Deployment Models
Fivetran offers two deployment solutions to facilitate efficient data integration for various business environments. Each solution serves different operational and security needs, allowing organizations to select the most suitable option based on their specific requirements. These solutions include the following deployment models:
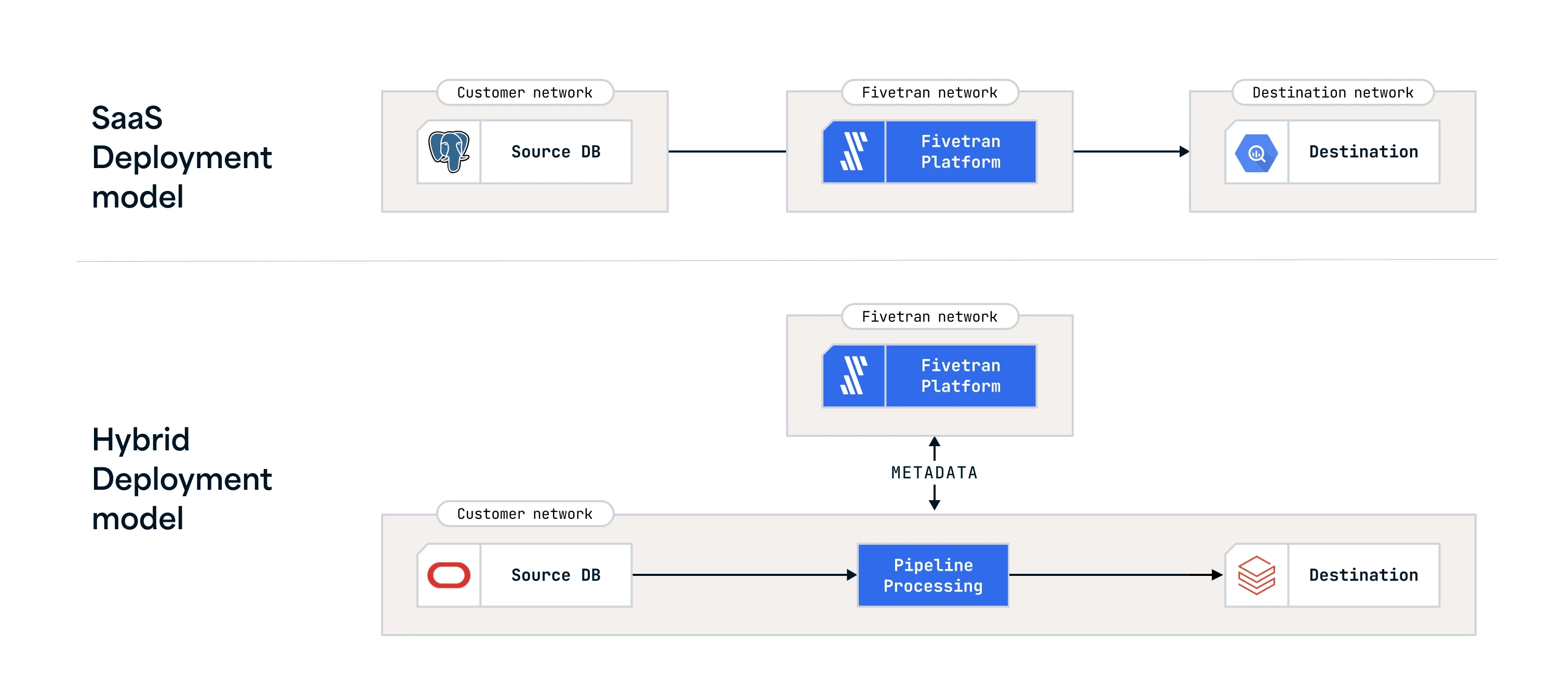
SaaS Deployment: In this model, data processing is handled entirely within the Fivetran cloud, which can be selected based on your preferred cloud service provider and pricing plan. The SaaS Deployment model is ideal for businesses looking for a hands-off approach to data processing, allowing them to leverage the Fivetran cloud and expertise with minimal internal resource investment. The model supports a variety of connectors (such as applications, databases (including High-Volume Agent (HVA) connectors), files, events, functions, and logs) and destinations.
Hybrid Deployment: The Hybrid Deployment model provides a balance for organizations that need to keep their data local for security or compliance reasons but still want to benefit from Fivetran managed service. The model allows organizations to process data locally within their own network while leveraging the Fivetran cloud for orchestrating and configuring all the data movement. The Hybrid Deployment model is supported by multiple Fivetran connectors and destinations.
Architecture
The following architecture diagram provides an overview of our deployment models.