August 2020
History Mode
We have released the beta version of Fivetran history mode. History mode records every version of each record in your destination. With history mode, you can analyze data from a particular point in time or analyze how data has changed over time. The initial release of history mode is available for our Salesforce connector.
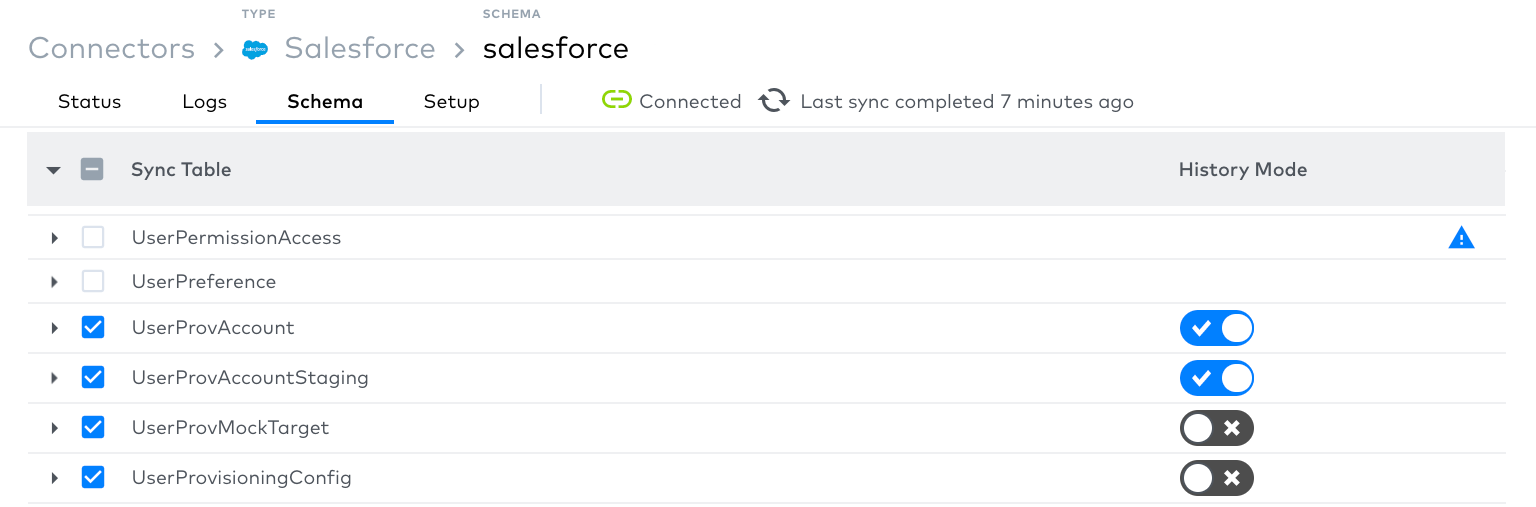
Previously, when a value in the source was updated, the destination was updated as well, and the history of that value was lost. Now, you can turn on history mode for any table in Salesforce to capture all of the changes.
To learn more, read our history mode documentation.
We are gradually rolling out history mode to all Salesforce connections. If you'd like to access history mode immediately, contact our support team.
New Account Permissions
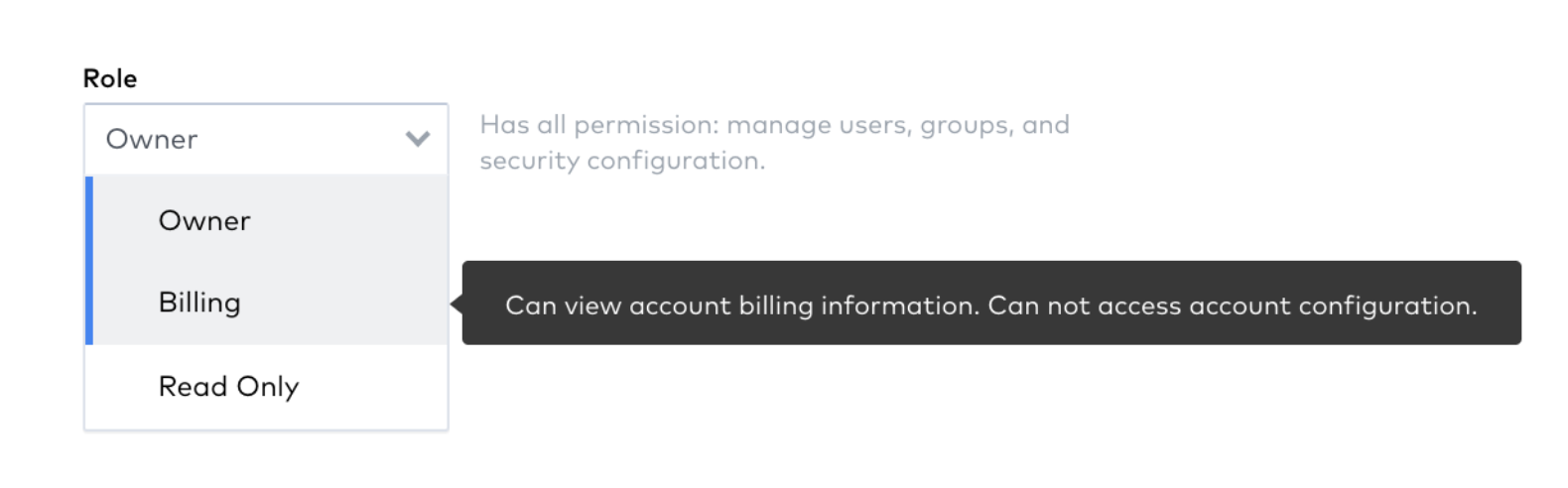
We have added three new account permissions to provide more granular access to your account's billing details:
- View Usage - view the credit consumption and MAR (monthly active rows) for all connectors and destinations in your account
- View Billing - view your account's billing details (such as credit cards or invoices)
- Manage Billing - add a credit card or change your billing plan
We've also added a new Billing user role, which includes the View Billing and View Usage permissions. Learn more in our account permissions documentation.
Schema changes
Braze
We have added a new primary key column, id, to the CANVAS_VARIATION table and added foreign key relationships to the following tables which reference this column:
CAMPAIGNCARDCANVAS_CONVERSION_EVENTCANVAS_ENTRY_EVENTCONTENT_CARD_EVENTEMAIL_EVENTIN_APP_MESSAGE_EVENTPUSH_NOTIFICATION_EVENTSMS_EVENTSUBSCRIPTION_EVENTWEBHOOK_EVENT
We will re-sync the CANVAS_VARIATION table in order to populate this column.
Freshdesk
We have removed the _fivetran_deleted column from the SATISFACTION_RATING and SATISFACTION_RATING_VALUE tables. Now, we incrementally update the SATISFACTION_RATING and SATISFACTION_RATING_VALUE tables in the destination.
Google Ad Manager
We are temporarily discontinuing cms_metadata dimension support.
Jira
We have added a new column, is_public, to the COMMENT table.
Kantata
We have added a new table, TIME_OFF_ENTRY.
Kustomer
We have added two new columns, deleted and deleted_at, to the USER table. You can use the two columns to identify the users that have been deleted from the Kustomer account.
We have added a new column, _fivetran_deleted, to the COMPANY, NOTIFICATION, and CARD tables. The _fivetran_deleted column marks data that was deleted from the Kustomer account.
We have added two new tables, QUEUE and TEAM_QUEUE.
We have added a new column, queue_id, to the CONVERSATION table. The queue_id column stores the foreign key to the QUEUE table.
Optimizely
We have added the following tables to support Enriched Events Export:
DECISIONDECISION_ATTRIBUTECONVERSIONCONVERSION_ATTRIBUTECONVERSION_EXPERIMENTCONVERSION_TAG
We will discontinue the VISITOR_ACTION, RESULT, and RESULT_SEGMENT tables after November 15, 2020. Be sure to update your queries.
Recharge
We have added a new table, ONE_TIME_PRODUCT.
Square
We have added two new tables, PAYMENT and CARD_PAYMENT_DETAILS.
We have added a new column, payment_id, to the REFUND table.
We have added two new columns, card_type and prepaid_type, to the CARD table.
Stripe
We have added three new tables:
TAX_RATEstores the tax rates that can be applied to either a subscription or an invoice item.TAX_RATE_SUBSCRIPTION_MAPPINGstores the tax rates applied to a subscription.TAX_RATE_INVOICE_ITEM_MAPPINGstores the tax rates applied to an invoice item.
We have renamed the following fields in the AUTHORIZATION table:
authorized_amounttoamountauthorized_currencytocurrency
We have moved the following fields from the TRANSACTION table to the AUTHORIZATION table:
merchant_data_network_idmerchant_data_postal_codemerchant_data_statemerchant_data_categorymerchant_data_citymerchant_data_namemerchant_data_country
We have added the following columns to the ISSUING_CARD table:
cancellation_reasonnumberreplaced_byreplacement_forreplacement_reasonshipping_etashipping_serviceshipping_statusshipping_tracking_urlshipping_type
We have removed the following columns from the ISSUING_CARD table:
authorization_controls_currencyauthorization_controls_max_amountauthorization_controls_max_approvalsshipping_phone
We have removed the is_deleted column from the PAYMENT_METHOD table.
We have removed the client_secret column from the SETUP_INTENT table.
Xero
We have added a new column, contact_id, to the INVOICE_LINKED_TRANSACTION table.
We have removed the _fivetran_deleted column from the CREDIT_NOTE table.
Zendesk Chat
We have removed the url column from the CHAT table.
Zendesk Sunshine
We now delete the records in the destination that are deleted from your Zendesk Sunshine application. Previously, we added a _fivetran_deleted column and set the value of the corresponding row in the destination to true to mark records that were deleted in Zendesk Sunshine.
Zendesk Support
We have added a new table, CALL_METRIC, which stores the Zendesk Talk call details. We exclude the CALL_METRIC table from the sync by default. To sync the table, go to the Schema tab on your connector details page and select it.
Improvements
Adobe Analytics
We have updated the connector's REST API configuration parameters to support JSON Web Token (JWT) Authentication. See our Adobe Analytics Connection Config documentation for more information.
Amazon S3
We now support syncing headerless delimited format files (CSV, TSV, log) for S3 connections. We will create generic column names for CSV files without a header line. This feature is in beta and available to all connections. See the configuration options in our files documentation for details.
Apple App Store
When setting up your Apple App Store connector, you can now choose the accounts you want to sync using Account Sync Mode. Previously, you had to separately specify the Sales and Finance accounts you wanted to sync.
This change only applies to new connections created after August 24, 2020 and does not impact existing connections.
Asana
We have released pre-built, dbt Core-compatible data models for Asana. Find the models in Fivetran's dbt hub or data models documentation. Learn more about our dbt Core integration in our Transformations for dbt Core documentation*.
* dbt Core is a trademark of dbt Labs, Inc. All rights therein are reserved to dbt Labs, Inc. Fivetran Transformations is not a product or service of or endorsed by dbt Labs, Inc.
Azure Blob Storage
We now support syncing headerless delimited format files (CSV, TSV, log) for Azure Blob Storage connections. We will create generic column names for CSV files without a header line. This feature is in beta and available to all connections. See the configuration options in our files documentation for details.
BigQuery
We now support tables that are partitioned based on INTEGER column. See our partitioned tables documentation for more details.
Databricks
Our Databricks destination now supports the creation of external tables. You can now opt to create Delta tables as external tables from the connection setup form.
We now support syncing the BINARY data type from your source.
Dropbox
We now support syncing headerless delimited format files (CSV, TSV, log) for Dropbox connections. We will create generic column names for CSV files without a header line. This feature is in beta and available to all connections. See the configuration options in our files documentation for details.
We now support syncing headerless delimited format files (CSV, TSV, log) for Email connections. We will create generic column names for CSV files without a header line. This feature is in beta and available to all connections. See the configuration options in our files documentation for details.
Fivetran Platform Connector
We have released a pre-built, dbt Core-compatible data model for the Fivetran Platform Connector. Find the model in Fivetran's dbt hub or data models documentation. Learn more about our dbt Core integration in our Transformations for dbt Core documentation*.
* dbt Core is a trademark of dbt Labs, Inc. All rights therein are reserved to dbt Labs, Inc. Fivetran Transformations is not a product or service of or endorsed by dbt Labs, Inc.
Front
We now sync the CONTACT table on a priority-first basis.
FTP
We now support syncing headerless delimited format files (CSV, TSV, log) for FTP connections. We will create generic column names for CSV files without a header line. This feature is in beta and available to all connections. See the configuration options in our files documentation for details.
GitHub
We have released pre-built, dbt Core-compatible data models for GitHub. Find the models in Fivetran's dbt hub or data models documentation. Learn more about our dbt Core integration in our Transformations for dbt Core documentation*.
* dbt Core is a trademark of dbt Labs, Inc. All rights therein are reserved to dbt Labs, Inc. Fivetran Transformations is not a product or service of or endorsed by dbt Labs, Inc.
Google Ads
You can now configure multiple reports in one connector. For example, you can configure several Google Ads reports for the same Customer ID without re-entering the credentials for each report.
All existing Google Ads connections are now considered legacy, but they continue to function just as they did before this change. You can change their setup in the same way as you did previously.
All new connections created after August 12, 2020 are multi-report. You can no longer direct multiple connections to the same schema in the destination because the schema name must be unique. If you need to use different credentials (for example, another Customer ID) for the same kind of reports, you have to create a separate connector and choose a different schema name for it.
We have added report schema configuration in the Schema tab. You can enable or disable the sync for any report you set up. The Schema tab shows the table name you chose when you set up the report, rather than the report name.
Read more about the new setup process in our Google Ads Setup Guide.
We now sync the BaseAdGroupId and BaseCampaignId columns from the KEYWORD_PERFORMANCE_REPORT report again. These columns were previously deprecated.
When you sync the KEYWORD_STATS pre-built report or a custom report based on the KEYWORD_PERFORMANCE_REPORT, you may notice the following warnings in your logs:
ADWORDS_DEPRECATED_FIELD : Deleting BaseAdGroupId from the set of fields of the report KEYWORDS_PERFORMANCE_REPORT. Remove the field by editing the setup form.ADWORDS_DEPRECATED_FIELD : Deleting BaseCampaignId from the set of fields of the report KEYWORDS_PERFORMANCE_REPORT. Remove the field by editing the setup form.
These warnings appear because we previously did not sync the BaseAdGroupId and BaseCampaignId columns. You do not need to take any action to resolve these warnings - these columns will be automatically added to your destination table.
Google Cloud Storage
We now support syncing headerless delimited format files (CSV, TSV, log) for Google Cloud Storage connections. We will create generic column names for CSV files without a header line. This feature is in beta and available to all connections. See the configuration options in our files documentation for details.
Headerless delimited format files support
We now support syncing headerless delimited format files (CSV, TSV, log) for the following file connectors:
We create generic column names for CSV files without a header line. Learn more in our Files connector documentation. This feature is in beta and available to all connectors.
HubSpot
We have released pre-built, dbt Core-compatible data models for HubSpot. Find the models in Fivetran's dbt hub or data models documentation. Learn more about our dbt Core integration in our Transformations for dbt Core documentation*.
* dbt Core is a trademark of dbt Labs, Inc. All rights therein are reserved to dbt Labs, Inc. Fivetran Transformations is not a product or service of or endorsed by dbt Labs, Inc.
We now use webhooks to capture deletes for the COMPANY, CONTACT, and DEAL tables. We are gradually rolling out this new feature to all existing connections. If you'd like to enable this feature on your connector, contact our support team.
Jira
We have improved the mechanism that detects similar fields that might cause data integrity issues. When we detect that similar field names would become duplicate names after normalization, we do not sync them to your destination. Instead, we show a warning on your dashboard and ask you to rename the fields. This prevents duplicates in the destination and avoids writing the values of the different fields into the same history table.
To prevent data integrity issues, we will sync some standard fields in the following way:
Σ Original Estimatefield to theISSUE_AGGREGATE_ORIGINAL_ESTIMATE_HISTORYtableΣ Time Spentfield to theISSUE_AGGREGATE_TIME_SPENT_HISTORYtableΣ Remaining Estimatefield to theISSUE_AGGREGATE_REMAINING_ESTIMATE_HISTORYtableΣ Progressfield to theISSUE_AGGREGATE_PROGRESS_HISTORYtable.
We have also improved the mechanism that detects the Jira changelog to avoid syncing values from one field into multiple history tables.
LinkedIn Ad Analytics
We have released pre-built, dbt Core-compatible data models for LinkedIn Ad Analytics. Find the models in Fivetran's dbt hub or data models documentation. Learn more about our dbt Core integration in our Transformations for dbt Core documentation*.
* dbt Core is a trademark of dbt Labs, Inc. All rights therein are reserved to dbt Labs, Inc. Fivetran Transformations is not a product or service of or endorsed by dbt Labs, Inc.
Mailchimp
We now prioritize email activity exports based on the amount of email activity that has yet to be synced. This prioritization change should improve the sync progress of email activity exports. Previously, we prioritized exports based on the most recent emails first.
We have released a pre-built, dbt Core-compatible data model for Mailchimp. Find the model in Fivetran's dbt hub or data models documentation. Learn more about our dbt Core integration in our Transformations for dbt Core documentation*.
* dbt Core is a trademark of dbt Labs, Inc. All rights therein are reserved to dbt Labs, Inc. Fivetran Transformations is not a product or service of or endorsed by dbt Labs, Inc.
Marketo
We have released pre-built, dbt Core-compatible data models for Marketo. Find the models in Fivetran's dbt hub or data models documentation. Learn more about our dbt Core integration in our Transformations for dbt Core documentation*.
* dbt Core is a trademark of dbt Labs, Inc. All rights therein are reserved to dbt Labs, Inc. Fivetran Transformations is not a product or service of or endorsed by dbt Labs, Inc.
Microsoft Dynamics 365 CRM
We now automatically re-sync a table when we receive an expired token error response for the table from Microsoft.
NetSuite SuiteAnalytics
We have released pre-built, dbt Core-compatible data models for NetSuite SuiteAnalytics. Find the models in Fivetran's dbt hub or data models documentation. Learn more about our dbt Core integration in our Transformations for dbt Core documentation*.
* dbt Core is a trademark of dbt Labs, Inc. All rights therein are reserved to dbt Labs, Inc. Fivetran Transformations is not a product or service of or endorsed by dbt Labs, Inc.
We have modified our sync strategy for incremental tables. Now, during the incremental update, we restrict the latest re-import range to the maximum primary key value. Previously, during the incremental update, we didn’t restrict the range, which caused high MAR (monthly active rows) consumption. We are gradually rolling out this change to all existing connections. If you'd like to use the updated strategy immediately, contact our support team.
Recharge
We now use webhooks to sync record updates in the CHARGE, ORDER, and SUBSCRIPTION tables.
Salesforce
We have released Fivetran history mode for Salesforce. You can turn on history mode for any table and capture every version of each record in your destination. With history mode, you can analyze data from a particular point in time or analyze how data has changed over time. To learn more, read our history mode documentation.
We are gradually rolling out history mode to existing connections. If you'd like to access history mode immediately, contact our support team.
We have released pre-built, dbt Core-compatible data models for Salesforce. Find the models in Fivetran's dbt hub or data models documentation. Learn more about our dbt Core integration in our Transformations for dbt Core documentation*.
* dbt Core is a trademark of dbt Labs, Inc. All rights therein are reserved to dbt Labs, Inc. Fivetran Transformations is not a product or service of or endorsed by dbt Labs, Inc.
We now capture deletes of history tables using the is_deleted field from Salesforce. Read our History tables documentation for more information.
We have disabled history mode for Salesforce history tables because history tables track object history by default. The changes made to an object over time are recorded in the Salesforce history tables using field history tracking.
SFTP
We now support syncing headerless delimited format files (CSV, TSV, log) for SFTP connections. We will create generic column names for CSV files without a header line. This feature is in beta and available to all connections. See the configuration options in our files documentation for details.
Snowplow
You can now exclude the UA_PARSER_CONTEXT table from the sync. Deselect the table from the Schema tab on your connector details page.
Stripe
We have released pre-built, dbt Core-compatible data models for Stripe. Find the models in Fivetran's dbt hub or data models documentation. Learn more about our dbt Core integration in our Transformations for dbt Core documentation*.
* dbt Core is a trademark of dbt Labs, Inc. All rights therein are reserved to dbt Labs, Inc. Fivetran Transformations is not a product or service of or endorsed by dbt Labs, Inc.
Twilio
We have released a new authentication mechanism using API Keys for our Twilio connector. Read Twilio's API Keys documentation for more information.
We are deprecating the old authentication mechanism using Account SID and AuthToken. Existing users will be notified to migrate and use the new authentication mechanism. Be sure to transition to the new authentication mechanism by September 1, 2020.
We have also updated the connector's REST API configuration parameters to use the new authentication mechanism. See our Twilio Connector Config documentation for more information.
Twitter Ads
We now support syncing data from the reporting tables for the promoted_account entity. See our PROMOTED ACCOUNT tables for more information.
Webhooks
We have added SwaggerUI support to our Webhooks API Swagger documentation. Now, you can explore the functionality of the webhooks endpoints.
REST API Improvements
Create external tables in Databricks
Our Databricks REST API endpoint now supports the creation of external tables. You can now opt to create Delta tables as external tables for your Databricks implementations.
New Configuration Parameters
We have updated the REST API configuration parameters to support new authentication mechanisms for the following connectors:
- Adobe Analytics now supports JSON Web Token (JWT) Authentication. See our Adobe Analytics Connection Config documentation for more information.
- Twilio now supports authentication using API Keys. See our Twilio Connector Config documentation for more information.
Reload a Connection Schema Config Endpoint Extension
We have expanded the current public API endpoint Reload a connection schema config. Now, you can enable or disable all schemas, tables and columns in the standard config by specifying the exclude_mode parameter in payloads.
Trial API Access
We made our REST API available for all Trial accounts. To learn about limitations for Trials as compared to Standard and Enterprise accounts, read our rate-limiting documentation.