Replication Topologies
Fivetran HVR supports data replication across multiple heterogeneous systems. Below are basic replication topologies that allow you to construct any type of replication scenario to meet your business requirements.
Uni-directional (one-to-one)

This topology involves unidirectional data replication from a source location to a target location. This type of topology is common when customers look to offload reporting, feeding data lakes, and populating data warehouses.
Broadcast (one-to-many)
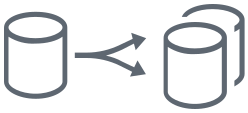
This topology involves one source location, from which data is distributed to multiple target locations. The one-to-many topology is often used to distribute the load across multiple identical systems, or capture once and deliver to multiple destinations. For example, this may be adopted for cloud technologies targeting both a file-based data lake using a distributed storage systems such as S3 or ADLS, as well as a relational database for analytics such as Snowflake, Redshift, or Azure Synapse Analytics.
Consolidation/Integration (many-to-one)
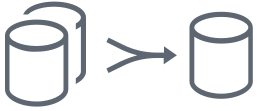
This topology involves multiple source locations consolidating data into one target location. The many-to-one is the topology for data warehouse or data lake consolidation projects, with multiple data sources feeding into a single destination, or for the use case of multiple distributed systems, typically containing a subset of data (e.g. local branches), all feeding into a central database for analytics and reporting.
Cascading
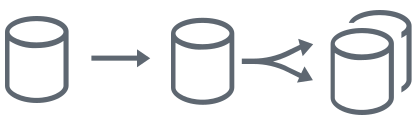
This topology involves a source location pushing data to a target location, whereas the target also acts as a source distributing the data out to multiple target locations. This is typically used to replicate data into a data warehouse and building individual data marts.
Bi-directional (active/active)

A bi-directional topology assumes that data is replicated in both directions, and end users (applications) modify data on both sides. It is also referred to as an active/active scenario to keep two systems in sync, giving the ability to share the replication load across the systems, as well as their high availability. This is typical in a geographically distributed setup, where the data should always be local to the application, or in a high availability setup. HVR provides a built-in loopback detection mechanism to protect the systems from boomerang loopback issues, as well as collision detection and resolution mechanism.
Multi-directional
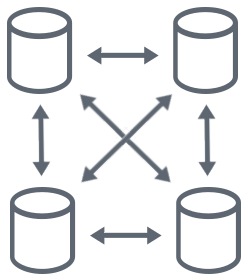
A multi-directional active/active replication involves more than two locations that stay synced up. This is a typical scenario for geographically distributed systems, where any changes made to any node will be propagated to all the other nodes within this network. This type of replication generally introduces a number of additional challenges beyond regular active/active replication: network latency, bandwidth reliability, or a combination of these. HVR provides technology to address all these challenges, including automatic recovery via the built-in scheduler, optimized network communication with high data compression, etc.