Google Drive Setup Guide
Follow our setup guide to connect Google Drive to Fivetran.
Prerequisites
To connect Google Drive to Fivetran, you need:
- A Google Drive account
- A Google Drive folder containing files with supported file types and encodings
- The URL of your Google Drive folder that you want to sync
- The ability to grant Fivetran permissions to read from this account
Setup instructions
Begin Fivetran configuration
In the connection setup form, select the Sync Strategy: Magic Folder or Merge Mode.
Enter the Destination schema name of your choice.
If you select Merge Mode as your sync strategy, enter the Table group name.
In the Destination schema names field, choose the naming convention you want Fivetran to use for the schemas, tables, and columns in your destination:
- Fivetran naming: Standardizes the schema, table, and column names in your destination according to the Fivetran naming conventions.
- Source naming: Preserves the original column names from the source system in your destination. The source naming rules apply only to the column names, while the schema and table names follow the Fivetran naming rules.
If you want to modify your selection, make sure you do it before you start the initial sync.
Select your Authentication Method: Authorize Service Account or Authorize with User account.
If you select Authorize Service Account, share your Google Drive folder with Fivetran using our service account.
If you select Authorize with User account, click Authorize with Google. You will be redirected to your Google account to authorize Fivetran's access. Once you have granted access to Fivetran, you will be redirected back to Fivetran.
If you have selected the Authorize with User account authentication method, proceed to Step 3.
Share Google Drive folder with Fivetran
Perform this step only if you have selected the Authorize Service Account authentication method.
Find the auto-generated email address of the Fivetran service account and make a note of it. You will need it to share your Google Drive folder with Fivetran.
We create a Google service account for your Fivetran account because the service account authentication method provides fine-grained control over access to your data. You can add the unique Fivetran service account as a read-only user to the specific folders you want to sync.
Log in to your Google Drive account and navigate to the folder you want to sync the files.
Make sure that the folder is not empty. We can't sync empty folders.
Click the folder you want to sync and click Share from the drop-down menu.
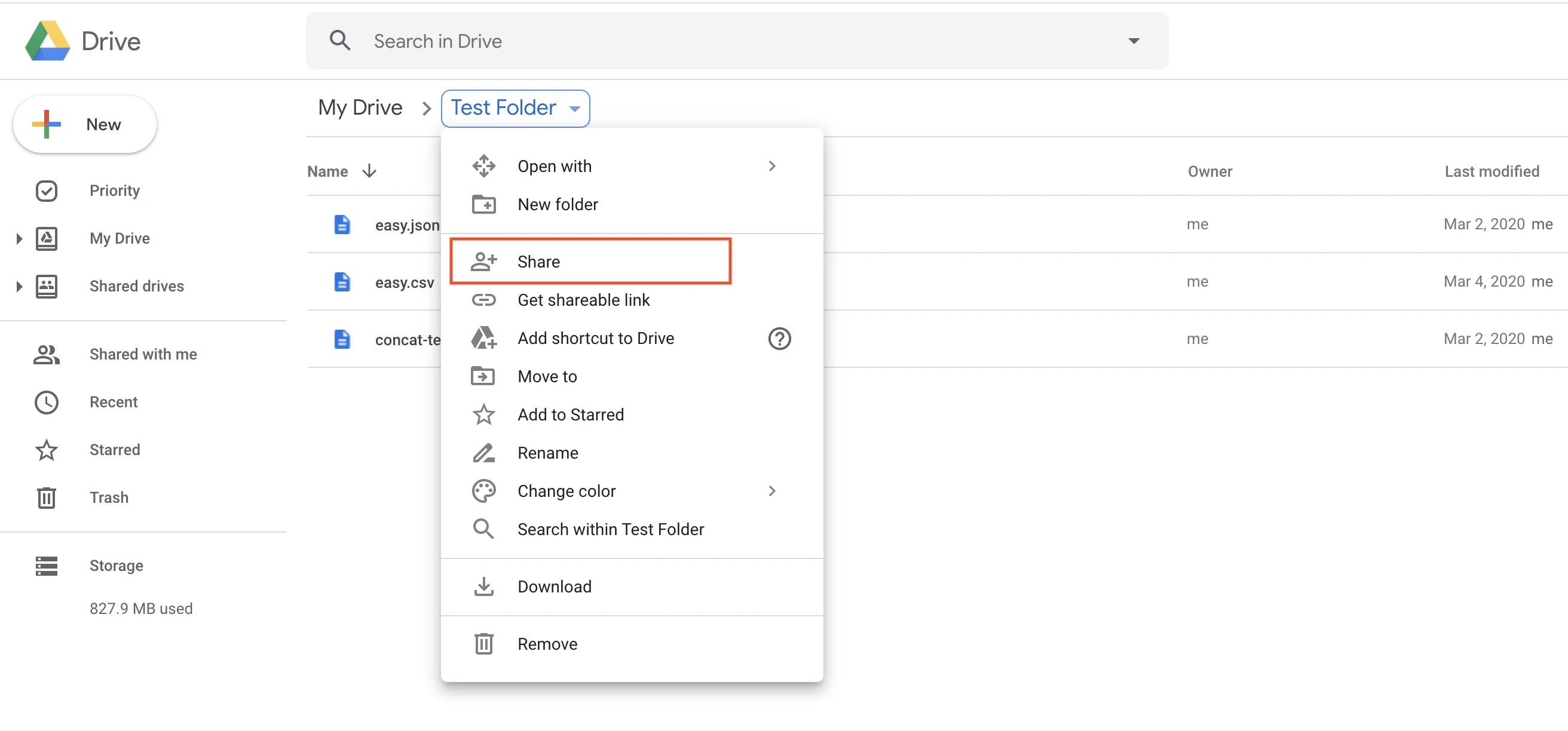
In the Share with people and groups pop-up window, enter the email address of the Fivetran service account.
Select Viewer permissions and then click Send.
Add Google Drive configuration
Magic Folder Mode
In the setup form, enter your Folder URL. The URL specifies the folder path in your Google Drive in which you'd like Fivetran to look for files. We examine all files under the specified folder and nested sub-folders for files that are eligible for syncing.
Make sure your URL matches the format illustrated below and doesn't include any extra characters after the folder ID. You can include
https://while entering the URL.
If you want to sync files from nested folders within the specified folder, set the Include subfolders toggle to ON.
Merge Mode
In the setup form, choose your configuration options. Using these configuration options, you can select subsets of your folders, specific types of files, and more to sync only the files you need in your destination. In addition, setting up multiple Google Drive connections targeted at the same file system but with different options allows you to slice and dice a file system any way you'd like, to get exactly the data you want into each table.
You can use the following configuration options:
Base folder URL - Choose the lowest common folder in a folder hierarchy that includes all the files you want to sync and enter it in the Base folder URL field. This defines a specific location where Fivetran scans for files and helps ensure optimal performance.
For example, if the files are in
files/exports/customers/data_20251016.csvandfiles/exports/products/data_20251016.csv, set the URL of theexportsfolder as the base folder URL.- This configuration option is available only if you choose to authorize using a Service Account.
- If you specify the root folder URL of the shared Google Drive, Fivetran upserts your data in the
_filecolumn by replacing the root folder name withDrive/in the destination.
(Optional) Click Run connection test to validate the login credentials and connection to the Google Drive.
You can skip this intermediate test and proceed to the next step. However, if you choose to skip, we will perform this test once you have finished your configuration.
Select files
Choose your configuration options. Using these configuration options, you can select subsets of your folders, specific types of files, and more to sync only the files you need in your destination. In addition, setting up multiple connections targeted at the same container but with different options allows you to slice and dice a container any way you'd like.
Base folder path - Choose the lowest common folder in a folder hierarchy that includes all the files you want to sync and enter it in the Base folder path field. This defines a specific location where Fivetran scans for files and helps ensure optimal performance.
For example, if the files are in
files/exports/customers/data_20251016.csvandfiles/exports/products/data_20251016.csv, enter theexportfolder URL as the base folder URL.This configuration option is available only if you choose to authorize with a User Account.
(Optional) File Pattern - Use a regular expression as the file pattern to decide whether or not to sync specific files. The pattern applies to everything under the prefix (folder path). If you want to sync everything under the prefix, leave this field blank.
For example, if under the prefix you have a folder
data, which has sub-folders,subFolder1,subFolder2, etc. These sub-folders have JSON files with the formatreport_03/12/2050.json. Use the following regex patterns to decide whether or not to sync specific files:data/.*matches all files in the data folder, including those in subfolders.data/.*jsonmatches all JSON files in the data folder, including those in subfolders.data/subFolder2/report_.*\.jsonmatches all the JSON files in thesubFolder2folder that have a name that starts with the prefixreport_.. For example,report_file.json.report_\d{2}/\d{2}/\d{4}\.jsonmatches all the JSON files that begin with the prefixreport_and are followed by a date format ofDD/MM/YYYYorMM/DD/YYYY. For example,report_03/12/2050.json.
We recommend that you test your regex.
(Optional) Click Preview Files to validate the file pattern.
You can skip this intermediate test and proceed to the next step. However, if you choose to skip, we will perform this test once you have finished your configuration.
Compression - If your files are compressed but do not have extensions indicating the compression method, you can decompress them according to the selected compression algorithm. If all of your compressed files are correctly marked with a matching compression extension (.bz2, .gz, .gzip, .tar, or .zip), you can select infer. If you select uncompressed, we do not decompress the files and sync the uncompressed files. If you choose a compression format, we decompress every file using the format you select. For example, if you have an automated CSV output system that GZIPs files to save space but saves them without a .gzip extension, you can set this field to GZIP. We will decompress every file that we examine using GZIP.
(Optional) Archive Folder Pattern - Use a regular expression to filter and sync files from archived folders. We sync the files in compressed archives with filenames matching the specified pattern. If there are multiple files within an archive (TAR or ZIP) folder, you can use the archive folder pattern to filter file types. For example, if you specify the archive folder pattern as
.*json, we will sync only the files that end in a .json file extension from the archive folder.This is only used to filter out the files inside the archived folder. All the files matching the File Pattern will be listed.
Format
File Type - We process all files as the selected file type. Use the File Pattern field to select the file extensions you want to sync.
If your file type is XML, we load your XML data into the
_datacolumn without flattening it.If your file type is CSV or TSV then enter the following details:
- (Optional) Delimiter - Specify the delimiter used in your CSV file. If your CSV file uses a custom delimiter, replace the default comma
,with your specific delimiter. For example, if your file is tab-delimited, enter\t, or if it’s pipe-delimited, enter|. If you leave this field blank, we’ll attempt to detect the delimiter for each file automatically. However, note that automatic detection may not work in all cases. If your files sync with an incorrect number of columns or use a unique delimiter, consider specifying the delimiter. You can store files with different delimiters in the same folder. For more details on how delimiter inference works, see our documentation. - Quote character - Typically, CSVs use double quotes
"to enclose a value. Set the toggle to off if you don’t want to use an enclosing character. - Non-Standard escape character - Set the toggle to ON if your CSV generator uses non-standard ways of escaping characters like newline, delimiter, etc. Not standard in CSVs.
- Null Sequence - Set the toggle to ON if your CSVs use a special value indicating null. Specify the value indicating null only if you are sure your CSVs have a null sequence. Typically, CSVs have no native notion of a null character. However, some CSV generators have created one, using characters such as
\Nto represent null. - Skip Header Lines - Use this option to skip over a fixed number of header lines at the beginning of your CSV files. Set the toggle to ON, and then in the Number of skipped header lines field, specify the number of header lines you want to skip.
- Skip Footer Lines - Use this option to skip over a fixed number of footer lines at the end of your CSV files. Set the toggle to ON, and then in the Number of skipped footer lines field, specify the number of footer lines you want to skip.
- Headerless files - Set the toggle to ON if your CSV-generating software doesn't provide a header line. Fivetran can generate generic column names and sync data rows with them.
- Line Separator - Line separators are used in CSV files to separate one row from the next. By default, we use the new line character
\nas the line separator. If you use a different line separator for your CSV files, replace\nwith your custom line separator.
If your file type is JSON or JSONL, then select the following:
JSON Delivery Mode - Use this option to choose how Fivetran should handle your JSON data.
- Packed: We load all your JSON data into the
_datacolumn without flattening it. - Unpacked: We flatten one level of columns and infer their data types.
(Beta) If your file type is unstructured, do the following:
You can sync unstructured files only if you have configured your connection with a BigQuery, Databricks, or Snowflake destination.
i. Select unstructured to sync documents, images, or plain text files to your destination’s object storage, excluding compressed files.
ii. Set the Export Google Docs and Slides as PDF documents toggle to ON to export your Google Docs and Slides as PDFs.
By default, Google Docs and Slides are exported as .docx and .pptx files.
Learn more about unstructured file replication in our documentation.
If your file type is XLS, XLSX, XLSM or Google Sheet, then enter the following details:
If you have selected xls/xlsx/xlsm/Google Sheet as the file type, you must select the top-left cell of the spreadsheet that you want to sync. The connection setup form then requests you to identify a sample file you would like to sync. We analyze to identify eligible data sets. To determine the cell reference correctly, do the following:
Enter one of the following in the Spreadsheet to find data to be synced field.
- Google Drive file ID
- Google Sheet URL from Google Drive
- Excel file URL available from Google Drive
Click Analyze Sheet.
Select the Cell Reference for syncs.
If you select xls/xlsx/xlsm/Google Sheet as the file type, we add the
_sheet_nameand_file_idcolumns to your destination. However, we assign_file_idcolumn as the primary key only if you select the Upsert file using file name and line number or Append file using file modified time option to update the files in your destination.- (Optional) Delimiter - Specify the delimiter used in your CSV file. If your CSV file uses a custom delimiter, replace the default comma
Primary Key used for file process and load - Use this option to let Fivetran know how you'd like to update the files in your destination. When you modify a previously synced file, the option you select determines if we should replace the rows in the destination table or append new rows to the table:
- If you select Upsert file using file name and line number, we will upsert your data using the surrogate primary keys
_fileand_line. If a file has a unique name, we will sync the data for that file as new data. - If you select Append file using file modified time, we will upsert your files using surrogate primary keys
_file,_line, and_modified. You can track the full history of a file or set of files and your files will have a combination of old and new data or data that is updated periodically. - If you select Upsert file using custom primary key, you can keep the most recent version of every record and your files will have a combination of the old and new data or data that is updated periodically. You can choose the primary keys you want to use after you save and test.
You can't modify your primary key option once the initial sync is successful. However, if you selected Upsert file using custom primary key, you can change the columns selected as primary keys after the initial sync.
- If you select Upsert file using file name and line number, we will upsert your data using the surrogate primary keys
Additional options
Error Handling - Use the error handling option to choose how to handle errors in your files. If you know that your files contain some errors, you can choose to skip poorly formatted lines.
If you select skip, we ignore improperly formatted data within a file, allowing you to sync only valid data.
If you select fail, we fail the sync with an error on finding any improperly formatted data.
We recommend that you select fail unless you are sure that you have undesirable, malformed data.
You will receive a notification on your Fivetran dashboard if we encounter errors.
Finish Fivetran configuration
Click Save & Test. Fivetran will take it from here and sync your data from your Google Drive.
Fivetran tests and validates the Google Drive connection. On successful completion of the setup tests, you can sync your Google Drive data to your destination.
Setup tests
Depending on your sync strategy, Fivetran performs the following Google Drive connection tests:
(Both Magic Folder Mode and Merge Mode) The Connecting to Google Drive test validates the accessibility of the folder path in your Google Drive account you specified in the setup form.
(Merge Mode) The Validating File Pattern test validates the file pattern regex you specified in the setup form. We perform this test only if you specify a regex in the File Pattern field.
(Merge Mode) The Validating Archive Pattern test validates the archive pattern regex you specified in the setup form. We perform this test only if you specify a regex in the Archive Folder Pattern field.
(Merge Mode) The Validating EscapeChar test validates the escape character you specified for your CSV files and checks the length of the character, which must not be more than one. We perform this test only if you specify an escape character in the Escape Character field.
(Merge Mode) The Multi-Character Delimiter Support test validates the length of the delimiter, which must be within 15 characters. We perform this test only if you specify the delimiter for your CSV files in the Delimiter field.
(Merge Mode) The Finding Matching Files test checks if the connection can successfully retrieve a minimum of one sample file and a maximum of ten sample files based on the configuration you specified in the setup form.
The tests may take a couple of minutes to complete.