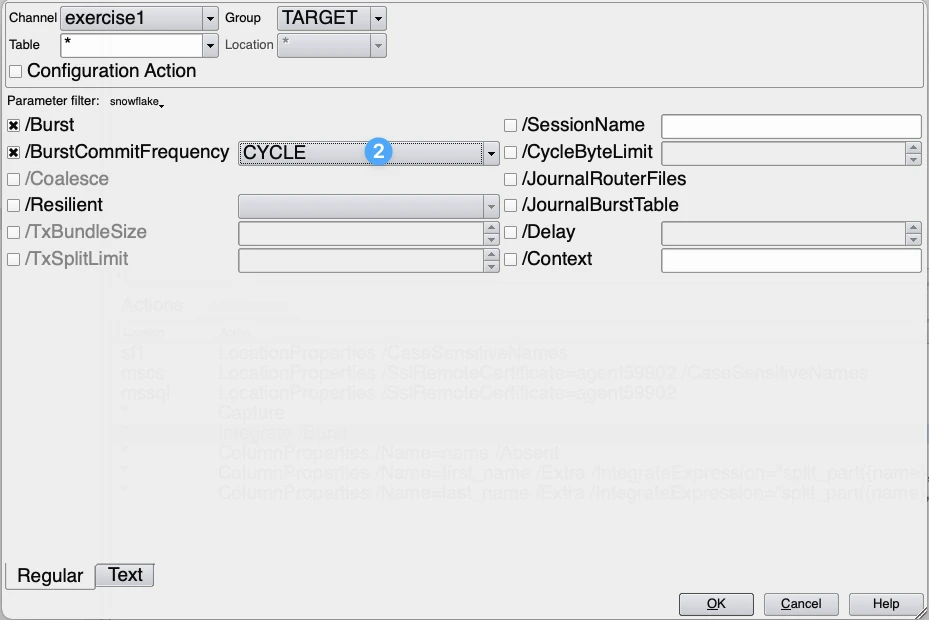
If during processing the integrate cycle is split up in multiple sub cycles and Snowflake cost are the leading driver the following parameters needs to be changed. The parameter to set is the CycleByteLimit, this should be set to around 1GB for the start. If the CycleByteLimit is increased this can lead to warnings which state that the SORT_BYTE_LIMIT should be increased to prevent that data will be spilled to disk. If this warning is shown on a regular basis please do the following. Depending on the frequency of the integrate cycles which will be discussed later HVR_SORT_BYTE_LIMIT can be increased to 4 GB. Important is that the integrate agent or hub server if the hub takes care of the integrate process, does have enough available memory. A higher value normally will result in longer integrate cycles. So if performance and latency are more important parameters the CycleByteLimit should kept to the default value of 512 MB. On the other side it also can depend on the hardware sizing of the integrate agent which can lead to a more optimal size of this parameter.
Together with the CycleByteLimit also the environment variable $HVR_SORT_BYTE_LIMIT, needs to be changed. If Snowflake credit costs are leading and latency is of less importance. The $HVR_SORT_BYTE_LIMIT is the variable that; Limit memory usage during sorting (before spilling to disk) Values supplied can have "K" or "M" suffix.
Doing the sorting in memory, processing time improves and integration cycle takes take a shorter amount. A good rule of thumb is that the $HVR_SORT_BYTE_LIMIT is 4-5 times higher than the CycleByteLimit.
If from a business perspective near real time is not a necessity, a good action to save costs is to schedule the integrate every 10 - 30 minutes. Depending on the SLA agreed between business and IT the time frame can be larger or smaller.
This scheduling can be done with the action Scheduling. In this action select the IntegrateStartTimes (3) a cron expression determines the schedule pattern. In this example the Integrate is scheduled for every 10 minutes.
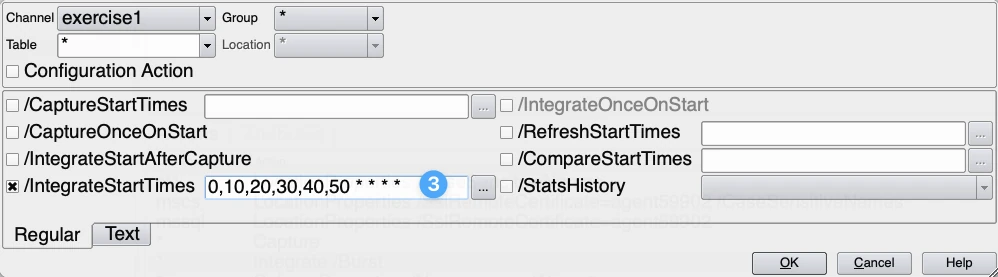
Scheduling the integrate will significantly reduce the consumption based costs. To find an optimum the agreed SLA and the credits consumed a calculation needs to be made between IT and the business.
With the scheduling the latency of the integrated data is a summation of the time between the integrate cycles and the time it takes for a complete integrate cycle. To manipulate this time there is the possibility to have multiple integration locations. This will shorten the integrate cycle and result that with a lower scheduling frequency you still make your SLA. This is a manual process and can increase the used Snowflake credits. In this case replication of the data from source to Snowflake can be run in parallel. This can increase cloud service costs as more integrate cycles will run in the same time. The volume of data will not change. An example of such a setup is shown below.
To find here an optimum a calculation must be made on the different scenarios. Or usage of credits can be measured in an isolated environment where multiple scenarios are tested.
In rare cases especially with some very large tables with high amounts of data traffic it can be beneficial that S3 or Blob Storage is used instead of the internal Snowflake storage. Please consult the PS consultants or support engineer for this.
Another component that can have a positive effect on the performance is the choice for the VM used for the hub and/or integrate agent. As there are many aspects in the choice for the VM this is kept out of this document. Your PS resource can help you making the correct decisions.
Concluding the above recommendations will optimize both the cost management and data latency. It depends on the business case if the latency or cost management is most important. Depending on this the frequency of the integrate cycles can be increased or decreased. The parallelism of the integrate can lower the latency against more or less the same cost rate. However, the advice is to measure different scenarios to determine what the optimum is for your organization.
Special recommendations
In some cases when a table is truncated and reloaded on a regular basis, it can be more cost effective to run only refresh jobs and don’t use cdc to replicate data between source and Snowflake.
A Fivetran solution consultant can advise you if this is beneficial in your particular case.