How to Set up a Schema Before the Initial Sync
You can control your connection schema by excluding schemas, tables, and columns from replicating before the initial sync starts.
Capturing the schema is not required for database connectors and the following connectors, which behave similarly to databases:
Use the How to Select Columns to Sync and Block New Tables and Columns for New Connections Troubleshooting page for the schema setup of the noted connections.
The new flow of the data blocking strategy is shown in the following diagram:
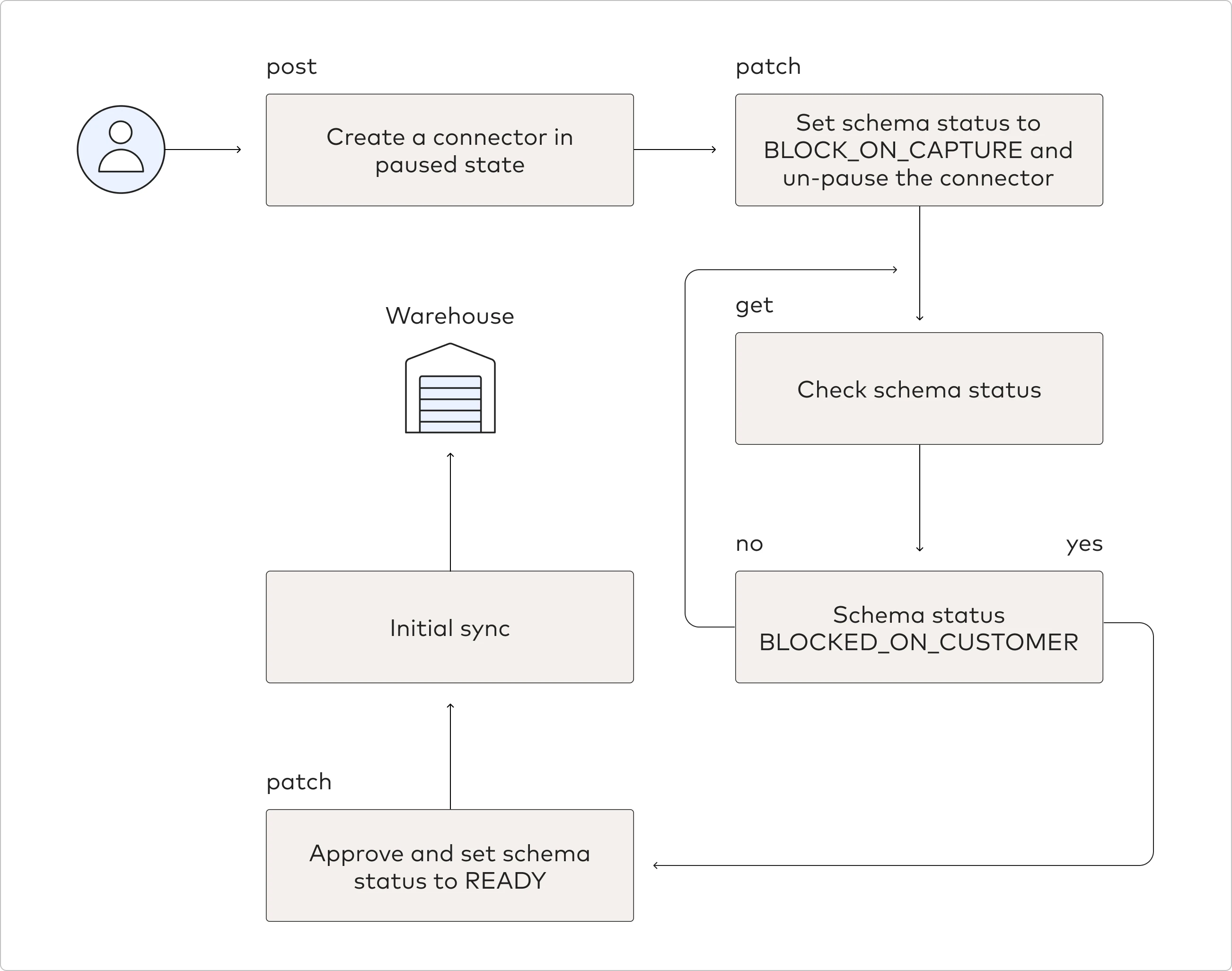
In order to capture the connection schema before the initial sync, you must take several steps:
Create new connection
Create a new connection in a paused state and authorize it using available methods supported by the connection.
Request
POST https://api.fivetran.com/v1/connections
{
"service": "github",
"group_id": "target_group_id",
"paused": true,
"config": {
"schema": "test_github",
"sync_mode": "SpecificRepositories",
"repositories": ["12345678", "23456789"],
"use_webhooks": false
}
}
The contents of the config section vary depending on the connection you use.
Response
{
"code": "Success",
"data": {
"id": "test_connection_id",
"group_id": "target_group_id",
"service": "github",
"service_version": 0,
"schema": "test_github",
...,
"status": {
"setup_state": "connected",
"schema_status": "ready",
"sync_state": "paused",
"update_state": "on_schedule",
"is_historical_sync": true,
"tasks": [],
"warnings": []
},
...,
}
}
Run connection setup tests
Run connection setup tests using Run Connection Setup Tests endpoint.
Request
POST https://api.fivetran.com/v1/connections/{connection_id}/test
{
"trust_certificates": true,
"trust_fingerprints": true
}
Response
{
"code": "Success",
"message": "Setup tests were completed",
"data": {
"id": "speak_inexpensive",
"group_id": "projected_sickle",
"service": "criteo",
"service_version": 0,
"schema": "criteo",
"paused": false,
"pause_after_trial": true,
"connected_by": "interment_burdensome",
"created_at": "2018-12-01T15:43:29.013729Z",
"succeeded_at": null,
"failed_at": null,
"sync_frequency":60,
"status": {
"setup_state": "incomplete",
"sync_state": "scheduled",
"update_state": "on_schedule",
"is_historical_sync": true,
"tasks": [],
"warnings": []
},
"setup_tests": [{
"title": "Validate Login",
"status": "FAILED",
"message": "Invalid login credentials"
}],
"config": {
"username": "newuser",
"password": "******",
"api_token": "******",
"service_version": "0"
}
}
}
Update schema status
Update the schema status to blocked_on_capture and unpause your connection to capture its schema.
Request
PATCH https://api.fivetran.com/v1/connections/{connection_id}
{
"schema_status": "blocked_on_capture",
"paused": false
}
Response
{
"code": "Success",
"message": "Connection has been updated",
"data": {
"id": "test_connection_id",
"group_id": "target_group_id",
"service": "github",
"service_version": 0,
"schema": "test_github",
...,
"status": {
"setup_state": "connected",
"schema_status": "blocked_on_capture",
"sync_state": "scheduled",
"update_state": "on_schedule",
"is_historical_sync": true,
"tasks": [],
"warnings": []
}
}
}
Check connection schema status
Check the connection schema status to verify the schema has been captured. Wait for the schema status to become blocked_on_customer. The time it takes to capture the schema depends on the amount of data in the connection source.
Request
GET https://api.fivetran.com/v1/connections/{connection_id}
Response
{
"code": "Success",
"data": {
"id": "test_connection_id",
"group_id": "target_group_id",
"service": "github",
"service_version": 0,
"schema": "test_github",
...,
"status": {
"setup_state": "connected",
"schema_status": "blocked_on_customer",
"sync_state": "scheduled",
"update_state": "on_schedule",
"is_historical_sync": false,
"tasks": [],
"warnings": []
},
...,
}
}
Decide what data blocking strategy you want to use
Decide what data blocking strategy you want to use for new schemas, tables, and columns that appear in the connection source. This strategy is specified by schema_change_handling API parameter, which has the following possible values:
ALLOW_ALL- all new schemas, tables, and columns which appear in the source after the initial setup are included in syncs;ALLOW_COLUMNS- all new schemas and tables which appear in the source after the initial setup are excluded from syncs, but new columns are included;BLOCK_ALL- all new schemas, tables, and columns which appear in the source after the initial setup are excluded from syncs.
(Optional) Reload connection schema
If you want to use BLOCK_ALL, you may need to exclude existing objects from sync. Reload the schema config using the Reload a Connection Schema Config endpoint. In the payload, specify EXCLUDE as a value for the exclude_mode parameter.
Skip this step if you want to use ALLOW_ALL or ALLOW_COLUMNS.
Request
POST https://api.fivetran.com/v1/connections/{connection_id}/schemas/reload
{
"exclude_mode": "EXCLUDE"
}
Response
{
"code": "Success",
"data": {
"schema_change_handling": "ALLOW_ALL",
"schemas": {
"test_github": {
"name_in_destination": "test_github",
"enabled": false,
"tables": {
"card": {
"name_in_destination": "card",
"enabled": false,
"enabled_patch_settings": {
"allowed": true
}
},
"commit": {
"name_in_destination": "commit",
"enabled": false,
"enabled_patch_settings": {
"allowed": true
}
},
...
}
}
}
}
}
Review your connection schema
Review your connection schema and exclude from replicating those schemas, tables, and columns that you don't want to be delivered to the destination. You can use the following endpoints to do this:
- Retrieve a connection schema config
- Retrieve source table columns config
- Update a connection schema config
- Update a connection database schema config
- Update a connection table config
- Update a connection column config
For example, use the following request to exclude some table:
Request
PATCH https://api.fivetran.com/v1/connections/{connection_id}/schemas/{schema}/tables/{table}
{
"enabled": false
}
Response
{
"code": "Success",
"data": {
"schema_change_handling": "ALLOW_ALL",
"schemas": {
"test_github": {
"name_in_destination": "test_github",
"enabled": true,
"tables": {
"card": {
"name_in_destination": "card",
"enabled": false,
"enabled_patch_settings": {
"allowed": true
}
},
"commit": {
"name_in_destination": "commit",
"enabled": true,
"enabled_patch_settings": {
"allowed": true
}
},
...
}
}
}
}
}
If you are using BLOCK_ALL, you need to enable all required schemas, tables, and columns explicitly. If you don't specify "enabled": "true" for any object, it will not be synced in this mode. If you are using other modes, this is not required: for example, in the ALLOW_ALL mode, you don't have to enable anything explicitly, all objects will be synced by default.
Specify Schema Change Handling strategy
Specify the Schema Change Handling strategy which you have chosen previously. Default strategy is ALLOW_ALL. To specify BLOCK_ALL, for example, use the following request:
Request
PATCH https://api.fivetran.com/v1/connections/{connection_id}/schemas
{
"schema_change_handling": "BLOCK_ALL"
}
Response
{
"code": "Success",
"data": {
"schema_change_handling": "BLOCK_ALL"
}
}
(Optional) Editing columns for system tables
If the table state is not defined, then you can edit columns in system tables using the Schema Change Handling strategy, for example, the body column for Jira connector:
PATCH https://api.fivetran.com/v1/connections/{connection_id}/schemas
{
"schema_change_handling": "ALLOW_ALL",
"schemas": {
"jira": {
"tables": {
"comment": {
"columns": {
"body": {
"enabled": "false"
}
}
}
}
}
}
}
Response
{
"code": "Success",
"data": {
"schema_change_handling": "ALLOW_ALL"
}
}
Unblock schema
Once you've reviewed your connection schema, you will need to unblock the schema by setting schema_status to ready to run the connection sync on schedule.
Request
PATCH https://api.fivetran.com/v1/connections/{connection_id}
{
"schema_status": "ready"
}
Response
{
"code": "Success",
"message": "Connection has been updated",
"data": {
"id": "test_connection_id",
"group_id": "target_group_id",
"service": "github",
"service_version": 0,
"schema": "test_github",
...,
"status": {
"setup_state": "connected",
"schema_status": "ready",
"sync_state": "scheduled",
"update_state": "on_schedule",
"is_historical_sync": false,
"tasks": [],
"warnings": []
}
}
}
Sync connection data
If you want to run the connection sync immediately after the schema status change, you can do so using the Sync Connection Data endpoint.
Request
POST https://api.fivetran.com/v1/connections/{connection_id}/sync
{
"force": true
}
Response
{
"code": "Success",
"message": "Sync has been successfully triggered for connection with id test_connection_id"
}