Databases
Your production database contains your most important data, and Fivetran's database connectors are our most important and battle-tested connectors. Our database connectors are designed for correctness and safety. Correctness means that your destination should always be an accurate replica of your database source. Safety means that no matter what, Fivetran should never cause problems in your source database.
Supported databases
Fivetran supports replicating data from the following databases:
- Amazon DynamoDB
- Azure Cosmos DB
- BigQuery Beta
- CockroachDB Private Preview
- Convex Partner-Built Beta
- Databricks Private Preview
- Db2 for i Beta
- DocumentDB
- Elasticsearch Beta
- Firebase Beta
- MariaDB
- MongoDB
- MySQL
- OpenSearch Beta
- Oracle
- PlanetScale Partner-Built Beta
- PostgreSQL
- Redshift Private Preview
- SAP ERP
- Snowflake Beta
- SQL Server
If you'd like to integrate with a database that's not listed here, reach out to Fivetran support.
Database integration overview
- Connect: Connect us to your production database or read-replica through a specific Fivetran user that you create in your database. For instructions on creating a Fivetran user, see the setup guide for your database type.
- Initial sync: Fivetran discovers all selected tables and automatically pulls all historical data for all objects to which it has access. The duration of initial syncs varies by customer, but most syncs finish within a day.
- Transform and map schema: Fivetran parses through all your data, typecasting and mapping every column in the source object to a column in the corresponding table in the destination. We transform any data types that are not natively supported in the destination into data types that are accepted. Fivetran does not do any aggregations at this stage.
- Load: Fivetran automatically creates schemas and tables for each mapped source object in the destination. We populate these tables with the data from the initial sync.
- Incremental updates: Fivetran incrementally updates the data in your destination in batches, using a merge operation (upsert & insert) to only update new or changed data. You can choose how often these batches run, from every 5 minutes to every 24 hours. Fivetran's unique system automatically recognizes schema changes in your data source and persists these changes to the destination.
Connecting your database
Connection Options
Because our database connectors are pull connectors, Fivetran must have a way to connect to your source database. The three connection strategies that we support are:
- Connect directly to the database port on your database host
- Connect via an SSH tunnel
- Connect via a reverse SSH tunnel
See the Connection Options guide for more details.
Safety
Fivetran is a good citizen of your database. You can connect Fivetran to a read-replica of your database if you want to isolate us from your production workloads, but you can also connect us directly to your production instance. Our queries are designed to minimize contention with your production queries in two major ways:
- Our queries generate simple execution plans that can run concurrently with many other queries. They don't take higher priority over your other workloads.
- We use parallel processing to sync data from your database to your destination. Using multiple threads makes your syncs faster than using a single thread, since we can run multiple queries simultaneously. However, multiple threads also compete for resources slightly more than a single thread does. We limit the number of threads that we use to ensure that we don't compete too much with your concurrent queries.
Initial sync
During the initial data sync, Fivetran connects to your source database and copies the entire contents of every table that you’ve selected to sync. The way we perform that initial sync depends on whether your source database has a B-tree (for example, MySQL or SQL Server) or a heap (for example, PostgreSQL or Oracle) data structure.
NOTE: The SAP HANA database connector has a different initial sync strategy from our other database connectors. For more information, see our SAP ERP on HANA initial sync documentation.
B-Tree databases
For B-Tree tables, we perform the initial sync using a series of queries that look like this:
select *
from {table}
where {primary key} > ?
order by {primary key}
limit {page size}
This is an efficient strategy because each table in a B-tree database is intrinsically ordered on the {primary key}. There is no need for a sort by clause in this query, because each table is already in {primary key} order.
Heap databases
For heap databases, the initial sync is more complicated. For small-to-medium tables, we sync the entire table with a single select * query. For large tables, we break the contents into more manageable blocks based on the order in which the data was added to the database. We then sync the blocks in chronological order.
Excluding source data
If you don’t want to sync all the data from your source database into your destination, you can easily exclude schemas, tables, or columns from your syncs on your Fivetran dashboard. Alternatively, you can change the permissions of the Fivetran user in your source database and restrict its access to certain tables or schemas.
Check initial sync progress
To monitor the progress of your initial sync, you can use either of the following:
- Our free Fivetran Platform Connector, which we automatically add to every destination you create.
- External log services.
Using either of these options, you can:
Check the most recent log record to track the progress of your table imports.
- All tables marked NOT STARTED have not been imported yet.
- All tables marked COMPLETED have been imported.
Check older log records to track your sync progress.
Transformation and mapping overview
Similar to Cloud API connections, Fivetran's database replication product pursues a "sync-all" strategy. This means we sync as many source schemas and tables as possible with as little setup and configuration as possible.
However, unlike Cloud API connections, our database connectors do one-to-one mapping of source schemas and tables to destination schemas and tables. Columns are also mapped one-for-one wherever possible, except when no compatible data type exists in the destination. In that case, we will transform data types that are not supported in the destination into data types that are supported.
Loading schemas and tables
Schemas and tables
A single database connector can replicate multiple schemas (represented below by the blue connector icon), as well as all of their underlying tables. These schemas are stored in the destination in the same logical schema/table hierarchy as exists in your source database. In the destination, each schema name is prepended with the prefix of your choice.
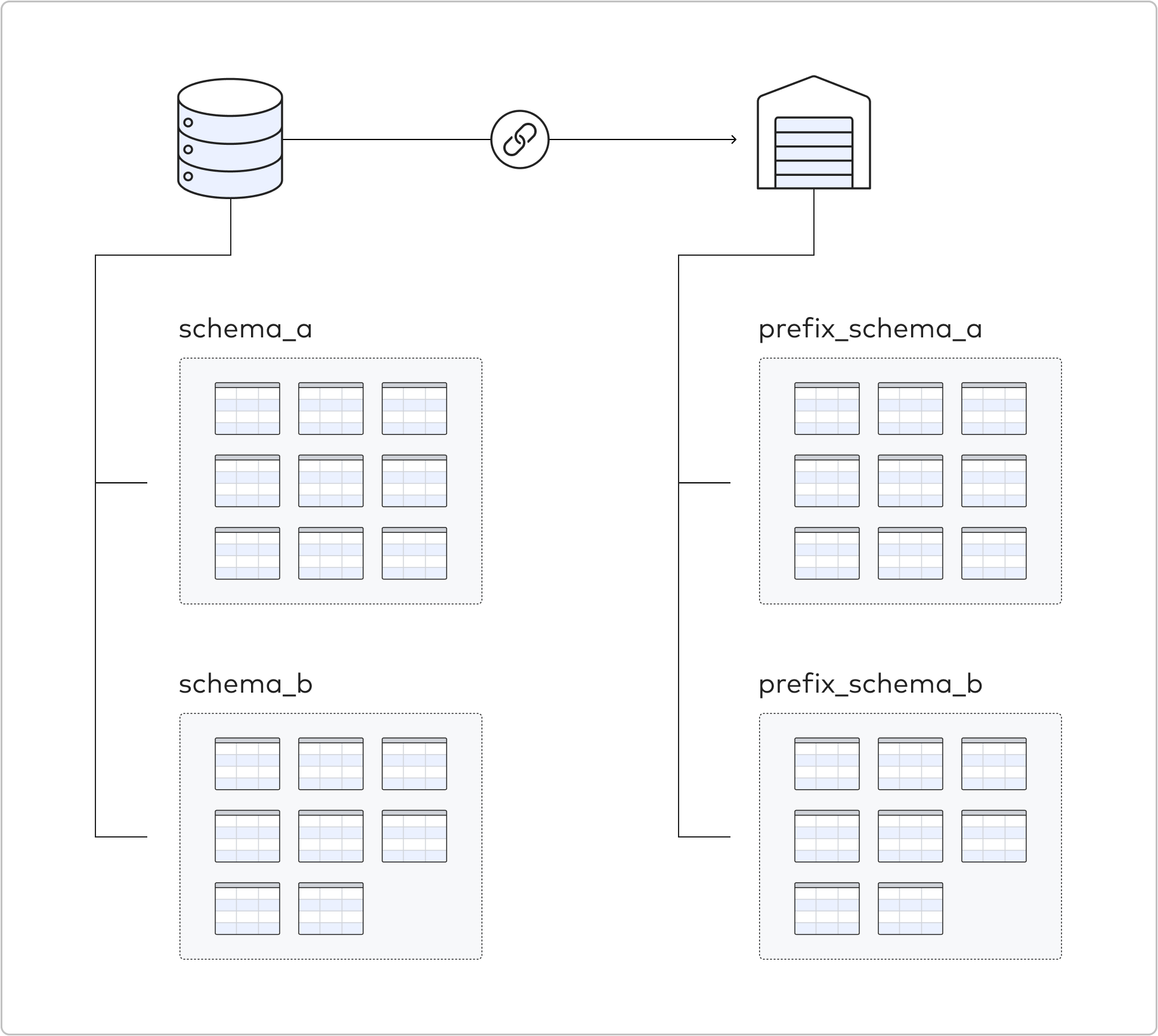
Mapping name from source to destination
For database connectors, we do minimal name-changing between the source and destination. This allows SQL queries written for the source database to be easily ported to the destination, without having to change the field names in the queries. There are only a few exceptions to this rule:
Schema names that have the connector name prepended, and
Schema, table, or column names that violate Fivetran’s naming conventions. In these cases, we apply the following rules in the order in which they are listed:
- Non-ASCII characters (such as Chinese characters) are replaced with a transliteration.
- Remove accent marks from Latin characters
- We only allow letters, numbers, and underscores. Any other character is replaced with an underscore.
- Upper-case letters are converted to lower-case.
- The character limit for names is 127 characters. Any name with more than 127 characters is truncated to the limit.
Changing the destination schema name
We do not support changing the connector name. It is therefore not possible to change the name of the destination schemas.
If you want to change the name of your destination schema, you can set up a new connector and remove your old connector once the new one has finished syncing. You can also create a SQL view on top of the existing schema with a new name that works better for your BI or SQL layer.
Incremental updates
Fivetran moves to performing incremental updates of any new or modified data from your source database. During incremental syncs, we use your database’s native change capture mechanism to request only the data that has changed since our last sync, including deletes. Each database uses a different change capture mechanism:
- Changefeeds (CockroachDB)
- Change Streams (DocumentDB)
- DynamoDB Streams (Amazon DynamoDB)
- Change Data Capture (MariaDB)
- Oplogs (MongoDB)
- Binary logs (MySQL)
- LogMiner (Oracle)
- Logical replication or XMIN system column (PostgreSQL)
- Change tracking or change data capture (SQL Server)
- Shadow tables and triggers (SAP ERP on HANA)
- Fivetran Teleport Sync
- Firebase Beta
- MySQL
- Oracle Beta
- PostgreSQL
- SQL Server
During incremental syncs, Fivetran maintains an internal set of progress cursors which allow us to track the exact point where our last successful sync left off. We record the last sync for each row in a column called _fivetran_synced (UTC TIMESTAMP). This provides a seamless hand-off between syncs, ensuring that we do not miss any data.
Because of our progress cursors, Fivetran's system is extremely tolerant to service interruptions. If there is an interruption in your service (such as your destination going down), Fivetran will automatically resume syncing exactly where it left off once the issue is resolved, even days or weeks after, as long as log data is still present.
Deleted data
All database connectors support syncing deleted data. For tables with a primary key, we mark deleted rows as deleted in your destination, but do not actually remove them. We create an extra column in the destination to mark deleted rows, "_fivetran_deleted" (boolean). Deleted rows will have a true value in this column.
The following databases support tables without a primary key:
The way we treat deleted rows in these tables varies by connector type. See the relevant database connector's documentation page for more information.
Frequency of updates
By default, all database connectors sync new and modified data every 15 minutes. Depending on the size of each update or the number of tables, syncs may take longer than that. In that case, the next data sync will start at the next 15-minute interval. For example:
Update X Start: 9:00am
Update X Finish: 9:18am
Update Y Start: 9:30am
You can change the update interval in your Fivetran dashboard. When database syncs encounter repeated errors, our system automatically retries the sync after the update interval or one hour, whichever is shorter.
Migrating service providers
If you migrate from one database service provider to another, we will need to do a full re-sync. That's because when you switch to another provider, Fivetran can't keep track of where our last sync left off, as the new service provider won't retain the same progress cursor and changelog information as the previous provider. Examples of switching service providers include:
- MySQL (Self-Hosted) <--> MySQL RDS
- PostgreSQL (Self-Hosted) <--> PostgreSQL RDS
- SQL Server (Self-Hosted) <--> SQL Server RDS
See the individual database guides for specific instructions on how to migrate.
Fivetran Teleport Sync
Fivetran Teleport Sync is a proprietary incremental sync method that can incrementally replicate your database with no additional setup other than a read-only SQL connection.
Fivetran Teleport Sync is an alternative to change log replication for incremental syncs. We recommend using it in the following cases:
- You cannot or do not want to provide Fivetran access to your database's change logs
- You need to limit the tables or columns that Fivetran can read from
- Change log syncing is slow or resource intensive due to the number of updates
- You load data into the source database using a TRUNCATE/LOAD or BACKUP/RESTORE process that invalidates change logs
- You currently use snapshot syncing and want a faster method
Fivetran Teleport Sync works by running SQL queries in your database that return a compressed version of your data in a form that can be used to find the changed data.
Teleport sync general limitations
- Review the limitations specific to each connector to verify whether tables without a primary key are supported.
- Tables without a primary key(if the database supports it) may experience slower performance compared to tables equipped with primary keys.
- The speed of data imports and incremental synchronizations can vary considerably across different connectors. Reference the specific databases teleport sections for further suggestions.
- Performance can also be influenced by the type of hardware used and the specific deployment location of the database. Look at specific databases teleport docs on limitations for further guidance.
- Certain Data Definition Language (DDL) changes that may require a table re-sync are listed in Automatic table re-sync for Teleport sync method.
- If you update large portions of a table between syncs, Fivetran Teleport Sync may be unable to determine the changes since the previous sync. When this occurs, the connector will re-sync the entire table to capture the latest data. To avoid these table re-syncs, we recommend that you increase the sync frequency of the connector.
Automatic re-sync
Under certain circumstances, Fivetran automatically performs a full table re-sync or a full source re-sync of your source database. The specific circumstances vary by database type.
IMPORTANT: The full table or full source re-sync automatically occurs at your next scheduled sync time. For example, let's say that your connector syncs every day at 2pm and you make database updates that necessitate a re-sync at 4pm. We schedule your automatic re-sync for 2pm the next day.
Automatic full table re-sync
Schema changes in the source database are the most common trigger for a full table re-sync. When the schema changes in the source, a full table re-sync lets us propagate these changes to your destination. You don’t have to take any action to initiate the re-sync, and the only difference you might notice is a longer than usual sync. See the chart below for specific causes for each database.
Note that we only perform automatic table re-syncs for SQL databases. Schema changes to NoSQL databases don’t require re-syncs, because non-relational databases do not have fixed schemas.
Automatic table re-sync for SQL databases
We schedule automatic full table re-syncs for SQL databases in the following circumstances:
| Database | What schedules a full table re-sync |
|---|---|
| BigQuery | If you enable syncs for a table that you had previously excluded from syncs |
| CockroachDB | Expired GC threshold |
| MariaDB | A DDL (Data Definition Language) statement on a table without a primary key A DDL statement that re-orders columns A DDL statement that changes the column definition for SET or ENUM type columns A primary key change If you enable syncs for a table that you had previously excluded from syncs For Teleport syncs: if we encounter an error retrieving or processing a snapshot For Teleport syncs: if a DDL change contains a default value with a type other than Instant, LocalDate, certain LocalDateTime types, Boolean, String, Short, Int, Long, Float, Double, BigDecimal, or Json Any TRUNCATE DDL statements for tables that you have included in syncs |
| MySQL | A DDL (Data Definition Language) statement on a table without a primary key A DDL statement that re-orders columns A DDL statement that changes the column definition for SET or ENUM type columns A primary key change If you enable syncs for a table that you had previously excluded from syncs For Teleport syncs: if we encounter an error retrieving or processing a snapshot For Teleport syncs: if a DDL change contains a default value with a type other than Instant, LocalDate, certain LocalDateTime types, Boolean, String, Short, Int, Long, Float, Double, BigDecimal, or Json Any TRUNCATE DDL statements for tables that you have included in syncs |
| Oracle | A statement that changes a table’s schema If you enable syncs for a table that you had previously excluded from syncs A DDL statement that creates, deletes, or changes the position of a column If the table's SCN is no longer available to us Non-zero status for a LogMiner event If we've rescheduled a re-sync more than a few times, we stop the sync and generate a Task in your dashboard |
| PostgreSQL | If you enable syncs for a table that you had previously excluded from syncs If XMIN values get frozen for a table Schema changes in PostgreSQL don’t trigger a re-sync |
| SQL Server | If you enable syncs for a table that you had previously excluded from syncs If you change incremental sync methods If the table's LSN is no longer available to us Any TRUNCATE DDL statements for tables that you have included in syncs |
| SAP HANA | If you enable syncs for a table that you had previously excluded from syncs |
| Snowflake | If you enable syncs for a table that you had previously excluded from syncs Any DDL changes for tables that you have included in syncs, such as removing columns and adding columns with non-static default values |
Automatic table re-sync for NoSQL databases:
We schedule automatic full table re-syncs for NoSQL databases in the following circumstances:
| Database | What schedules a full table re-sync |
|---|---|
| Amazon DynamoDB | Change in pack mode Expired DynamoDB streams cursor |
| MongoDB | Change in pack mode Expired change streams cursor |
| DocumentDB | Expired change streams cursor |
Automatic full source re-sync
Expired change logs require a full source re-sync, because we cannot perform our usual incremental syncs without them. Change logs can expire either in the sense of time or storage space. For example, logs might expire if you set your log retention period to 48 hours, and Fivetran isn’t able to sync for more than 48 hours. Logs can also expire if the storage space you allocated to them fills up. A full source re-sync ensures that the data in your destination matches your source data, and once it is complete, we resume our usual incremental sync schedule.
Automatic full source re-sync for SQL databases
We schedule automatic full source re-syncs for SQL databases in the following circumstances:
| Database | What schedules a full source re-sync |
|---|---|
| MariaDB | Expired logs (Fivetran generates a task in your dashboard when we detect expired logs and need to perform a full source re-sync) |
| MySQL | Expired logs |
| Oracle | Expired logs |
| PostgreSQL | Expired logs |
| SQL Server | Expired logs |
Automatic full source re-sync for NoSQL databases
We schedule automatic full source re-syncs for NoSQL databases in the following circumstances:
| Database | What schedules a full source re-sync |
|---|---|
| Amazon DynamoDB | Expired DynamoDB streams cursor |
| MongoDB | Expired oplogs |
Automatic table re-sync for Teleport sync method:
We schedule automatic full table re-syncs for Teleport sync method in the following circumstances:
- Renaming a table/schema
- Dropping columns
- Unsupported column type changes
- Adding a column with a non-static default value
- All DDL changes for pk-less tables will trigger a re-sync
Unsupported operations
Fivetran’s database connectors deliberately do not support some operations.
Non-primary replicas in SQL Server
In SQL Server, you cannot connect Fivetran to a non-primary replica if you use Change Tracking (CT) as your incremental sync method. We can only sync with the primary replica in an availability group, because Microsoft does not allow CT to be enabled on any replica that is not designated as primary.
Repeated table truncations in SQL Server
If you use CT as your incremental sync method, repeated table truncations prompt table re-syncs because they continuously invalidate the table's CT system version. We recommend you avoid truncating or use a different syncing mechanism like Fivetran Teleport Sync if you expect truncating in your current source workflow.
Retention periods under 24 hours
A log retention period must be at least as large as your sync period, or else the logs will expire in between Fivetran connector syncs. We recommend setting your retention period to at least 48 hours to ensure there are sufficient logs for proper replication.
Data warehouses as sources
Fivetran supports the following data warehouses as sources:
You cannot connect Fivetran to other data warehouses like Teradata, Netezza, or Vertica as sources, because they have no change capture mechanism. Instead, connect us to whatever source databases are feeding these warehouses.
If you use a regular OLTP database like PostgreSQL or Oracle as a destination, you can connect it to Fivetran as a source. However, your Fivetran syncs may be unacceptably slow if you are populating this destination by periodically truncating and re-creating tables. Be sure to test this issue during your evaluation of Fivetran to make sure you get acceptable performance.
Must allow initial syncs to run without interruption
You cannot run initial syncs within a limited time window (for example, only allow Fivetran to sync from midnight to 8 a.m.). Time limits increase the likelihood that our connection will be interrupted and the sync will need to restart. There is no need to restrict our syncs to off-times; our initial sync queries are designed to be easy for your query planner to schedule around, so the impact on your production workload should be minimal.
Guaranteed initial sync completion dates
Fivetran cannot guarantee a completion date for your initial sync. While Fivetran works hard to make your initial sync as fast as possible, the duration of this process is different for every customer.
Skipping historical syncs
You cannot skip your historical sync.
Starting historical syncs from a specific date
You cannot start your historical sync from a specific date (for example, only sync data from August 2014 forward).
One-time production data migrations
Fivetran does not support one-time migrations of production data.