Azure Blob Storage Setup Guide
Follow our setup guide to connect your Azure Blob Storage or Azure Data Lake Storage Gen2 (ADLS Gen2) to Fivetran.
Prerequisites
To connect Azure Blob Storage to Fivetran, you need:
- An Azure Blob container holding files with supported file types and encodings
- The ability to grant Fivetran the ability to read and list files from this container
Setup instructions
Select authentication method
Microsoft Entra ID
Open the Azure Portal.
Go to Microsoft Entra ID, and in the left navigation pane, click App registrations.
Click New registration.
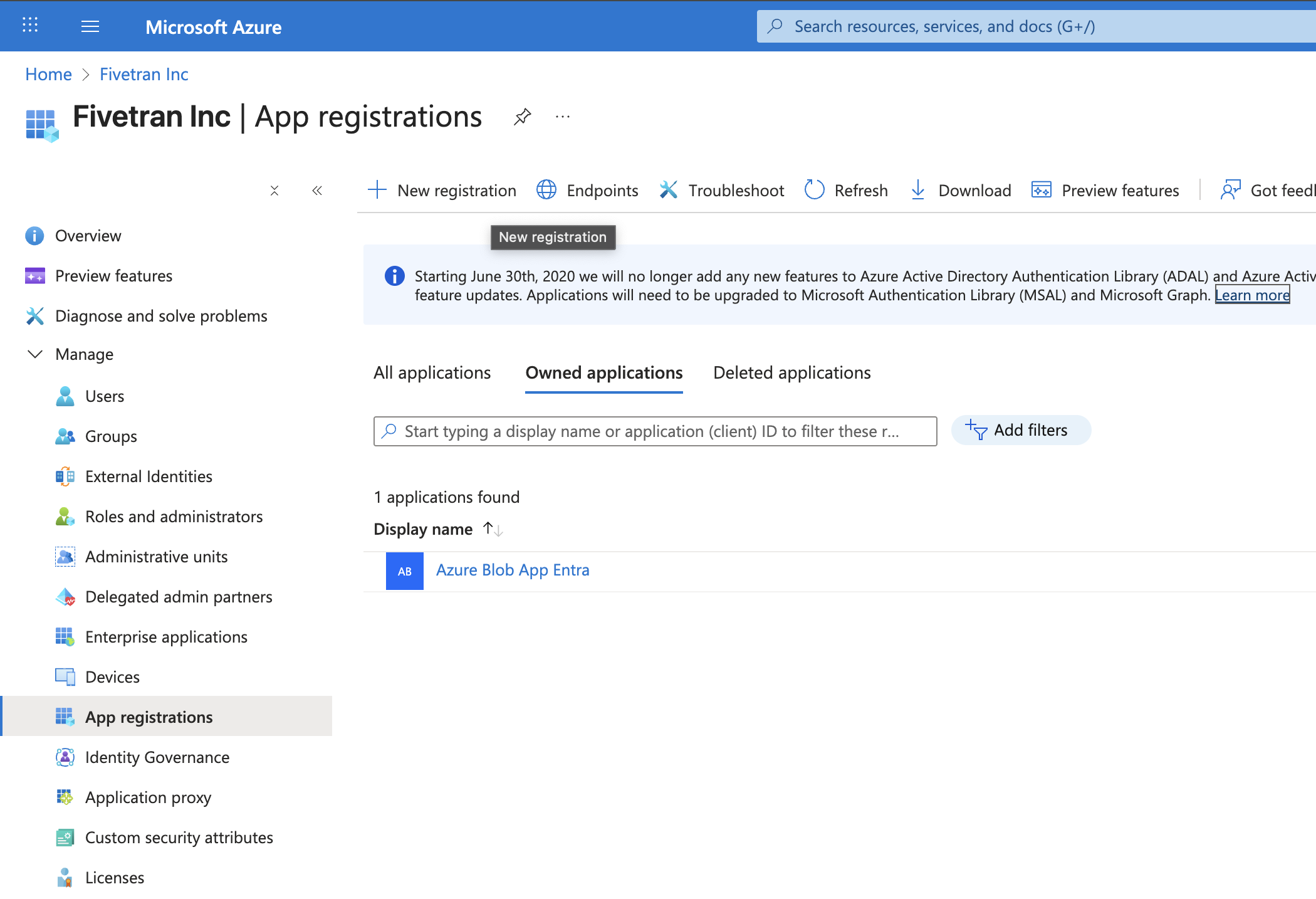
Enter the name for your application, choose the supported account types, and register the application.
Go to the app's Overview page, make a note of the Application (client) ID and Directory (tenant) ID. You will need them to configure Fivetran.
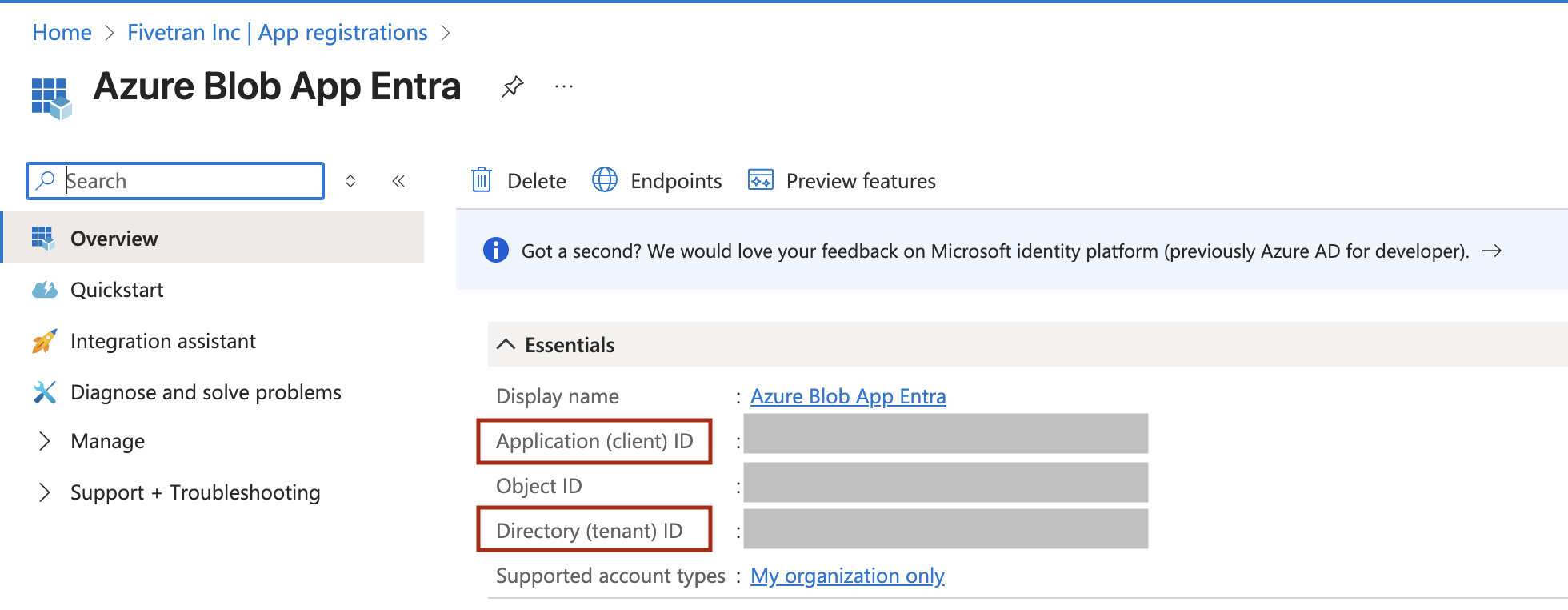
On the left navigation pane, under Manage, click Certificates & secrets.
On the Certificates & secrets page, click New client secret.
Enter a description for your client secret, choose an expiration period, then click Add. Make a note of the secret, you will need it to configure Fivetran.
Go to Azure Portal, navigate to Storage Accounts, select your storage account. Make a note of the Storage account name, you will need it to configure Fivetran.
Go to Storage browser > Blob containers, and select the container you want Fivetran to access.
Go to Access Control (IAM), select + Add, and then click Add role assignment.
On the Add role assignment tab, do the following:
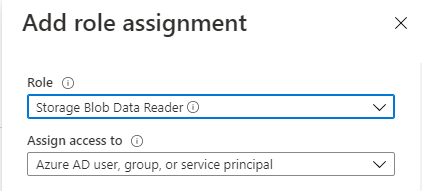
- Role: Select Storage Blob Data Reader from the drop-down.
- Assign access to: Select Azure AD user, group, or service principal from the drop-down.
Connection String
- Create shared access signature in Azure
- You can re-use the Shared Access Signature (SAS) across multiple Fivetran connections.
Open the Azure Portal.
Select your storage account and click Shared access signature.
Select Blob from the Allowed services options.
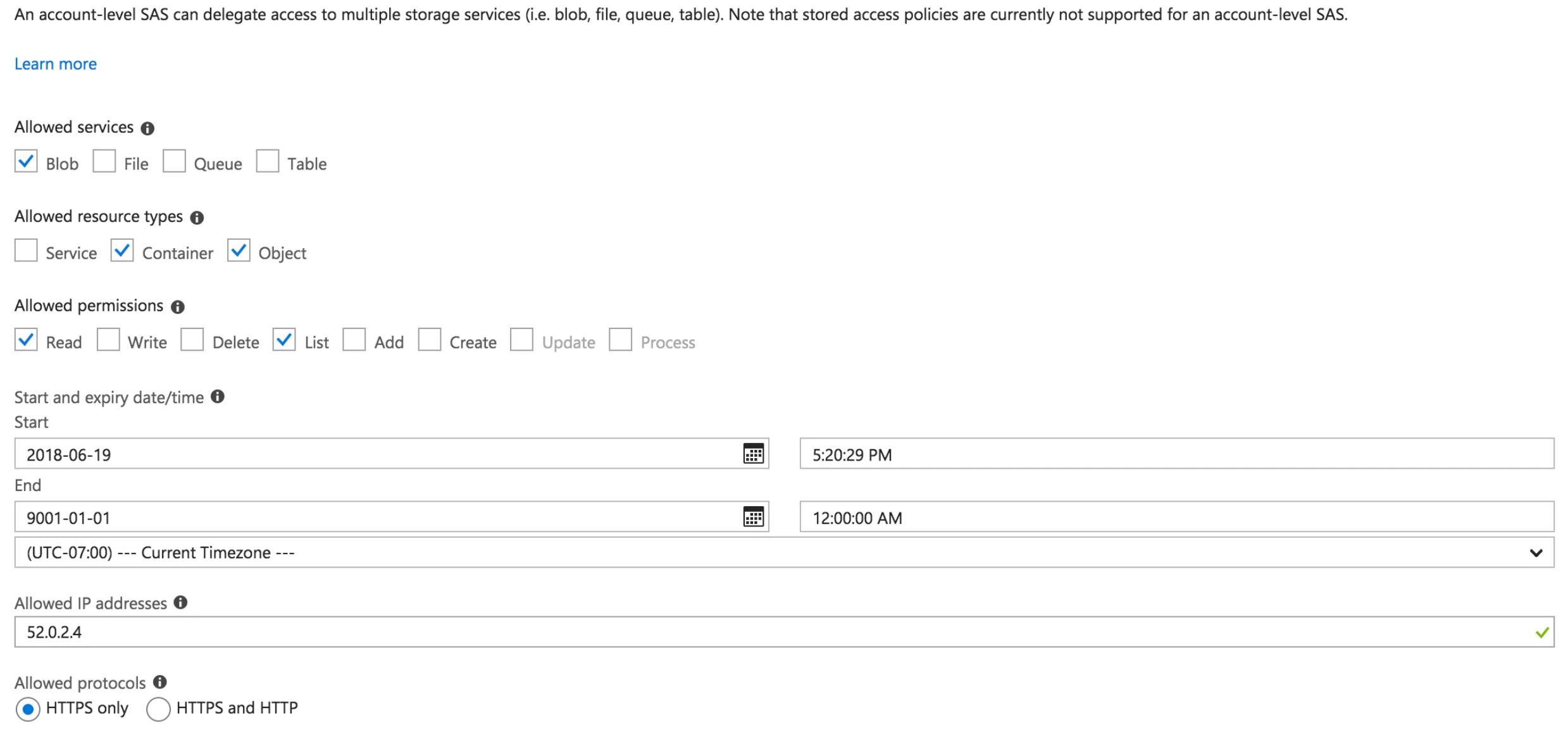
Select Container and Object from the Allowed resource types options.
Select Read and List from the Allowed permissions options.
Choose the appropriate start and expiry dates of your SAS.
When the SAS expires, you will have to update your Azure Blob Storage connector to resume syncing files.
(Optional) To enhance security, safelist Fivetran's IP address range under Allowed IP addresses. Azure only allows one IP range per SAS token. Skip this step if you have already configured Fivetran's internal virtual network subnets.
Use the IP range format to safelist the IP addresses, for example,
35.234.176.144-35.234.176.151, because the CIDR format, for example,35.234.176.144/29, is not supported in the Azure Portal.Select HTTPS only from the Allowed protocols options. We recommend that you select HTTPS only to ensure the security of your files.
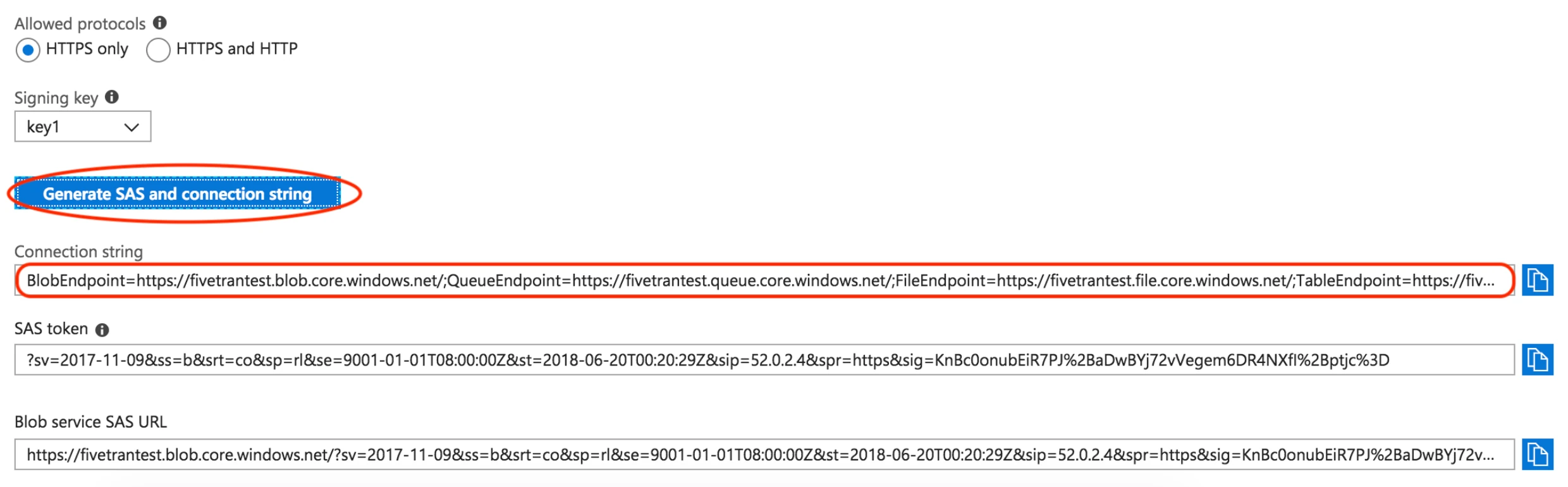
Click Generate SAS and connection string.
Make a note of the Connection string value. You need it to configure Fivetran.
Select connection method
The Connection Method option is only available for Business Critical accounts.
First, decide whether to connect Fivetran to your Azure Blob container directly, using an SSH tunnel, or using Azure Private Link.
Connect directly
Fivetran connects directly to your Azure Blob container. This is the simplest connection method.
If you have a firewall enabled, create a firewall rule to allow access to Fivetran's IPs.
If you have a firewall enabled and your Fivetran instance is configured to run in the same region as your Azure Storage Account, you need to configure virtual network rules and add Fivetran's internal virtual network subnets to the list of allowed virtual networks. Learn more in the Microsoft documentation. Reach out to support in order to retrieve the list of region-specific fully qualified subnet IDs.
Connect using Private Link
You must have a Business Critical plan to use Azure Private Link.
Azure Private Link allows Virtual Networks (VNets) and Azure-hosted or on-premises services to communicate with one another without exposing traffic to the public internet. Learn more in the Microsoft Azure Private Link documentation.
Follow our Azure Private Link setup guide to configure Private Link for your Azure Blob container.
Connect using SSH (TLS optional)
Fivetran connects to a separate server in your network that provides an SSH tunnel to your Azure Blob container. You must connect through SSH if your container is in an inaccessible subnet on a virtual network.
To connect using SSH, create a firewall rule to allow access to your SSH tunnel server's IP address.
Before you proceed to the next step, you must follow our SSH connection instructions to give Fivetran access to your SSH tunnel. If you want Fivetran to tunnel SSH over TLS, follow the Azure TLS setup instructions to enforce a minimum TLS required version on your namespace.
Finish Fivetran configuration
- In the connection setup form, enter your Destination schema name.
- Enter the Table group name. We combine this with the destination schema to form the Fivetran connection name
<destination_schema>.<table_group_name>. This enables you to create multiple Merge Mode connections per destination schema. The Table group name value is used only in Fivetran and does not appear in your destination. In the Destination schema names field, choose the naming convention you want Fivetran to use for the schemas, tables, and columns in your destination:
- Fivetran naming: Standardizes the schema, table, and column names in your destination according to the Fivetran naming conventions.
- Source naming: Preserves the original column names from the source system in your destination. The source naming rules apply only to the column names, while the schema and table names follow the Fivetran naming rules.
If you want to modify your selection, make sure you do it before you start the initial sync.
Connect
Choose your Authentication method.
- If you have chosen Microsoft Entra ID - Service Principal Secret as Authentication method:
- Enter the Container name.
- Enter your Storage account name.
- Enter your Tenant ID.
- Enter your Client ID.
- Enter your Client secret.
- If you have chosen Connection String as Authentication method:
- Enter the Container name.
- Enter the Connection string you found in Azure.
- If you have chosen Microsoft Entra ID - Service Principal Secret as Authentication method:
If you're on a Business Critical plan, choose how Fivetran should connect to your Azure Blob container. You can choose to:
Connect directly
Connect via Private Link
- (Not applicable to Hybrid Deployment) Connect via SSH tunnel. If you chose Connect via SSH Tunnel, do the following:
- Enter the IP address of storage container (or the domain address )
- Enter the IP address of host tunnel machine
- Enter the username of account in host tunnel machine
- Copy the Public Key from the connection setup form and paste it into the
.ssh/authorized_keysfile inside the home folder on the tunnel machine.
For connectors configured for Hybrid Deployment, Connect directly is pre-selected in the Connection Method field.
(Optional) Base folder path - Choose the lowest common folder in a folder hierarchy that includes all the files you want to sync and enter it in the Base folder path field. This defines a specific location where Fivetran scans for files and helps ensure optimal performance. For example, if the files are in
files/exports/customers/data_20251016.csvandfiles/exports/products/data_20251016.csv, setfiles/exportsas the base folder path.(Optional) Click Run connection test to validate the login credentials, the connection to the Azure Blob container, and that the Base folder path exists.
You can skip this intermediate test and proceed to the next step. However, if you choose to skip, we will perform this test once you have finished your configuration.
Format
File Type - We process all files as the selected file type. Use the File Pattern field to select the file extensions you want to sync.
If you select XML, we load your XML data into the
_datacolumn without flattening it.If you select XLS/XLSX/XLSM, proceed to the Configure Files section to determine how you want to analyze your spreadsheet.
We do not support dynamic table mapping for XLS/XLSX/XLSM files.
If you select CSV or TSV, then enter the following details:
- (Optional) Delimiter - Specify the delimiter used in your CSV file. If your CSV file uses a custom delimiter, replace the default comma
,with your specific delimiter. For example, if your file is tab-delimited, enter\t, or if it's pipe-delimited, enter|. If you leave this field blank, we'll attempt to detect the delimiter for each file automatically. However, note that automatic detection may not work in all cases. If your files sync with an incorrect number of columns or use a unique delimiter, consider specifying the delimiter. You can store files with different delimiters in the same folder. For more details on how delimiter inference works, see our documentation. - Quote character - Typically, CSVs use double quotes
"to enclose a value. Set the toggle to off if you don't want to use an enclosing character. - Non-Standard escape character - Set the toggle to ON if your CSV generator uses non-standard ways of escaping characters like newline, delimiter, etc. Not standard in CSVs.
- Null Sequence - Set the toggle to ON if your CSVs use a special value indicating null. Specify the value indicating null only if you are sure your CSVs have a null sequence. Typically, CSVs have no native notion of a null character. However, some CSV generators have created one, using characters such as
\Nto represent null. - Skip Header Lines - Use this option to skip over a fixed number of header lines at the beginning of your CSV files. Set the toggle to ON, and then in the Number of skipped header lines field, specify the number of header lines you want to skip.
- Skip Footer Lines - Use this option to skip over a fixed number of footer lines at the end of your CSV files. Set the toggle to ON, and then in the Number of skipped footer lines field, specify the number of footer lines you want to skip.
- Headerless files - Set the toggle to ON if your CSV-generating software doesn't provide a header line. Fivetran can generate generic column names and sync data rows with them.
- Line Separator - Line separators are used in CSV files to separate one row from the next. By default, we use the new line character
\nas the line separator. If you use a different line separator for your CSV files, replace\nwith your custom line separator.
- (Optional) Delimiter - Specify the delimiter used in your CSV file. If your CSV file uses a custom delimiter, replace the default comma
If your file type is JSON or JSONL, then choose one of the following:
JSON Delivery Mode - Use this option to choose how Fivetran should handle your JSON data.
- If you select Packed, we load all your JSON data into the
_datacolumn without flattening it. - If you select Unpacked, we flatten one level of columns and infer their data types.
- If you select Packed, we load all your JSON data into the
Configure files
Choose your configuration options. Using these configuration options, you can select subsets of your folders, specific types of files, and more to sync only the files you need in your destination. In addition, setting up multiple connectors targeted at the same container but with different options allows you to slice and dice a container any way you'd like.
File Mapping - You can map the files to a destination using the following options:
Define per table
Select Define per table.
Click + Add files to specify destination tables and their corresponding file name pattern.
Table name - Use names that are unique across all Azure Blob Storage connections within the same destination schema.
(Optional) File pattern - Use a regular expression as the file pattern to determine whether to sync specific files. The pattern you specify applies to everything under the prefix (base folder path). If you want to sync everything under the prefix, leave this field blank.
For example, if under the prefix you have a folder
data, which has sub-folders,subFolder1,subFolder2, etc. These sub-folders have JSON files with the formatreport_03/12/2050.json. Use the following regex patterns to decide whether or not to sync specific files:data/.*matches all files in the data folder, including those in subfolders.data/.*jsonmatches all JSON files in the data folder, including those in subfolders.data/subFolder2/report_.*\.jsonmatches all the JSON files in thesubFolder2folder that have a name that starts with the prefixreport_.. For example,report_file.json.report_\d{2}/\d{2}/\d{4}\.jsonmatches all the JSON files that begin with the prefixreport_and are followed by a date format ofDD/MM/YYYYorMM/DD/YYYY. For example,report_03/12/2050.json.We recommend that you test your regex.
(Optional) Archive File Pattern - Use a regular expression to filter and sync files from archived folders. We sync the files in compressed archives with filenames matching the specified pattern. For example, if you specify the archive folder pattern as
.*json, we will sync only the files that end in a .json file extension from the archive folder.You need to configure archive patterns per table. This is useful when an archive folder contains files following different naming patterns, allowing you to route each type to a specific destination table based on its pattern.
For example, if the archive folder contains
test12.jsonandcheck12.json, you can configuretest.*\.jsonas archive pattern for Table1 to sync onlytest12.jsonto Table1, andcheck.*\.jsonfor Table2 to sync onlycheck123.jsonto Table2.(Optional) Click Preview Files to validate the file pattern.
You can skip this intermediate test and proceed to the next step. However, if you choose to skip, we will perform this test once you have finished your configuration.
If you have selected XLS/XLSX/XLSM as your file type, we automatically analyze your spreadsheet to identify the cell reference. If you opt to enter a cell reference of your choice, enable the Manually provide cell reference toggle. We use the cell reference to sync all contiguous data starting from the top-left cell in all the spreadsheets matching the name.
- Analyze sheet - Identify the sample file you would want to sync. We analyze and identify the eligible data sets. To determine the cell reference correctly, perform one of the following steps:
Set the Manually provide cell reference toggle to ON to enter the cell reference.
- In the Cell reference for syncs field, enter the cell reference in the
'<sheetName>'!<startColumnName><startRowName>format. For example, if you want to sync data starting from cell 'C3' of the 'Data2' worksheet, enter'Data2'!C3.
- In the Cell reference for syncs field, enter the cell reference in the
In the Spreadsheet to find data to be synced field, enter the path from the root folder of one of your Excel files.
This field is available only when you disable the Manually provide cell reference toggle.
Click Analyze sheet.
In the Cell reference for syncs drop-down menu, select the cell reference.
Learn more about syncing Excel files in our documentation.
Click Save.
- Analyze sheet - Identify the sample file you would want to sync. We analyze and identify the eligible data sets. To determine the cell reference correctly, perform one of the following steps:
Dynamically extract tables
Select Dynamically extract tables.
Use this option to dynamically extract table names from file paths using a regular expression with a named capture group.
Table extraction pattern - Specify a regular expression with a named capture group
(?<table>...)to extract the table name from matching file paths.For example, if your files follow a naming pattern like
20250101/report/customers.csv,20250101/report/orders.csv, etc., you can use the pattern\d{8}/report/(?<table>\w+)\.csv. Fivetran will automatically create separate destination tables for each unique table name extracted from the pattern (e.g.,customers,orders). To learn more about Dynamic File Mapping, see How to use Dynamic File Mapping?We recommend that you test your regex to ensure it correctly captures the table name.
(Optional) Click Preview to validate the regex pattern and see which table names will be extracted from your files. The preview displays one matched file per table with the corresponding table name extracted from the file path.
The preview displays the table names extracted from your files. These names will be converted according to Fivetran's naming conventions when synced to your destination. For more information, see our naming conventions documentation.
Any new tables observed post-setup (i.e. previously unseen table values that match your pattern) will be added automatically. You can control this behavior using Schema change settings.
Primary Key used for file process and load - Use this option to let Fivetran know how you'd like to update the files in your destination. When you modify a previously synced file, the option you select determines if we should replace the rows in the destination table or append new rows to the table:
- If you select Upsert file using file name and line number, we will upsert your data using the surrogate primary keys
_fileand_line. If a file has a unique name, we will sync the data for that file as new data. - If you select Append file using file modified time, we will upsert your files using surrogate primary keys
_file,_line, and_modified. You can track the full history of a file or set of files, and your files will have a combination of old and new data or data that is updated periodically. - If you select Upsert file using custom primary key, you can keep the most recent version of every record, and your files will have a combination of the old and new data or data that is updated periodically. You can choose the primary keys you want to use after you save and test.
You can't modify your primary key option once the initial sync is successful. However, if you selected Upsert file using custom primary key, you can change the columns selected as primary keys after the initial sync.
- If you select Upsert file using file name and line number, we will upsert your data using the surrogate primary keys
Additional options
Compression - If your files are compressed but do not have extensions indicating the compression method, you can decompress them according to the selected compression algorithm.
If all of your compressed files are correctly marked with a matching compression extension (.bz2, .gz, .gzip, .tar, or .zip), you can select infer. If you select uncompressed, we do not decompress the files and sync the uncompressed files. If you choose a compression format, we decompress every file using the format you select. For example, if you have an automated CSV output system that GZIPs files to save space but saves them without a .gzip extension, you can set this field to GZIP. We will decompress every file that we examine using GZIP.
Error Handling - Use the error handling option to choose how to handle errors in your files. If you know that your files contain some errors, you can choose to skip poorly formatted lines.
If you select skip, we ignore improperly formatted data within a file, allowing you to sync only valid data.
If you select fail, we fail the sync with an error when finding any improperly formatted data.
We recommend that you select fail unless you are sure that you have undesirable, malformed data.
You will receive a notification on your Fivetran dashboard if we encounter errors.
(Optional) PGP Encryption Options - Use this option to sync PGP encrypted files. Set the toggle to ON and specify the following:
PGP Private Key - Upload the PGP secret key as an attachment.
(Optional) Passphrase - Enter the passphrase you used to generate the key.
(Optional) Signer's Public Key - Upload the signer's public key as an attachment. This key is used to verify the files.
- For PGP decryption processes, we strictly comply with the RFC4880 standard. We support syncing only base64 encoded files.
- To support PGP encryption on compressed files, the file name must contain both a valid compression extension and the .pgp encryption extension. For example: sample.csv.zip.pgp — where .zip is the compression extension and .pgp is the encryption extension.
(Hybrid Deployment only) If your destination is configured for Hybrid Deployment, the Hybrid Deployment Agent associated with your destination is pre-selected for the connection. To assign a different agent, click Replace agent, select the agent you want to use, and click Use Agent.
Click Save & Test. Fivetran will take it from here and sync your data from your Azure Blob container.
Fivetran tests and validates the Azure connection. On successful completion of the setup tests, you can sync your Azure data to your destination.
Setup tests
Fivetran performs the following Azure connection tests:
The Connectivity test validates your Azure credentials and checks if Fivetran is able to connect to the Azure Blob container via Private Link. We perform this test only if you have configured your connector using Connect via Private Link.
The Connecting to Container test validates the container name you specified in the setup form and checks the accessibility of your Azure Blob container.
Define files per table mode tests:
- The Finding tables test validates if you have specified at least one table in the files field to set up the connection.
- The Validating File Pattern Regex test validates the file pattern regex you specified in the setup form. This test ensures that the regex pattern correctly matches files in your Azure Blob container and routes them to the appropriate destination tables. We perform this test only if you specify a regex in the File Pattern field.
- The Validating Archive Pattern test validates the archive pattern regex you specified in the setup form. This test verifies that the regex pattern correctly filters files within compressed archives and routes them to their designated destination tables. We perform this test only if you specify a regex in the Archive File Pattern field.
- The Finding Matching Files test checks if the connector can successfully retrieve a minimum of one sample file and a maximum of ten sample files for each of the tables you specified in the setup form.
Dynamically extract tables mode tests:
- The Validating Table extraction pattern test validates the regex pattern you specified in the Table extraction pattern field. This test ensures that the pattern is not empty, the pattern is valid regex syntax, and the pattern contains exactly one named capture group called
table. - The Finding Matching Files test checks if the connector can successfully discover files using the table extraction pattern. The test shows up to five tables with up to three sample files per table. The table names displayed are extracted from your files and will be converted according to Fivetran's naming conventions when synced to your destination. For more information, see our naming conventions documentation.
- The Validating Table extraction pattern test validates the regex pattern you specified in the Table extraction pattern field. This test ensures that the pattern is not empty, the pattern is valid regex syntax, and the pattern contains exactly one named capture group called
The Validating EscapeChar test validates the escape character you specified for your CSV files and checks the length of the character which must not be more than one. We perform this test only if you set the Non-standard character escaping? toggle to ON and specify an escape character in the Escape Character field.
The Validating Infer FileType test validates the value of the
file_typeparameter and checks whether you specifiedinferas a value. We perform this test only if you have set up your connector using the API.The Validating Excel Cell Reference Per Table test validates the cell references provided when the toggle is 'ON' per table for Excel file type.
The Multi-Character Delimiter Support test validates the length of the delimiter, which must be within 15 characters. We perform this test only if you specify the delimiter for your CSV files in the Delimiter field.
The PGP Support test validates whether the connector can successfully retrieve a minimum of one sample file and a maximum of ten sample files and decrypt them using the PGP keys you uploaded. We perform this test only if you set the PGP Encryption Options toggle to ON.
The tests may take a couple of minutes to complete.