Release Notes
June 2026
Our Files connectors now support creating empty columns and columns with null values in your destination. During the initial sync, we create these empty columns with the STRING data type. However, if the column later contains non-null values in subsequent syncs, we update the column data type based on the data type we infer from the schema. Previously, we did not support creating empty columns or columns with null values in your destination.
We support this enhancement only for the following File connectors set up using BigQuery, Databricks, and Snowflake as destinations:
- Amazon S3
- Azure Blob Storage
- Box
- Dropbox
- FTP
- Google Cloud Storage
- S3-Compatible Storage
- SharePoint
- SFTP
We are gradually rolling out this enhancement to all existing connections.
May 2026
We have discontinued the archive_pattern and pattern parameters in the Fivetran REST API for the following connectors:
- Amazon S3
- Azure Blob Storage
- Box
- Dropbox
- FTP
- Google Cloud Storage
- Google Drive
- SharePoint
- SFTP
- S3-Compatible Storage
We will continue supporting these parameters for both new and existing connections until August 31, 2026. After August 31, 2026, we will stop supporting these parameters for all connections and replace them with the files.archive_pattern and files.pattern parameters respectively.
April 2026
We now allow you to update the primary key column after the initial sync when using the Upsert file using custom primary key option.
We have added a new toggle, Allow inconsistent row lengths, to the connection setup forms to support syncing rows in CSV files with inconsistent lengths for the following connectors:
- Amazon S3
- Azure Blob Storage
- Box
- Dropbox
- FTP
- Google Cloud Storage
- Google Drive
- SharePoint
- SFTP
- S3-Compatible Storage
This feature is available only to all new connections created after 13 April, 2026. We are gradually rolling out this feature to all existing connections. For more information, see our documentation.
We have modified how the _line system column reflects the row position in your destination. The _line system column now displays its physical row position in the source file, even if we skip rows from the sync due to the on_error=skip setting in your destination. Therefore, if we now skip syncing a physical row, the position of the _line column in your destination will remain unchanged. It will always match the corresponding row positions in the source file to ensure a consistent mapping between the source file and your destination. Previously, we updated the _line column sequentially, which was calculated based on the rows that were successfully synced. This change is available only for new connections created after April 22, 2026.
March 2026
We now support specifying custom primary keys for tables created through dynamic table mapping.
February 2026
We now support syncing XLS/XLSX/XLSM files to multiple destination tables and handling file patterns. To support this enhancement, we have made the following changes to the connection setup form:
- Moved the Configure files section below the Format section to enable file type selection before configuration.
- Moved the following sub-fields from the Format section to the Configure files section of the setup form:
- Manual cell reference
- Spreadsheet to find data to be synced
- Cell reference for syncs
For more information, see our setup instructions. We are gradually rolling out these enhancements to all existing connections.
January 2026
We now record the read_start and read_end events as user-facing logs for all File connectors. For more information, see our Monitor file sync activity documentation.
The Preview Files test now displays the archived files that match your specified archive file pattern, allowing you to review the files that we will process. Previously, it displayed only files matching your specified file pattern.
December 2025
We now support the Source naming feature for the following connectors:
| Application Connectors | Database Connectors | File Connectors | Event Connectors | Function Connectors |
|---|---|---|---|---|
|
November 2025
Row filtering is now supported for the following connectors:
To learn how to use row filtering and see the list of supported connectors, see our row filtering documentation.
We have added a new feature, Dynamically extract tables. You can now define a single regex pattern with a named capture group (?<table>...) to automatically extract table names from file paths. This feature automatically creates and maps destination tables based on your file naming patterns, eliminating the need for manual intervention.
To support this feature, we have made the following changes to the connection setup form:
- Added a new option, File mapping, that allows you to choose between Define per table and Dynamically extract tables.
- Added a new field, Table extraction pattern, to specify your own regex pattern.
- Added a new button, Preview, to validate the specified regex pattern.
Key benefits include:
- Simplified configuration: Avoids repetitive setup for multiple entities.
- Automatic table creation: Captures new entities as they appear in your source, without additional configuration.
For more information, see our Dynamic Table Mapping tutorial and setup instructions.
We are gradually rolling out this change to all existing connections.
August 2025
We have added a new toggle, Manually provide cell reference, to the setup form of the following connectors:
- Amazon S3
- Box
- Dropbox
- SFTP
- SharePoint
You can now manually specify a cell reference for the file path instead of using the default automatic detection.
July 2025
We have made the following changes to the connection setup form:
- Added support to configure archive patterns per table. This is useful when an archive folder contains files following different naming patterns, allowing you to route each pattern to a specific destination table based on its pattern.
- Renamed the Archive Folder Pattern field to Archive File Pattern.
For more information, see our setup instructions.
June 2025
We are deprecating support for the log file type in file connectors. Use the csv file type instead. Log files will now be processed the same way as CSV files. This change streamlines file type handling without affecting functionality.
April 2025
We now support syncing files to multiple destination tables and handling file patterns. To support these features, we have made the following changes to the connection setup form:
- Added the Files field and sub-fields Table name and File pattern, that enable you to define destination tables and specify the file pattern names.
- Renamed the Destination table field to Table group name to enable unique identification of connections that share the same destination schema name.
Also, we have discontinued the table and pattern configuration parameters for all Amazon S3 connections and will delete them by August 31, 2025.
For more information, see our setup instructions and REST API configuration. We are gradually rolling out these enhancements to all existing connections.
We have updated the sync strategy for the following connectors and now preserve the original NUMERIC data types from the source while syncing the Excel files. Previously, we synced the values of the formula cells with NUMERIC data types as FLOAT or DOUBLE.
January 2025
We have renamed the Folder Path field to Base folder path in the following connection setup forms:
This improvement is applicable for new connections created on or after January 2, 2025. We are gradually rolling out this change to all existing connections.
Our Amazon S3 connector now supports syncing Microsoft Excel spreadsheets. For more information, see our Amazon S3 documentation.
November 2024
We have improved the connector setup experience and made the following changes to the connection setup form:
- Added a new configuration option, Run connection test to perform an intermediate test during configuration
- Added a new configuration option, Preview Files to perform an intermediate test during configuration
- Added support for displaying fields based on the file type
- Added a new field, Quote character, to use an enclosing character
- Reorganised fields to make the setup form more intuitive
- Removed Infer as an option from the File Type field
- Removed the Enable Advanced Options toggle
- Changed the Null Sequence field to a toggle
- For the Delimiter field, we now use
,as the default value - For the Line Separator field, we now use
\nas the default value
For more information, see our setup instructions. We are gradually rolling out these changes to all existing connections.
October 2024
You can now configure the primary key used for file process and load using the Fivetran REST API.
September 2024
We now restrict API users from triggering syncs if:
- the
append_file_optionfield is set to theupsert_file_with_primary_keysvalue - primary keys are not defined in the schema configuration
We also restrict the following actions:
- Creating a new connection in an un-paused state via API
- Updating the connection's
pausedfield tofalsevia API request - Forcing the connection sync or re-sync via API request
The Amazon S3 connector now supports the Hybrid Deployment model. For more information, see our setup instructions.
January 2024
We have added a new toggle, Non-standard character escaping?, to the connector setup form to support the non-standard ways of escaping characters. If your CSV generator uses non-standard ways of escaping characters, set the toggle to ON and in the Character Escaping options drop-down menu, select one of the following options:
- Custom Escape Character: To process CSV files that use custom escape characters to escape quotation marks.
- Delimited Only: To process CSV files that don't use escape characters to escape quotation marks and process with delimiter only.
For more information, see our setup instructions and REST API config. We are gradually rolling out this change to all existing connections.
We have added a new configuration option, Primary Key used for file process and load, in the connector setup form to support syncing files with custom primary keys. You can now select the custom primary keys during the connector configuration and use them to update or insert new rows in your destination. We process the most recently modified files to your destination. For more information see our setup instructions.
September 2023
We now support syncing PGP (Pretty Good Privacy) signed and encrypted files. We have added a new option, Signer's Public Key, to the PGP Encryption Options configuration in the connector setup form. For more information, see our setup instructions.
August 2023
We now validate that the external_id value that you specify when creating the Amazon S3 connector using the REST API is the same as your Fivetran account's group_id. Make sure to choose any of the group_id from your Fivetran account as the external_id parameter value. To find the group_id, use the List All Groups endpoint.
July 2023
We have changed the default value of the JSON Delivery Mode feature to Packed in the connector setup form. Previously, we used Unpacked as the default value for this feature.
We now support syncing XML files to your destination. We have added a new option, xml, to the File Type drop-down menu of the connector setup form. We load your XML data into the _data column without flattening it. For more information, see our setup instructions.
We now support custom line separators for CSV files. You can specify a custom line separator in the Line Separator field of the connector setup form. For more information, see our setup instructions.
You can now opt to provide Fivetran access to your S3 bucket using an access key and secret. For more information, see our setup instructions and REST API config.
June 2023
We now support multi-character delimiters for CSV files. You can specify a multi-character delimiter in the Delimiter field of the connector setup form. For more information, see our setup instructions.
April 2023
We can now sync packed JSON files from Amazon S3. We have added a new drop-down menu, JSON Delivery Mode, to the connector setup form. The drop-down menu provides you the option to choose how Fivetran should handle your JSON data. For more information, see our setup instructions.
March 2023
We now support syncing PGP (Pretty Good Privacy) encrypted files. We have added a new advanced configuration option, PGP Encryption Options, to the connector setup form. For more information, see our setup instructions.
June 2022
We have redesigned the Skip Header Lines and Skip Footer Lines setup form fields for our Amazon S3, Azure Blob Storage, Dropbox, FTP, Google Cloud Storage, and SFTP file connectors. To set these advanced options, enable them using the toggles and specify the number of skipped lines in the input fields.
Compare how the setup form looked before the change:
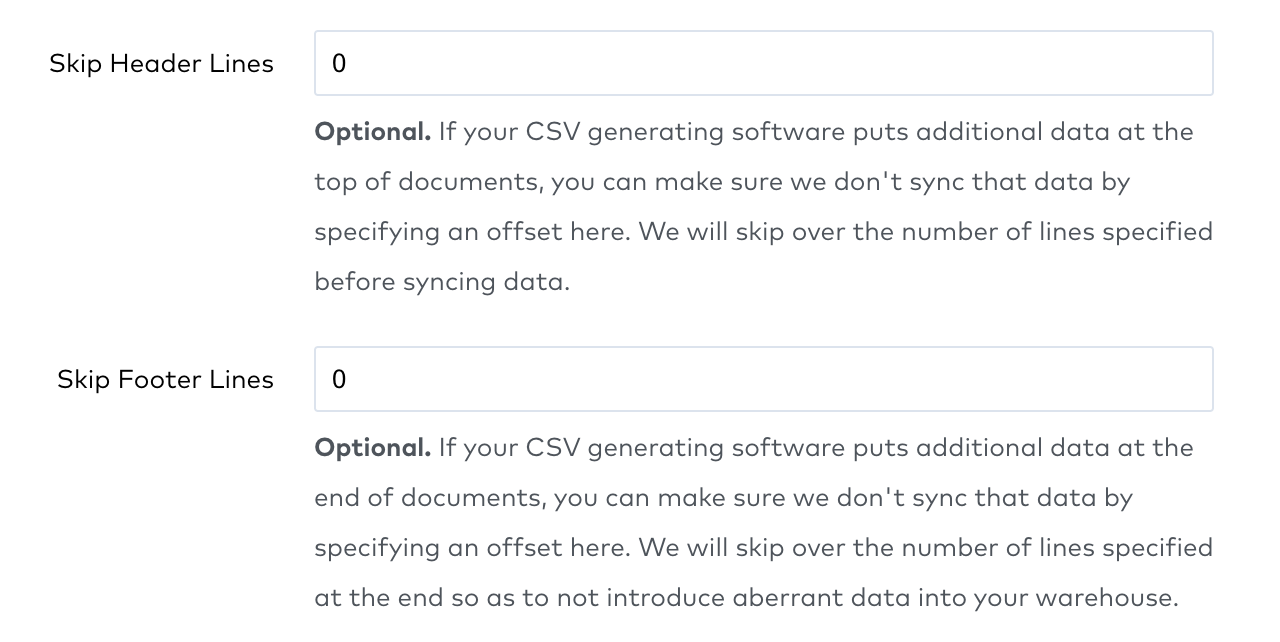
and how it looks now:
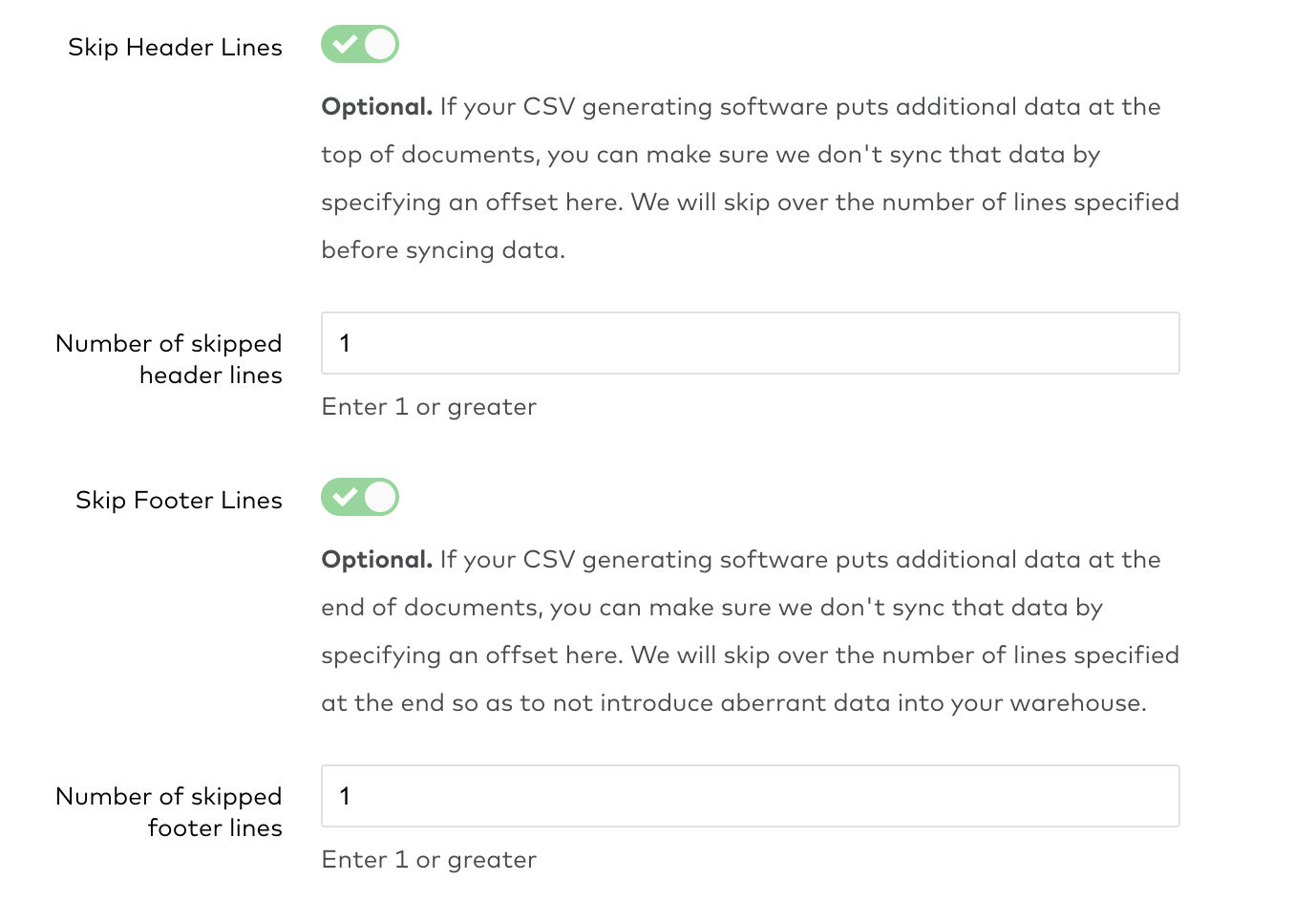
January 2022
We have added support for AWS PrivateLink connections to S3 buckets. If you're on a Business Critical plan, you can now opt to always connect through a private link if your bucket and destination are in the same AWS Region. In the connector setup form, set the Require PrivateLink toggle to ON. For more information, see our setup instructions.
November 2021
You can now use a custom external_id parameter when you create a new Amazon S3 connector with the Fivetran REST API.
Connections created in the Fivetran dashboard do not support custom external_id values, so they use the connector's group_id by default instead.
April 2021
We have added a new advanced configuration option List Strategy to the connector setup form. Enable the Enable Advanced Options toggle and select the listing strategy you want to use:
complete_listing: The default listing strategy where we list all the files in the bucket and filter new and modified files.time_based_pattern_listing: An optimized listing strategy to improve sync speeds. We fetch the files in a lexicographic order starting from the last file of the previous sync. You can opt to use this strategy if your files are named based on the date or time they are added to the bucket. For example, if a time-based pattern exists in the bucket leading to every new file being appended in a lexicographically increasing order:Filename Last Modified 2021/01/01.csv January 1, 2021 2021/01/02.csv January 2, 2021 2021/01/03.csv January 3, 2021 2021/01/04.csv January 4, 2021 If we are unable to identify a time-based pattern in the file names, we will use the default strategy and list all the files.
August 2020
We now support syncing headerless delimited format files (CSV, TSV, log) for S3 connections. We will create generic column names for CSV files without a header line. This feature is in beta and available to all connections. See the configuration options in our files documentation for details.
June 2020
We now exclude S3 objects that have been archived to Glacier storage class from our data syncs. If you want us to sync these objects, restore them to standard storage.
April 2020
You can now connect to public S3 buckets without needing an AWS account.
March 2020
Our Amazon S3 connector can now sync Parquet files. We support Parquet format 2.4.0. This feature is in Beta.
June 2019
We now require you to configure a Role ARN when you set up an Amazon S3 connector, even if your bucket is a public bucket.
Existing Amazon S3 connectors will not be affected. However, if you reconfigure an existing connector or create a new one, you will have to configure a Role ARN even if your bucket is a public bucket.
We have added a new connection test to the Amazon S3 setup form that helps you adopt security best practices. The test checks your bucket policy settings to make sure you have created your Role ARN using the given externalID.
If you mistakenly create your Role ARN without using the give externID, the configuration will now fail the test. You will have to correct your Role ARN.
August 2018
We can now sync data from public buckets.
May 2018
Our connector setup form now correctly handles directory patterns that don't end with /.