Webhooks
A webhook is a user-defined HTTP callback triggered by an event on your website or in your application. It allows you to send real-time HTTP notifications from one application to another whenever an event you specify occurs. You can send events using HTTP GET/POST requests to the webhook URL.
An event is data that describes something that happened. As the event occurs, it triggers a small piece of code embedded in the web app that makes an HTTP request (callback) to the URL you configured in the webhook.
With our Webhooks connector, you will get a unique Fivetran URL endpoint that you need to configure into your web app as a callback. You have to register the webhook on your web app to start receiving events. During the registration, provide a name, description, the Fivetran URL, and specify the list of event types you want to capture and sync. Any event that occurs will trigger an HTTP request (containing event data) to the URL endpoint. Our webhook service captures the events. We buffer the events and then push the events to your destination.
Webhooks are predefined instructions and don’t need you to make requests to the web app for data regularly. You just have to set up the webhook once, and your web app sends data whenever it's triggered, meaning you will have almost real-time updates.
For example, if you have a GitHub repository and want to track the various operations happening on the repository. Configure a GitHub webhook with the Fivetran URL. Whenever any user performs any action like push or pull, an event is triggered, GitHub will POST an HTTP request to the pre-configured URL. Our webhook service processes and stores these events in your destination. You can build dashboards using the data and analyze the event data for insights into your repository.
- If an API that we support uses a webhook, we recommend using the API to connect because webhooks circumvent the transformation part of the ETL process.
- We have not optimized our Webhooks connector for a specific source because we built it to be flexible to support and connect with as many APIs as possible.
- We only store the events that we receive after you configure the webhook and cannot fetch historical event data from the web app.
- If there's a service that we don't support (have a connector), but the service has a webhooks API, you can use the service's webhooks to send event data to the Fivetran URL endpoint and we will sync the data to your destination.
Features
| Feature Name | Supported | Notes |
|---|---|---|
| Capture deletes | ||
| History mode | ||
| Custom data | ||
| Data blocking | ||
| Column hashing | ||
| Re-sync | ||
| Row filtering | ||
| API configurable | API configuration | |
| Priority-first sync | ||
| Fivetran data models | ||
| Private networking | ||
| Authorization via API |
Events format
Fivetran supports events in the following formats:
- JSON: We accept events in the form of JSON objects using HTTP POST requests.
- QueryParams: We accept events in the form of query_params using HTTP GET requests. We generate JSON object from the query_params before syncing it to your destination.
- FormData: We accept events in the form of form_data using HTTP POST requests. We generate JSON object from the form_data before syncing it to your destination.
Supported deployment models
We support the SaaS Deployment model for the connector.
Setup guide
Follow our step-by-step Webhooks setup guide to connect webhooks with your destination using Fivetran connectors.
Sync overview
Once events are sent to our webhook endpoint, we process them in our Webhook Pull Service (WPS) infrastructure. We store the events in the WPS until a sync is run. During the sync, files are generated and processed in your chosen container service, then loaded into your destination.
When Fivetran's service container is selected:
- We store data indefinitely in our service container.
When your service container is selected:
- We store the events temporarily in our service container, and then copy them over to your configured storage when the sync is run. After the data has been copied, we delete the data from our service container.
Events sent to the webhook endpoint may take up to 30 minutes to process in our Webhook Pull Service (WPS) infrastructure. Therefore, your _created and _fivetran_synced values may differ:
- The
_createdvalue represents the timestamp when the event is entered in our WPS system. - The
_fivetran_syncedvalue represents when the record was synced to your destination.
Connection mapping
You can use the Webhooks connector to POST arbitrary data directly into your destination. Webhook connections occur at the table level. Each connection that is created within Fivetran (illustrated below in the connection icon circle) is given a specific URL to post data to. Any data posted to that URL is added to a single destination table.
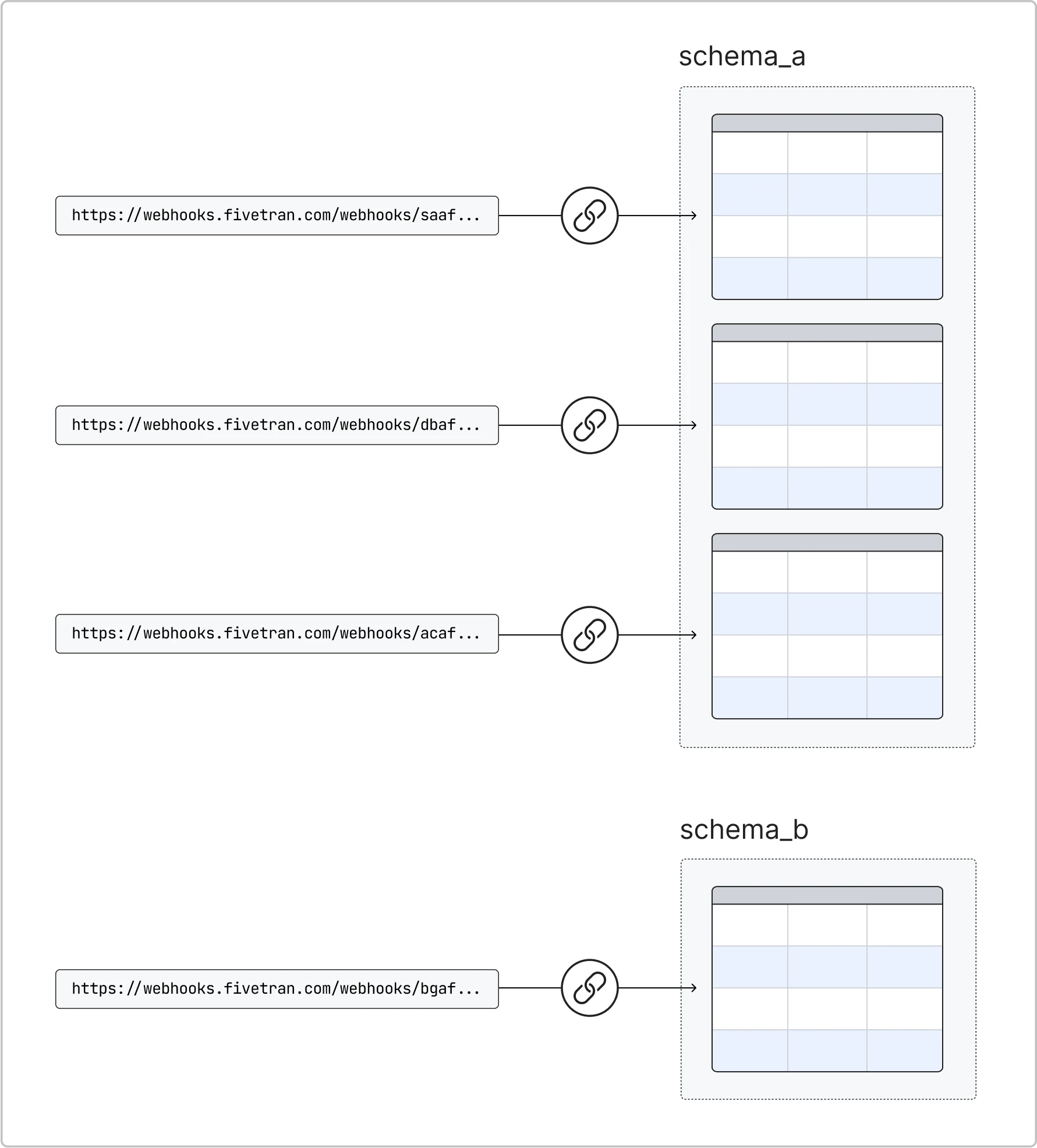
Naming
You can name destination table in the Fivetran dashboard while creating the connection. We create the new destination table for you automatically, and it's best not to have that table already created. You can also designate whichever schema you would like the table to reside in. If the schema that you select does not already exist, we will automatically create it for you in your destination.
Historical data
Webhooks do not allow Fivetran to sync your historical data. We can only capture data from your connection date forward.
Data retention period
Fivetran retains event data from the Webhooks connector and other connectors that use webhooks. We store that data so that it can be re-synced if needed. The data retention period depends on the connector type.
| Connector | Data Retention Period | Note |
|---|---|---|
| AppsFlyer | 30 days | |
| Eloqua | 30 days | |
| Github | 30 days | |
| Greenhouse | 30 days | |
| Help Scout | 30 days | |
| HubSpot | 30 days | |
| Intercom | 30 days | |
| Iterable | 30 days | |
| Jira | 30 days | |
| Pipedrive | 30 days | |
| Recharge | 30 days | |
| Branch | Persistent | |
| Mandrill | Persistent | |
| SendGrid | Persistent | |
| Shopify | Persistent | |
| SurveyMonkey | Persistent | |
| Webhooks | Persistent | |
| Zendesk Support | Persistent |
Packed vs. unpacked data
Fivetran can deliver your data in either packed or unpacked format. Suppose you send the following payload to Fivetran:
{
"foo": 1,
"nested": {
"bar": 2
}
}
Your data can appear in the following two ways - unpacked and packed.
In the tables below, the text in parentheses next to the column name indicates the data type of that column. For example, "foo (INTEGER)" means the column name is foo and it stores INTEGER data.
Unpacked
Fivetran unpacks one layer of nested fields and infers types. This produces a table that looks like:
| _id (INTEGER) | foo (INTEGER) | nested (JSON) |
|---|---|---|
| ? | 1 | {"bar":2} |
Packed
Fivetran loads all your data into a single column. This produces a table that looks like:
| _id (INTEGER) | data (JSON) |
|---|---|
| ? | {"foo":1,"nested":{"bar":2}} |
Batch data
Fivetran can process JSON arrays and deliver separate rows for each array element. Suppose you send the following payload to Fivetran:
[ {
“foo” : 1,
“name” : “John Doe”
}, {
“foo” : 2,
“name” : “Tom Doe”
}, {
“foo” : 3,
“name” : “Emma Doe”
} ]
Fivetran loads 3 rows into the destination. This produces a table that looks like:
Unpacked
| _id (INTEGER) | foo (INTEGER) | name (String) |
|---|---|---|
| ? | 1 | John Doe |
| ? | 2 | Tom Doe |
| ? | 3 | Emma Doe |
Packed
| _id (INTEGER) | data (JSON) |
|---|---|
| ? | {"foo":1,"name":"John Doe"} |
| ? | {"foo":2,"name":"Tom Doe"} |
| ? | {"foo":3,"name":"Emma Doe"} |
Schema information
Because the events you send are completely customizable, you determine how the schema appears. We also support integrating with webhooks through Segment.
For every webhook integration, we create a single table. To have multiple tables in a single schema, you can create multiple webhook connections.
Each table that we create has the following default columns:
| COLUMN | DESCRIPTION |
|---|---|
_created | The timestamp when the event is entered in our WPS system. |
_id | A randomly generated UUID that is assigned to each received event. |
_index | A sequential identifier to distinguish events within a batch, as all these events share the same _id value. For instance, the _index value is 0 for the first event, 1 for the second event, and so on. |
_ip | IP address of the client that sent the event. |
headers | A JSON object containing the HTTP request headers sent with the webhook event. Sensitive headers containing keywords such as auth, token, secret, password, and cookie, as well as authentication headers, are automatically filtered for security. |
Fivetran may send duplicate events to your destination. To prevent this, run a query using an idempotency key generated at the source to filter out the duplicates.
Type transformations and mapping
You can decide the column types and we will faithfully recreate every column that you send to us. Fivetran has some rules for finding the proper data type for a column, detailed below.
Fivetran differentiates between a few types - DATES, INTEGERS, DOUBLES, STRINGS, AND BOOLEANS. We parse the information and make our best guess of the types. If we establish a type during one sync of the integration, and then find that the type was too narrow (for instance, we loaded only integers, but the next sync found decimals), we would "promote" the types to the next-most-narrow type that could logically contain both. In the case of INTEGER and DOUBLE, the DOUBLE type will encapsulate both. See below for a concrete example of Type promotion
We only write ISO 8601 format dates as TIMESTAMP - everything else gets interpreted as a string. For instance, "2016-10-04T16:05:30Z" will be correctly written as a timestamp in the destination, but "2016-10-4 4:05:30PM" will be written as a string.
Type promotions example:
In the following example, assume you had the following values in a column: 0 2 3 We would initially sync this as an integer column. Then, if you loaded in a new value, 27.54, it would be promoted to a double column. Next, suppose you sent along the value "hello". We'd promote one last time up to string. String is the "largest" type - every value can have a string representation.
Excluding source data
You have total control over what is sent to your endpoint, so you can exclude source data by simply not generating unwanted records.