High-Volume Agent SQL Server
SQL Server is Microsoft's SQL database. Fivetran replicates data from your SQL Server source database and loads it into your destination using High-Volume Agent connector.
You must have an Enterprise or Business Critical plan to use the High-Volume Agent SQL Server connector.
We have introduced a new incremental sync method, Binary Log Reader, for our SQL Server connector. This proprietary method reads your database's transaction log files in their original binary format. We recommend this method to replicate large volumes of data from the SQL Server transaction logs with minimal impact on your source database. For more information, see our Binary Log Reader documentation.
Row-based relational databases, like SQL Server, are optimized for high-volume, high-frequency transactional applications. While very performant as production databases, they are not optimized for analytical querying. Your analytical queries will be very slow if you build your BI stack directly on top of your transactional SQL Server database, and you run the risk of slowing down your application layer.
Column-based databases are optimized for performing analytical queries on large volumes of data at speeds far exceeding those of SQL Server. While these databases are not good for high-frequency transactional applications, they are highly efficient in data storage. They permit more data compression (10x-100x) than row-based databases, which makes them a cost-effective way to store and access data for analytical purposes.
Supported services
Fivetran supports the Generic SQL Server database service.
Supported configurations
Fivetran supports the following SQL Server configurations:
| Operating Systems | Supported Versions |
|---|---|
| Windows | SQL Server 2012 - 2022 |
| Linux | SQL Server 2017 - 2019 |
| Recovery Models | Supported |
|---|---|
| Full | |
| Bulk-logged | |
| Simple |
| Supportability Category | Supported Values |
|---|---|
| Transport Layer Security (TLS) | TLS 1.2 - 1.3 |
| Instance Types | Supported |
|---|---|
| Generic SQL Server | |
| Primary instance | |
| Availability group replica |
Limitations
We do not support the following with the High-Volume Agent SQL Server connector:
- Single-user mode
- Amazon RDS for SQL Server
Features
| Feature Name | Supported | Notes |
|---|---|---|
| Capture deletes | ||
| History mode | ||
| Custom data | ||
| Data blocking | ||
| Column hashing | ||
| Re-sync | ||
| Row filtering | ||
| API configurable | API configuration | |
| Priority-first sync | ||
| Fivetran data models | ||
| Private networking |
| |
| Authorization via API |
Supported deployment models
We support the SaaS and Hybrid deployment models for the connector.
You must have an Enterprise or Business Critical plan to use the Hybrid Deployment model.
Setup guide
Follow our step-by-step High-Volume Agent SQL Server setup guide for specific instructions on how to set up your SQL Server database.
Sync overview
Once connected to your database, the Fivetran connector runs an initial sync, pulling a full dump of selected data from your database and sending it to your destination. After a successful initial sync, the connector runs in an incremental sync mode. In this mode, Fivetran automatically detects new or updated data, such as new tables or data type changes, and persists these changes into your destination. We use log-based capture to extract your database's change data, then process and load these changes at regular intervals, ensuring a consistently updated synchronization between your database and destination.
Choosing a 1-minute sync frequency does not guarantee that your sync finishes within one minute.
Syncing empty tables and columns
Fivetran can sync empty tables for your SQL Server connection.
We can also sync empty columns in most cases. However, if you don't add rows after you create a new column, we cannot sync that new column. We need at least one row to see a new column because we learn of changes to a table's column cardinality when we see a row with a new or removed column during an update.
For more information, see our Features documentation.
Schema information
Fivetran tries to replicate the exact schema and tables from your database to your destination.
Fivetran-generated columns
Fivetran adds the following columns to every table in your destination:
_fivetran_deleted(BOOLEAN) marks rows that were deleted in the source table_fivetran_id(STRING) is a unique ID that Fivetran uses to avoid duplicate rows in tables that do not have a primary key_fivetran_synced(UTC TIMESTAMP) indicates the time when Fivetran last successfully synced the row
We add these columns to give you insight into the state of your data and the progress of your data syncs. For more information about these columns, see our System Columns and Tables documentation.
Type transformations and mapping
As we extract your data, we match SQL Server data types to data types that Fivetran supports. If we don't support a certain data type, we automatically change that type to the closest supported type or, for some types, don't load that data at all. Our system automatically skips columns with data types that we don't accept or transform.
The following table illustrates how we transform your SQL Server data types into Fivetran supported types:
| SQL Server Type | Fivetran Type | Fivetran Supported |
|---|---|---|
| BIGINT | LONG | True |
| BINARY | BINARY | True |
| BIT | BOOLEAN | True |
| CHAR | STRING | True |
| DATE | LOCALDATE | True |
| DATETIME | LOCALDATETIME | True |
| DATETIME2 | LOCALDATETIME | True |
| DATETIMEOFFSET | INSTANT | True |
| DECIMAL | BIGDECIMAL | True |
| FLOAT | DOUBLE | True |
| GEOMETRY | JSON | True |
| GEOGRAPHY | JSON | True |
| IMAGE | BINARY | True |
| INTEGER | INT | True |
| MONEY | BIGDECIMAL | True |
| NCHAR | STRING | True |
| NTEXT | STRING | True |
| NUMERIC | BIGDECIMAL | True |
| NVARCHAR | STRING | True |
| REAL | FLOAT | True |
| ROWVERSION | BINARY | True |
| SMALLDATETIME | LOCALDATETIME | True |
| SMALLMONEY | BIGDECIMAL | True |
| SMALLINT | SHORT | True |
| TEXT | STRING | True |
| TIME | STRING | True |
| TIMESTAMP | BINARY | True |
| TINYINT | SHORT | True |
| UNIQUEIDENTIFIER | STRING | True |
| VARCHAR | STRING | True |
| VARBINARY | BINARY | True |
| XML | STRING | True |
| HIERARCHYID | STRING | False |
If we are missing an important type that you need, reach out to support.
In some cases, when loading data into your destination, we may need to convert Fivetran data types into data types that are supported by the destination. For more information, see the individual data destination pages.
Supported encodings
We support the following character encodings for HVA SQL Server.
Click to see the full list
- IBM437
- IBM850
- UTF-16LE
- WINDOWS-874
- WINDOWS-932
- WINDOWS-936
- WINDOWS-949
- WINDOWS-950
- WINDOWS-1250
- WINDOWS-1251
- WINDOWS-1252
- WINDOWS-1253
- WINDOWS-1254
- WINDOWS-1255
- WINDOWS-1256
- WINDOWS-1257
- WINDOWS-1258
Excluding source data
If you don’t want to sync all the data from your database, you can exclude schemas, tables, or columns from your syncs on your Fivetran dashboard. To do so, go to your connection details page and uncheck the objects you would like to omit from syncing. For more information, see our Data Blocking documentation.
Alternatively, you can change the permissions of the Fivetran user you created and restrict its access to certain tables or columns.
How to allow only a subset of tables
In your primary database, you can grant SELECT permissions to the Fivetran user on all tables in a given schema:
GRANT SELECT on SCHEMA::<schema> to fivetran;
or only grant SELECT permissions for a specific table:
GRANT SELECT ON [<schema>].[<table>] TO fivetran;
How to allow only a subset of columns
You can restrict the column access of your database's Fivetran user in two ways:
Grant SELECT permissions only on certain columns:
GRANT SELECT ON [<schema>].[<table>] ([<column 1>], [<column 2>], ...) TO fivetran;Deny SELECT permissions only on certain columns:
GRANT SELECT ON [<schema>].[<table>] TO fivetran; DENY SELECT ON [<schema>].[<table>] ([<column X>], [<column Y>], ...) TO fivetran;
Initial sync
Once connected to your database, the Fivetran connector copies all rows from every table in every schema for which a Fivetran user has SELECT permissions (except for those you have excluded in your Fivetran dashboard) and sends them to your destination. Additionally, we add Fivetran-generated columns to every table in your destination offering visibility into the state of your data during the syncs.
Updating data
Fivetran performs incremental updates by extracting new or modified data from your source database's transaction log files using one of the following proprietary capture methods:
- Direct Capture: This method captures changes directly from SQL Server's online transaction logs.
- Archive Log Only: This method captures changes from SQL Server's transaction log backups. We do not read anything directly from the online transaction logs, therefore, High-Volume Agent can reside on a separate machine from the SQL Server DBMS.
- The Archive Log Only capture method generally exhibits higher latency than the Direct Capture method because changes can only be captured when the transaction log backup file is created. While this capture method enables high-performance log-based Change Data Capture (CDC) with minimal operating system and database privileges, it comes at the cost of higher capture latency.
- We automatically enable CDC tables for the SQL Server to log the primary key during updates. However, we disable the process that populates the CDC tables, so they will not contain any actual data. This approach does not add any additional load to the database server and differs from running SQL Server's native CDC replication.
You can replicate large volumes of data from the SQL Server transaction log with minimal impact on your source database using the Binary Log Reader method.
Tables with a primary key
We merge changes to tables with primary keys into the corresponding tables in your destination:
- An
INSERTin the source table generates a new row in the destination with_fivetran_deleted = FALSE - A
DELETEin the source table updates the corresponding row in the destination with_fivetran_deleted = TRUE - An
UPDATEin the source table updates the corresponding row in the destination
Tables without a primary key
If there are one or more non-nullable unique indexes, we use the first available index as the primary key. Otherwise, we use the _fivetran_id as the primary key.
When _fivetran_id is the primary key, the data is handled as follows:
- An
INSERTin the source table generates a new row in the destination with_fivetran_deleted = FALSE. - The
_fivetran_idcolumn helps us handleDELETEoperations:- If there is a row in the destination that has a corresponding
_fivetran_idvalue, that row is updated with_fivetran_deleted = TRUE. - If there is not a row in the destination that has a corresponding
_fivetran_idvalue, a new row is added with_fivetran_deleted = TRUE.
- If there is a row in the destination that has a corresponding
- An
UPDATEin the source table is treated as aDELETEfollowed by anINSERT, so it results in two rows in the destination:- A row containing the old values with
_fivetran_deleted = TRUE - A row containing the new values with
_fivetran_deleted = FALSE
- A row containing the old values with
As a result, one record in your source database may have several corresponding rows in your destination. For example, suppose you have a products table in your source database with no primary key:
| description | quantity |
|---|---|
| Shrink-ray gun | 1 |
| Boogie robot | 2 |
| Cookie robot | 3 |
You load this table into your destination during your initial sync, creating this destination table:
| description | quantity | _fivetran_synced | _fivetran_index | _fivetran_deleted | _fivetran_id |
|---|---|---|---|---|---|
| Shrink-ray gun | 1 | '2000-01-01 00:00:00' | 0 | FALSE | asdf |
| Cookie robot | 2 | '2000-01-01 00:00:00' | 1 | FALSE | dfdf |
| Boogie robot | 3 | '2000-01-01 00:00:00' | 2 | FALSE | ewra |
You then update a row:
UPDATE products SET quantity = 4 WHERE description = 'Cookie robot';
After your UPDATE operation, your destination table will look like this:
| description | quantity | _fivetran_synced | _fivetran_index | _fivetran_deleted | _fivetran_id |
|---|---|---|---|---|---|
| Shrink-ray gun | 1 | '2000-01-01 00:00:00' | 0 | FALSE | asdf |
| Cookie robot | 2 | '2000-01-01 00:00:00' | 3 | TRUE | dfdf |
| Boogie robot | 3 | '2000-01-01 00:00:00' | 2 | FALSE | ewra |
| Cookie robot | 4 | '2000-01-01 00:00:00' | 4 | FALSE | zxfd |
You then delete a row:
DELETE FROM products WHERE description = 'Boogie robot';
After your DELETE operation, your destination table will look like this:
| description | quantity | _fivetran_synced | _fivetran_index | _fivetran_deleted | _fivetran_id |
|---|---|---|---|---|---|
| Shrink-ray gun | 1 | '2000-01-01 00:00:00' | 0 | FALSE | asdf |
| Cookie robot | 2 | '2000-01-01 00:00:02' | 3 | TRUE | dfdf |
| Cookie robot | 4 | '2000-01-01 00:00:02' | 4 | FALSE | zxfd |
| Boogie robot | 3 | '2000-01-01 00:00:02' | 5 | TRUE | ewra |
So, while there may be just one record in your source database where description = Cookie robot, there are two in your destination - an old version where _fivetran_deleted = TRUE, and a new version where _fivetran_deleted = FALSE.
We also de-duplicate rows before we load them into your destination. We use the _fivetran_id field, which is the hash of the non-Fivetran values in every row, to avoid creating multiple rows with identical contents. If, for example, you have the following table in your source:
| description | quantity |
|---|---|
| Shrink-ray gun | 1 |
| Shrink-ray gun | 1 |
| Shrink-ray gun | 1 |
Then your destination table will look like this:
| description | quantity | _fivetran_synced | _fivetran_index | _fivetran_deleted | _fivetran_id |
|---|---|---|---|---|---|
| Shrink-ray gun | 1 | '2000-01-01 00:00:00' | 0 | FALSE | asdf |
Deleted rows
We don't delete rows from the destination, though the way we process deletes differs for tables with primary keys and tables without a primary key.
Deleted columns
We do not delete columns from your destination. When a column is deleted from the source table, we replace the existing values in the corresponding destination column with NULL values.
Table truncation
SQL Server does not allow truncation of tables tracked by Change Data Capture (CDC). To truncate a table, you must first disable CDC, which also removes the log history needed to track the operation.
Because there is no record of the truncation, we cannot replicate it. If a table is truncated, Fivetran will automatically trigger a full resync to restore the data.
Log truncation
HVA uses the transaction log for replication. To maintain optimal performance and prevent excessive disk space consumption, the truncation log must be truncated periodically.
HVA automatically selects the most suitable method to advance the replication truncation point, based on the specific configuration of your database. The following table provides detailed information about each log truncation method, including key considerations such as who controls log truncation, whether CDC jobs are dropped, and user responsibilities.
The CAP_JOB_RETAIN and NATIVE_DBMS_AGENT methods are in Private Preview phase. Contact our support team to enable this functionality for you.
| Log truncation method | Database Configuration | Are CDC jobs dropped? | Who controls log truncation | User Responsibilities | Additional notes |
|---|---|---|---|---|---|
CAP_JOB | Full Recovery model | Yes | Fivetran controls truncation. HVA moves the replication point during sync. If changes are not in the log, HVA reads from backups. | Run regular backups to truncate the log. | If sync isn't running, the log grows because the truncation point isn't released. |
CAP_JOB_RETAIN | Simple Recovery model | Yes | Fivetran controls truncation. HVA moves the replication point during sync. | Run regular backups to truncate the log. | If sync isn't running, the log grows because the truncation point isn't released. |
LOGRELEASE_TASK | Archive Log Only capture method or read-only secondary replica in Always On Availability Group | Yes | User controls truncation. HVA reads from log backups but doesn’t advance the truncation point. | The user-defined task that releases the truncation point must run even if sync isn’t active. | Works with other CDC/replication solutions if the task meet their requirements. |
NATIVE_DBMS_AGENT | SQL Server's native replication or non-HVA CDC usage. | No | User controls truncation. HVA doesn’t interfere with native jobs. | Ensure the native CDC or replication agent advances the truncation point. Run regular backups to truncate the log. | Using CDC tables for supplemental logging can cause I/O overhead as each change is logged to all CDC tables. CDC instances created by HVA are named hvr_<object_id>. |
Manual log truncation
To manually advance the replication truncation point, create a job to run the sp_repldone procedure.
EXEC sp_repldone @xactid = NULL, @xact_segno = NULL, @numtrans = 0, @time = 0, @reset = 1
While the sp_repldone procedure does not truncate the transaction log, it moves the replication truncation point so that subsequent backups or log management tasks can perform truncation.
After running the sp_repldone procedure, ensure the session used to execute the command is closed. SQL Server associates the execution of sp_repldone with the session in which it was run. If the session remains open, it holds a lock on the replication truncation point, preventing other processes, such as HVA, from functioning correctly.
Log truncation method: decision flowchart
This flowchart illustrates the decision-making process we use to determine the appropriate method to advance the replication truncation point based on your database configuration. For detailed information about each method, refer to the table above.
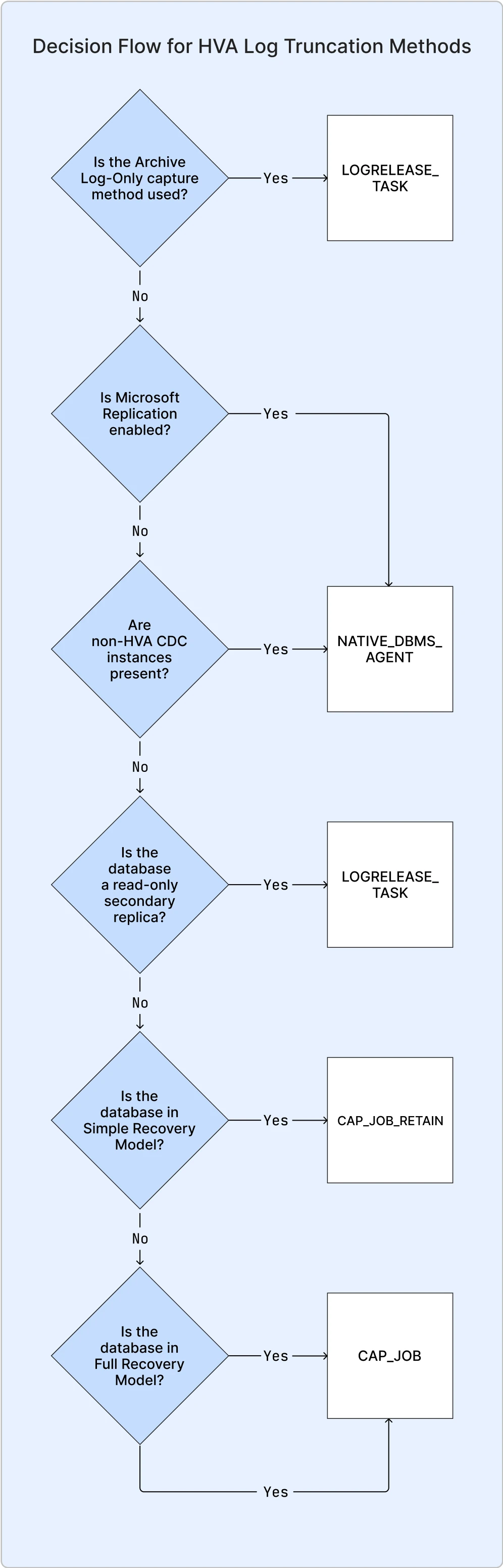
Read-only secondary replica indicates whether the database is a read-only secondary replica in an Always On Availability Group, used for failover and offloading read workloads while restricting data modifications..
FAQ and Troubleshooting
Why does HVA drop CDC capture jobs?
HVA drops CDC capture jobs to avoid conflicts with its change data capture process. This ensures smooth operation and prevents duplication of effort.
What happens if CDC jobs are not named using HVA conventions?
HVA recognizes CDC jobs created with its naming convention (hvr_<object_id>). Jobs outside this convention are not managed automatically by HVA.
How does HVA handle adding new tables to replication?
When new tables are added to an existing replication setup:
- Review whether CDC jobs for the new tables are required.
- Verify that the truncation point is not held unnecessarily due to conflicting configurations.
How frequently should log truncation occur?
The frequency of log truncation depends on how long you intend to retain transactions and your available disk space. To ensure all transactions are processed, log truncation should not occur more frequently than your connection sync frequency. It is recommended to set a log retention period of a few days.
Changing recovery model
When switching the database recovery model from full to either bulk-logged or simple, the format of the transaction logs changes. This can cause your connection to fail. To resolve this issue, you should revert the recovery model back to full and then initiate the connection resync. This is required to ensure full integrity of the delivered data.
Migrating service providers
If you want to migrate service providers, you need to do a full re-sync of your data because the new service provider won't retain the same change tracking data as your original SQL Server database.