Files
File connectors facilitate data extraction from multiple file storage systems or applications to your destination.
Supported services
Sync modes
Files connectors offer dual-mode sync strategies. You can opt to use one of the following sync modes:
Magic Folder Mode
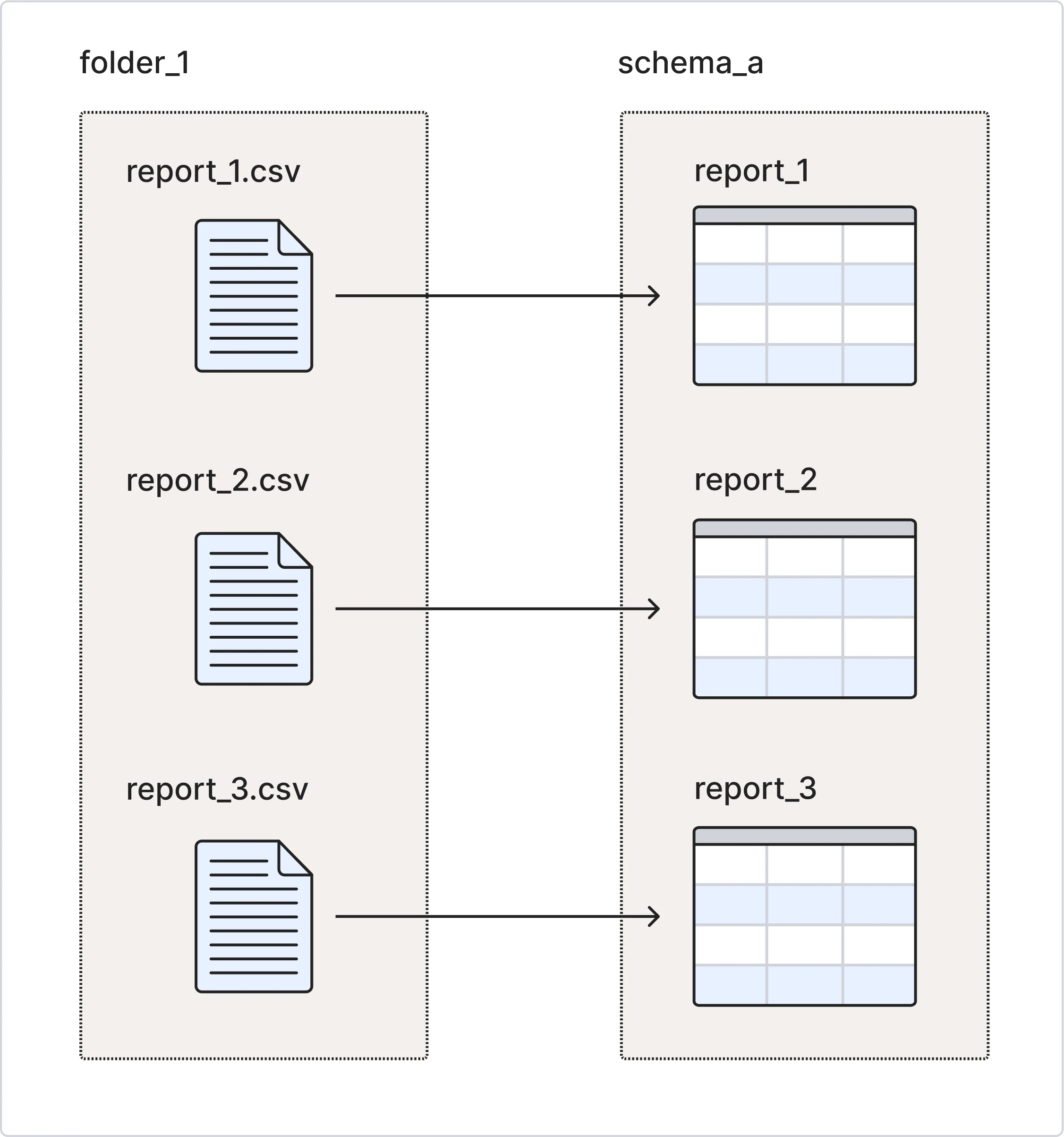
Fivetran syncs each file in the configured source folder as a unique table in your destination. We use the file name as the destination table name.
Magic Folder connections sync each source file to a different destination table. We detect the changes you make to the existing files and update the rows in the respective destination tables.
We support syncing multiple worksheets from your spreadsheet (Microsoft Excel and Google Sheets) files as unique destination tables.
Magic Folder Mode doesn't support incremental syncs. To detect changes in the files of your cloud folder, we use the last modified date of the files. After the initial historical sync, we re-import only the recently modified files in every sync.
We do the following:
- If you add a new file to your cloud folder, we sync the file as a new table in your destination.
- If you modify a file in your cloud folder, we sync the file's content again to the destination table. We delete the previous data of the table and don't capture deletes.
- If you delete a file from your cloud folder, we don't delete the table from your destination.
If we find files of the same name but with different extensions in the folder, we process the file we encounter first. For example, if you add a file called abc.csv in your cloud folder and then add another file called abc.json, we create the table abc for the file that we encounter first. After that, we won’t sync any file with the name abc with other extensions, because the abc table will already be present.
We use the file name (without the extension) as the destination table name. For example, we sync a file named account_details.csv as the ACCOUNT_DETAILS table.
For spreadsheet files, we use a combination of the file name and worksheet name as the destination table name. For example, two worksheets called Sheet1 and Sheet2 in a spreadsheet My Workings are synced as MY_WORKINGS_SHEET_1 and MY_WORKINGS_SHEET_2 tables. We use the values present in the first row of the worksheet as the column names in the destination table.
For more information about the schema and table naming rule set, see our naming conventions documentation.
After the first successful sync, you can view this mapping information in the Schema tab on your connection dashboard.
Primary keys
For Magic Folder Mode, Fivetran adds a single column as a primary key for each table.
| COLUMN | DATA TYPE |
|---|---|
| _line 🔑 | INT |
Sync limitations
Magic Folder Mode has the following sync limitations:
By default, we do not sync files from the nested folders within your configured folder. However, if you want to sync these files, you must set the Include subfolders toggle to ON. This option is available only in Dropbox, Google Drive, SharePoint, and SFTP connectors.
We do not sync empty folders or unsupported file types.
We don't sync empty worksheets. We don't sync an Excel worksheet if the entire first row of the worksheet is empty. We don't sync a column if its first row is empty.
We don't sync worksheets with pivot tables.
You can find more information on the individual connector pages.
Schema view
The Schema tab of a connection in Magic Folder Mode does not have the Collapse all or Expand all button enabled on your connection dashboard.
If you haven't uploaded any supported files, the Schema tab of a connection in Magic Folder Mode will be empty.
Merge Mode
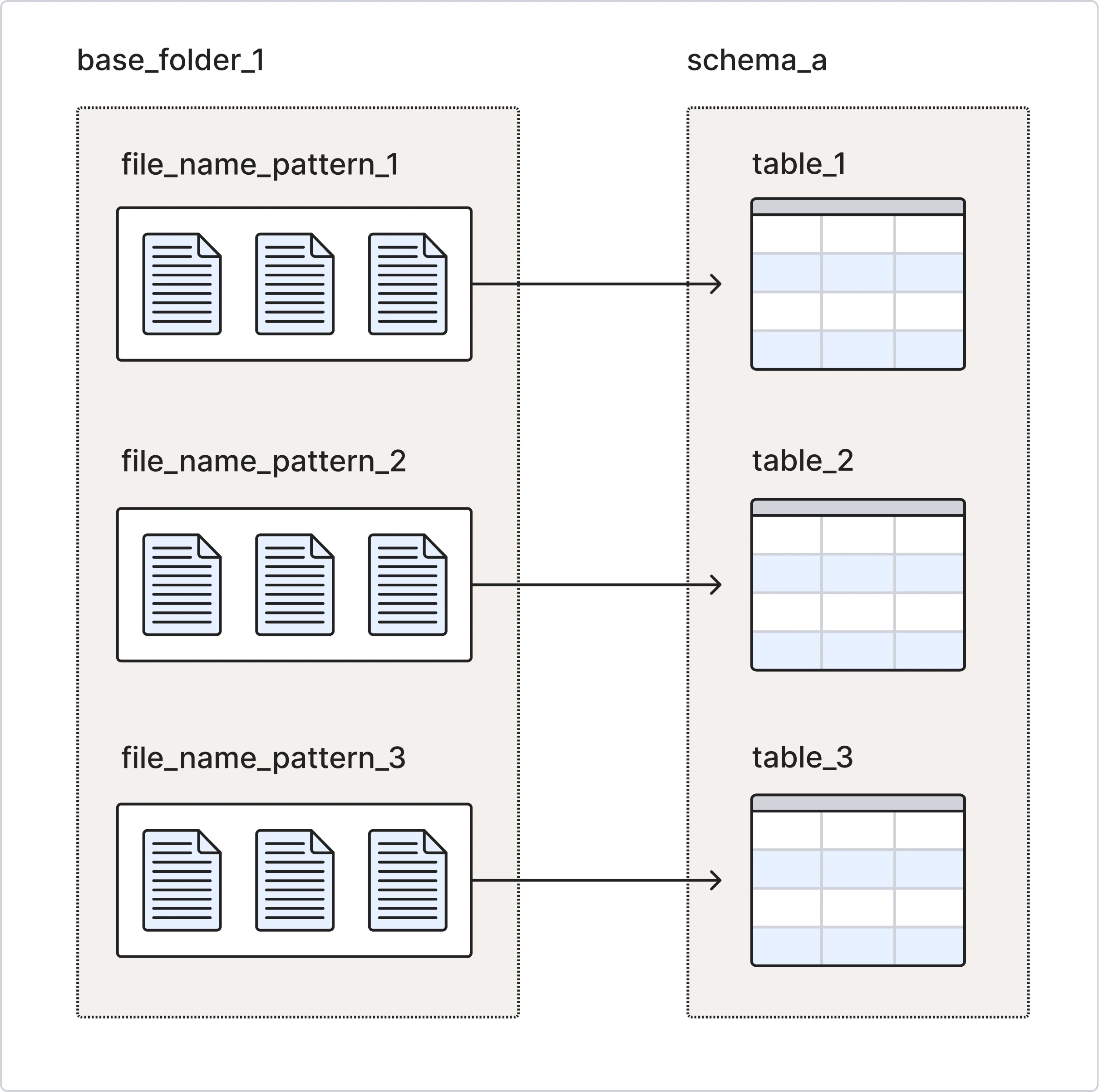
Merge Mode allows you to sync data into multiple destination tables by defining specific file name patterns within a base storage folder. Each file name pattern directs a subset of files to the corresponding destination table.
We continuously monitor for new or updated files matching your specified patterns and periodically sync the data into the relevant destination tables.
You can also configure multiple connections to sync data into a single schema.
If you create multiple connections under the same schema and provide duplicate table names across these connections, we do not check for or prevent duplicate table names. This may result in conflicts or unexpected behavior in your destination.
Merge Mode supports incremental syncs.
System columns
Fivetran adds the following columns for all tables:
| COLUMN | DESCRIPTION | DATA TYPE | NOTE |
|---|---|---|---|
_file | File name | TEXT | |
_line | Line number | INT | |
_modified | Last modified time | TIMESTAMP | For the Email connector, the _modified column contains the timestamp when we receive an email containing a file. |
Primary key used for file process and load
The following configuration options enable Fivetran to know how you'd like to update the files in your destination.
| OPTIONS | PRIMARY KEY COLUMNS | NOTE |
|---|---|---|
| Upsert file using custom primary key (recommended) | Select during connection setup | The most recent version of each record is kept in the destination, based on the selected primary key. If we detect that one of the selected primary keys has a null value in your files, we display a warning on the connection dashboard but insert the record with a null value in your destination. If the destination does not support null values, we insert the row with the default value for the column. |
| Upsert file using file name and line number | _file, _line | When a previously synced file is modified, rows are replaced in the destination. |
| Append file using file modified time | _file, _line, _modified | This option can be used to track file modification history. |
You can't modify your primary key option once the initial sync is successful. However, if you selected Upsert file using custom primary key, you can change the columns selected as primary keys after the initial sync.
Naming
You can assign custom schema and table group name while building your connection. Column names are generated based on the uploaded files. For a CSV, there will be one column for each entry in the first line. For a JSON file, there will be one column for each top-level field in the JSON object.
If you change the name of a file in your bucket, all data in that file will be re-imported, which may result in duplicate values within that table.
Excluding source data
Inclusion and exclusion of source data in file storage connections are done by specifying the folder path. The connection will sync all files under a certain folder path, even if they are themselves in nested subfolders of the specified folder. Excluding fields from source files is not supported.
If we find the _fivetran_synced, _fivetran_id, and _fivetran_active columns in the source files, we ignore these columns during the sync because we use the values of the corresponding system columns that Fivetran generates in your destination.
Updating data
After the initial load of historical data, Fivetran only pulls incremental updates of any new or modified files from the source, adding an extra column to your tables called _fivetran_synced (TIMESTAMP) that indicates the start time of the job that synced this row.
We do not recommend manually changing the contents of your files while using the upsert_file primary key configuration. Doing so will result in the following behaviors:
- As the connection has file-level granularity, if you modify a file, we update the table in the destination to match the contents of the file.
- Adding rows to a CSV that has already been synced will change the last modified date, which will then trigger a re-sync of the contents of that file.
- As we use the file name and line numbers as primary keys, whatever you change in your file will be represented in the file in the destination, but you may lose the previous version of the file that corresponded to the old record.
Deleted data
We handle the data deleted at the source based on the last modified dates of the files, and treat the deleted files, columns, and rows differently.
Files: If you delete a file in your source, it no longer exists, so it no longer has a last modified date and the deletion is not reflected in your destination. Therefore, the data from the deleted file remains in your destination, and we do not update the
_fivetran_syncedcolumn for that file. The column will continue to show the last time we successfully synced the file before it was deleted.Columns: If you delete a column in your source, it results in a change in the last modified date. The value of the deleted columns is synced as null in the destination.
Rows: If you delete a row in your source, it results in a change in the last modified date. If you use
upsert_fileas the primary key during configuration, then the rows are deleted from your destination.
Configuration options
While configuring your connection, you can select subsets of your folders, certain types of files, and more to sync only the files you need in your destination. Setting up multiple connections targeted at the same source, but with different options, can allow you to slice and dice a source any way you'd like.
Table group name
We combine this with the destination schema to form the Fivetran connection name <destination_schema>.<table_group_name>. This enables you to create multiple Merge Mode connections per destination schema. The Table group name value is used only in Fivetran and does not appear in your destination.
Folder path (optional)
This folder path is used to specify a portion of the bucket in which you'd like Fivetran to look for files. Any files under the specified folder and all of its nested subfolders will be examined for files we can upload. If no prefix is supplied, we'll look through the entire bucket for files to sync.
File pattern (optional)
The file pattern is a regular expression that we use to decide whether to sync certain files. It applies to everything under the prefix. For instance, suppose under the prefix logs you had three folders: 2017, 2016, and errors. Using the pattern \d\d\d\d/.*, you could exclude all the files in the errors folder, because \d\d\d\d only applies to the folders whose name consists of four consecutive digits, and because .* after / applies to any files in these folders. If you want to sync everything under the prefix, leave this field blank.
We recommend that you test your regex.
To sync files having file names with a specific string irrespective of the case, use the ?i modifier in your regex. For example, if you want to match all the files with a 'customer' string in the file name, specify the file pattern as (?i).*customer.*.
Archive file pattern (optional)
If there are multiple files within an archive (TAR or ZIP) folder, you can use the archive file pattern to filter those. For example, the archive file pattern .*json will only sync files within the archive that end in a .json extension.
We support this feature for the following connectors:
- Amazon S3
- Azure Blob Storage
- Google Cloud Storage
- Google Drive
- SFTP
- SharePoint
File type
The file type is used to let Fivetran know that even files without a file extension ought to be parsed as this file type. For example, if you have an automated CSV output system that saves files without a .csv extension, you can specify the CSV type and we will sync them correctly as CSVs. Every file we find in the source will be interpreted as the file type you select, so ensure that everything Fivetran syncs has the same file type.
Unstructured file replication Beta
Files
Files are stored in an object storage linked with a destination. To maintain consistency, the folder structure from the source, including the parent folder, is replicated in the object storage without any modification. To learn more about the exact storage location of unstructured files, see our Unstructured File Replication documentation.
We do not support renaming folders and moving files between folders.
Metadata
The metadata for each file is maintained in the schema and table of a particular destination. The following columns capture the metadata for each file:
_fivetran_file_path: Stores relative source path and reference to the respective file’s location in the destination.url: Stores source URL linking to the file’s original location.
For more information, see our ERD.
Changes in the source
| Source observation | Action in stage | Action in metadata/entity table |
|---|---|---|
| New file | Inserted | A new metadata row is inserted. |
| Modified file | Old file is replaced | Row updated per metadata of the modified file. |
| Deleted file | No change | _fivetran_deleted set to true. |
CSV File Options
Delimiter (optional)
The delimiter is a character used in CSV files to separate one field from the next. If this is left blank, Fivetran will infer the delimiter for each file, and files of many different types of delimiters can be stored in the same folder with no problems. If this is not left blank, then all CSV files in your search path will be parsed with this delimiter. You can also specify a multi-character delimiter in this field. A custom multi-character delimiter (excluding "\t" and "\s") should be mentioned only if the source contains only CSV files.
If you don't populate this field and leave it blank, we infer it as a single-character delimiter, not a multi-character delimiter. We can infer the delimiter from ,, ;, |, \t, and Unit Separator. We can't infer space as a delimiter. If a file has space as its delimiter, you must enter \s in the Delimiter field. Since we can't infer a multi-character delimiter, to correctly parse the CSV files having a multi-character delimiter, you must mention the delimiter in this field.
Quote character (optional)
The quote character is used in CSV files to enclose fields that contain the delimiter character. If you specify the quote character, Fivetran will parse all CSV files in your search path with this quote character. Default quote char is " (double quote).
Non-Standard escape character (optional)
CSVs have a special rule for escaping quotation marks as opposed to other characters - they require two consecutive double quotes to represent an escaped double quote. However, some CSV generators do not follow this rule and use other characters like backslash for escaping. Only use this field if you are sure your CSVs have a different escape character.
Null sequence (optional)
CSVs have no native notion of a null character. However, some CSV generators have created one, using characters such as \N to represent null. Only use this field if you are sure your CSVs have a null sequence.
Skip header lines (optional)
Some CSV-generating programs include additional header lines or empty lines at the top of the file. They consist of a few lines that do not match the format of the rest of the rows in the file. These header rows can cause undesired behavior in Fivetran because we attempt to parse them as if they were records in your CSV. By setting this value, you can skip fixed-length headers at the beginning of your CSV files.
Only use this field if you are sure your CSVs have more than one header line. We will skip these lines before we map the header to row data for the CSVs.
Skip footer lines (optional)
Some CSV-generating programs include a footer at the bottom of the file. It consists of a few lines that do not match the format of the rest of the rows in the file. These footer rows can cause undesired behavior in Fivetran because we attempt to parse them as if they were records in your CSV. By setting this value, you can skip fixed-length footers at the end of your CSV files.
Headerless files (optional)
Some CSV-generating programs do not include column name headers for the files - they only contain data rows. By setting this value, you request Fivetran to generate generic column names following the convention of column_0, column_1, ... column_n to map the rows.
Only use this option if you are sure your CSVs do not have the header line, and the column orderings remain the same. Otherwise, it can cause undesired behavior in the schema. For example, if the column order changes in the source, we won't be able to identify column changes. If you have no control of the CSV generator and still want to turn on the empty file option, we recommend always keeping the error handling option "on" to catch potential errors.
Allow inconsistent row lengths (optional)
This toggle allows Fivetran sync rows in CSV files with inconsistent length. If you set the Allow inconsistent row lengths toggle to ON, Fivetran syncs the rows even if they are shorter or longer than the header row. For the shorter rows, where columns are added to make the row length consistent, the columns are populated with NULL values. For longer rows, the extra columns are named column_<position>, so if your header row has three columns — name, age, city — and a data row has five values, the fourth value is mapped to column_4 and the fifth to column_5. If you do not enable the toggle, Fivetran handles the inconsistent row lengths based on the option you selected in the error handling settings.
Line Separator (optional)
This field specifies the custom line separator for CSV files. The line separator is used in files to separate one row from the next. If you leave this field blank, Fivetran uses the new line character \n as the line separator by default. If you specify a line separator, Fivetran parses all the CSV files in your folder path with this line separator.
JSON Delivery Mode (optional)
This option is available for JSON or JSONL file types. Fivetran uses this option to choose how to handle your JSON data. Fivetran has two values for this feature, Packed and Unpacked. If you select Packed, Fivetran loads all the JSON data into the _data column without flattening it, or if you select Unpacked, Fivetran flattens one level of columns and infers their data types.
Syncing Excel Files in Merge Mode
To sync Excel files in Merge Mode, you must select xls/xlsx/xlsm as the file type in the connection setup form and then specify the cell reference. We use the cell reference to sync contiguous data to the right of the cell and below it in the Excel worksheet.
The cell reference follows the '<sheetName>'!<startColumnName><startRowNumber> format. For example, consider the following workbook, containing two Excel worksheets, 'Data 1' and 'Data 2'. 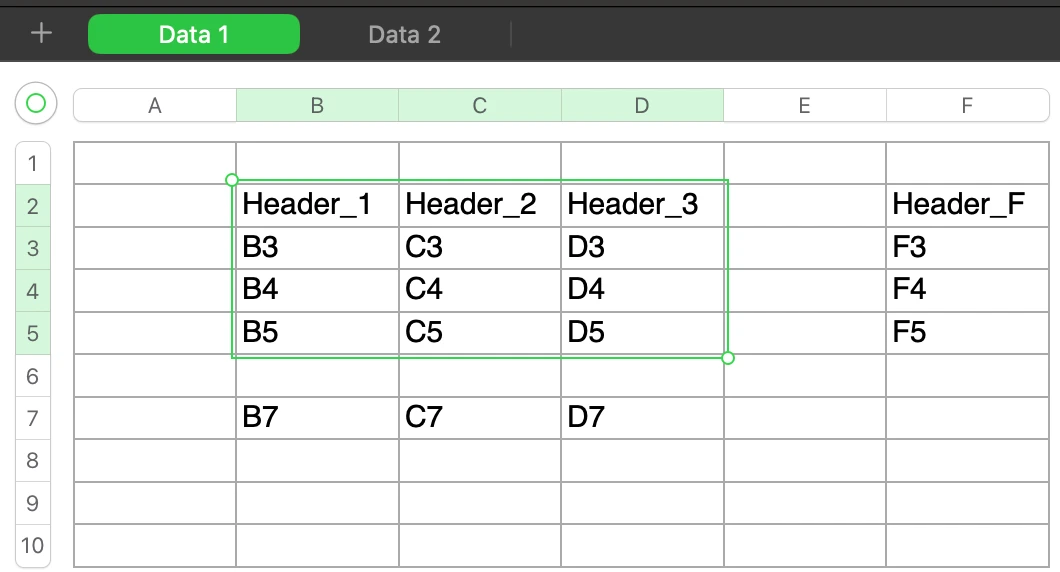
If you want to sync your data from cell B2 of the 'Data 1' worksheet, then your cell reference will be 'Data 1'!B2. The connection syncs data from the 'Data 1' worksheet starting at cell B2. We treat the row of the cell reference (in this case, row 2) as the header row, and use its values as the column names.
Identifying contiguous data
When syncing data, we first determine the contiguous data of cells by following the rules below:
Find the headers
- Starting from the first header cell, we include all adjacent header cells to the right until we encounter an empty cell in the header row.
- In the example, headers 'Header_1', 'Header_2', and 'Header_3' are included.
- 'Header_F' is not included because the cell in column E (E2) is empty, which breaks the header sequence.
Sync the data rows
- We include all rows directly below the headers until we encounter an empty row.
- In the example, rows 3, 4, and 5 are included.
- Row 7 (B7, C7, and D7) is not included because row 6 is completely empty for all header columns, breaking the contiguous block.
- We do not support finding data ranges if the rows contain merged cells.
- We do not consider the rows with merged cells and skip them while finding data ranges.
- We do not support syncing Excel files with only header rows.
Advanced configuration options
You can use the advanced configuration for highly specific cases.
Compression (optional)
The compression format is used to let Fivetran know that even files without a compression extension should be decompressed using the selected compression format. For example, if you have an automated CSV output system that GZIPs files to save space, but saves them without a .gzip extension, you can set this field to GZIP. The connection will then decompress every file that it examines using GZIP. If all of your compressed files are correctly marked with a matching compression extension (.bz2, .gz, .gzip, .tar, or .zip), you can select "infer".
Error handling (optional)
The error handling option enables you to choose how to handle errors in your files. If you select skip, we ignore any improperly formatted data within a file, allowing you to sync only valid data. However, if you select fail, we fail the sync with an error on finding any improperly formatted data. Regardless of the option you choose, you will receive a notification on your dashboard if we encounter any errors.
Archive folder pattern (optional)
If there are multiple files within the archive (TAR or ZIP) folders, you can use the archive folder pattern to filter those as well. For example, the archive folder pattern .*json will sync from an archive folder only those files that end in a .json file extension.
PGP Encryption (optional)
Fivetran provides this option to sync PGP encrypted and signed files. Fivetran needs the PGP Private Key, Passphrase (Optional), and Signer's Public Key (Optional) credentials to sync the PGP encrypted files. Fivetran uses these credentials to securely decrypt PGP-encrypted files and sync the data to your destination. All PGP decryption processes strictly comply with the RFC 4880 standard to ensure security and interoperability.
All PGP keys (private and public) must be in ASCII-armored format. Keys should include armor headers such as: -----BEGIN PGP PRIVATE KEY BLOCK-----. Binary-formatted keys (without headers) are not supported. To ensure the highest level of security and interactivity, for PGP decryption processes we strictly comply with the RFC 4880 standard.
Fivetran decrypts the files using these credentials and syncs them to your destination. This feature is currently available in Amazon S3, Azure Blob Storage, SFTP, FTP, Google Cloud Storage, and S3-Compatible Storage services only.
The PGP encryption option is not available with XLSX, XLS, and XLSM file formats.
Cloud Storage connectors
Fivetran supports syncing files from the following cloud storage services to your destination:
Syncing data from connections with storage services is optimized for buckets that receive periodic, automatic data dumps. These could be internal reports generated by your own tools, or APIs that we haven't yet offered full support for.
You can configure multiple storage connections such that they sync into a single schema. All file storage cloud connections are pull connectors – Fivetran periodically pulls new or changed data from the source bucket.
Cloud Collaboration connectors
Fivetran supports syncing files from the following cloud collaboration services to your destination:
You can sync any supported file from the cloud folder to your destination.
We sync all files in the cloud folder to your destination, even if someone without a Fivetran account uploaded them. Anyone with write access to the cloud folder can drop files into the folder; Fivetran automatically syncs the files from your cloud folder to your destination. For example, if you set up a Dropbox connection in Magic Folder Mode, anyone who can write files to the Dropbox folder can upload a file, and we will sync the file to your destination.
The OneDrive connector doesn't support Merge Mode.
File transfer protocols
Fivetran supports syncing files using the following file transfer protocols to your destination:
Each connection you create connects to a single file directory, and its underlying data is loaded into multiple destination tables based on file patterns. Any files added to that specified directory will be pulled and loaded into their respective destination tables.
You can configure multiple connections such that they sync into a single schema. All file transfer connections are pull connectors - Fivetran periodically pulls new or changed data from the FTP or SSH server.
Our SFTP connector offers a dual-mode sync strategy. It supports syncing files in both Magic Folder Mode and Merge Mode. For more information, see our Sync modes.
Email connector
We extract the attachments from the email, parse the attachment data, and upload them to your destination. For more information, see our Email connector documentation.
Google Sheets connector
We connect to your Google Sheet, fetch the data from the designated named range, then create a matching table in your destination and load its corresponding initial data. We then continue to check and sync changes to the named range on the update frequency that you specify. For more information, see our Google Sheets connector documentation.
Frequency of updates
By default, all connections sync new and modified files every 15 minutes. Depending on the size of each update or the number of tables, it may take longer. In that case, the connection will update at the next 15-minute interval, i.e.
Update X Start: 9:00 am
Update X Finish: 9:18 am
Update Y Start: 9:30 am
You can change the update interval in the dashboard. A connection sync that encounters an error will re-try periodically after the shorter of the sync frequency or 1 hour.
Files that are added after the sync has begun are processed in the next sync.
Supported file formats
| File Format | Specification | Notes |
|---|---|---|
| Separated Value Files (CSV, TSV, etc.) | RFC-4180 | |
| JSON text files delimited by new lines | RFC-7159 | |
| JSON Arrays | RFC-7159 | |
| Avro | Apache Avro 1.8.2 | |
| Parquet | Apache Parquet | We support apache-parquet-format 2.8.0 and Row Group Size up to 1.5 GB. |
| Excel (XLS, XLSX, and XLSM) | Microsoft Excel |
|
| Google Sheets | Google Sheets | Cloud Collaboration connectors, Google Drive connectors configured in Merge Mode, and Google Sheets connectors. |
| XML | XML | We support syncing xml files to your destination in Merge Mode. We load your XML data into the _data column without flattening it. For more information about the file size, see our documentation. |
Use the Google Sheets connector to sync data from a specific named range in your file to a single destination table. Use the Google Drive connector to sync data from multiple sheets within a spreadsheet as unique destination tables.
Supported file compression
TAR and ZIP archives
BZip2 and GZip compression
The connections in Magic Folder Mode don't support file compression. We don't sync compressed files to your destination.
Supported encodings
- UTF-8, UTF-16, and UTF-32, with big or little endian order
- UTF-8 encoding is assumed if no Byte-Order Mark is present at the beginning of a file
Syncing empty tables and columns
For supported Files connectors, Fivetran creates empty columns in your destination. Fivetran initially creates these columns with the STRING data type. However, in subsequent syncs, when Fivetran detects non-null values for these columns, it updates the data type to match the inferred type and recreates the destination columns.
For headerless CSV files, Fivetran generates column names, such as column_0, column_1, ... column_n, and creates the corresponding destination columns even when the source values are empty or null.
Connections in Magic Folder Mode and the Google Sheets connector do not support creating empty tables in your destination.
Files that contain only headers can populate schema metadata. However, Fivetran creates a destination table only when file contains at least one row with data available for sync.
For spreadsheet files, we don't create a destination table if the worksheet is empty. We don't create a table if the entire first row of the worksheet is empty. We create a column only if its first row is not empty.
Syncing empty rows in files
Fivetran does not exclude empty rows in your source files during the sync. Instead, it syncs these rows to your destination with null values.