SaaS Deployment
Fivetran's SaaS Deployment model offers a fully managed, cloud-based data integration solution. It is designed to connect to various data sources and seamlessly load data into designated destinations, ensuring efficient data management and analytics.
Architecture
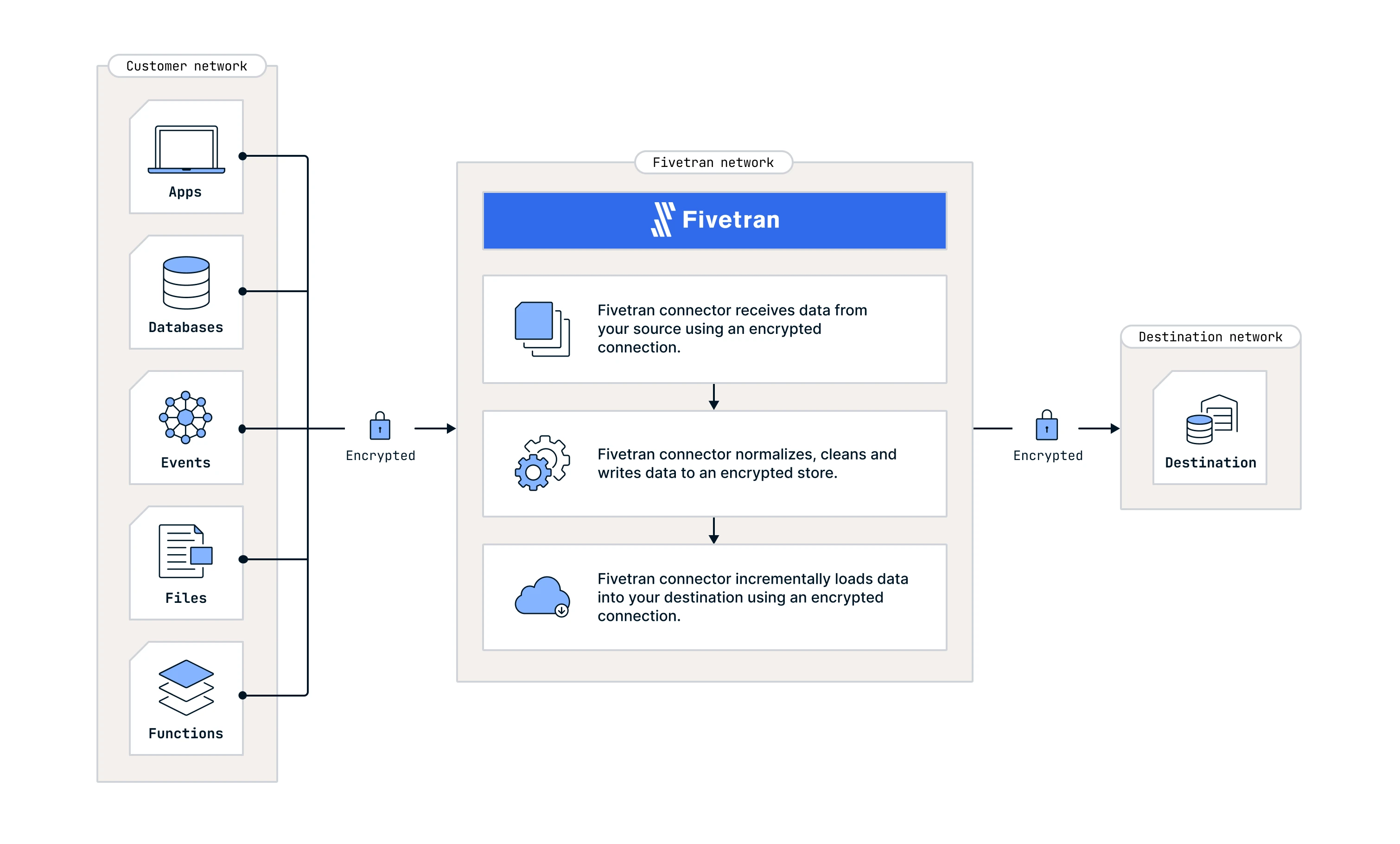
Key capabilities
Multi-source connectivity: Fivetran connects to all of your supported data sources and loads the data from them into your destination. Each data source has one or more connections that run as independent processes that persist for the duration of one update. A single Fivetran account, made up of multiple connections, loads data from multiple data sources into one or more destinations.
Types of connectors: Fivetran connects to your data sources using our connectors. Fundamentally, there are two different types of connectors: push and pull.
Pull connectors: Fivetran's pull connectors actively retrieve, or pull, data from a source. Fivetran connects to and downloads data from a source system at a fixed frequency. We use an SSL-encrypted network connection to the source system to retrieve data using a variety of methods: database connections using ODBC/JDBC, or web service APIs using REST and SOAP. In practice, the method or combination of methods is different for every source system.
Push connectors: In push connectors, such as Webhooks or Snowplow, source systems send data to Fivetran as events. Once we receive the events in our collection service, they are initially buffered in a queue. We then store the event data as JSON in our cloud storage buckets. During the sync, we push the data to your destination. For more information on how sync works in our push connectors, see our Events documentation.
Data ingestion and preparation: Once the sync process ingests the data query results, Fivetran normalizes, cleans, sorts, and de-duplicates the data. The aim of this process is to optimally format the data for the destination. Fivetran uses a queue to buffer incoming source data, ensuring that in cases of destination load failures due to transient errors or destination unavailability, the data retrieval from the source is not duplicated. This limits the impact of destination outages and improves Fivetran reliability; unprocessed data found in the storage queue is prioritized, and all buffered data is securely encrypted and retained until it is successfully loaded into the destination.
Parallel processing: The ingestion processes run in parallel with the preparation and load processes. This strategy ensures that the destination data load process doesn't block the source data ingestion process.
Temporary data storage: Fivetran outputs the finalized records to a file in a file storage bucket. We encrypt this file with a separate ephemeral key that is known only to the data-writing process. We automatically delete this temporary file after its successful upload to your destination. We automatically choose the bucket based on the following factors:
For most destinations:
- your Fivetran plan
- selected data processing region
- selected cloud service provider (CSP)
- selected CSP region
For Redshift, your selected cluster region
See our Data Residency documentation and Data Retention documentation for details.
Data load into destination: From the temporary data storage, Fivetran copies the file into staging tables in the destination. In the process, we transmit the ephemeral encryption key for the file to the destination so it can decrypt the data as it arrives. Before we write the data into the destination, we update the schema of existing tables to accommodate the newer incoming batch of data. We then merge the data from the staging tables with the existing data present in the destination. Finally, we apply the deletes (if any) on the existing tables. Once we complete the write process, data sync process terminates itself. A system scheduler will later restart the process for the next update.