



Data engineers overworked? Sign up for the free, definitive guide to data integration!
Download NowThe following blog post is an excerpt from the book, The Essential Guide to Data Integration: How to Thrive in an Age of Infinite Data. The rest of the book is available to you for free here.
Continued from Approaches to Data Integration.
A powerful argument against constructing your own ELT pipeline is the cost of building and maintaining it, in terms of time, money, morale and lost opportunities. Roughly 80% of an average data scientist’s time is spent constructing data pipelines — a task for which most data scientists have limited aptitude, interest or training.
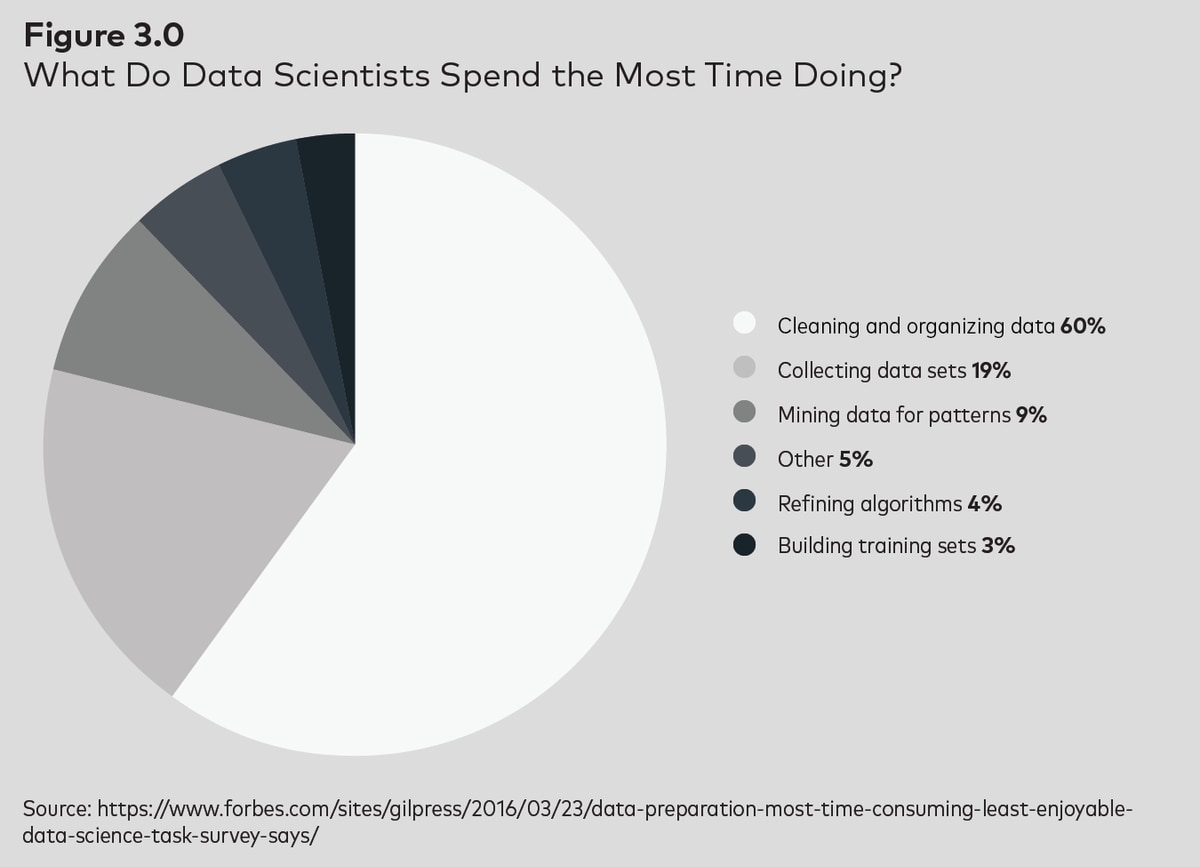
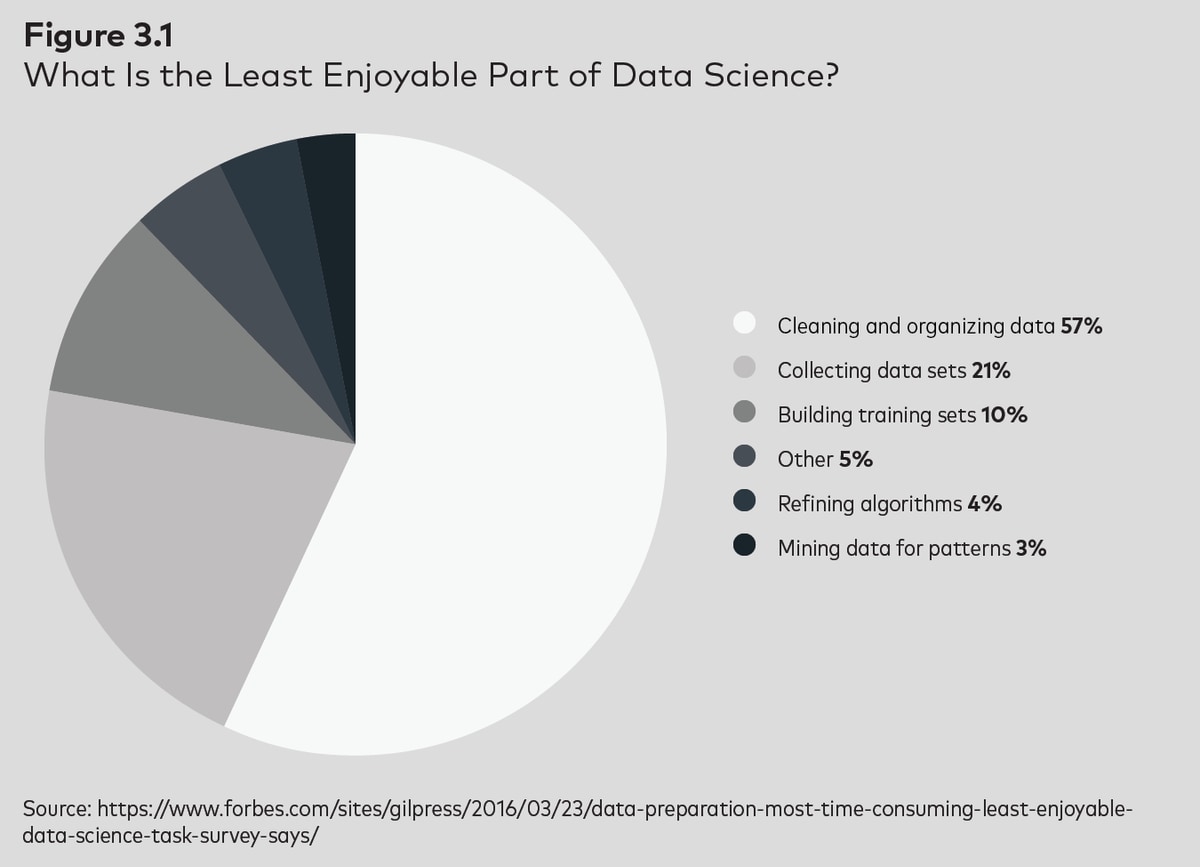
Suppose your organization needed five SaaS connectors.
Each of the five connectors takes about five weeks for an engineer to build, or five person-weeks (pw):
(5 connectors) * (5 pw)
Each connector will likely need a dedicated week of maintenance work per quarter, adding up to four weeks per year:
(5 connectors) * (5 pw + 4 pw)
(5 connectors) * (9 pw) = 45 pw
That makes 45 weeks out of 52 weeks in a year. Assuming a slightly generous vacation policy, that is essentially a year’s worth of work for a software engineer who costs about $120,000 before accounting for benefits.
In subsequent years, your engineer will continue to update each quarter (four weeks) and handle bugs and edge cases as they crop up (one week), for a total of five pw per connector.
(5 connectors) * (5 pw) = 25 pw
That makes 25 weeks out of 52 weeks in a year dedicated to ongoing maintenance. Let’s ballpark the cost to half the engineer’s yearly salary, or $60,000.
These costs will, of course, scale in direct proportion to the number of data sources you use.

The sample Gantt chart above demonstrates the cyclical, recurring nature of data engineering work, even under an ELT framework, as upstream schemas continue to change.
Morale
If you want to keep your analysts, engineers and managers happy, consider the following problems associated with building your own connectors or manual reporting:
- Diversion from other software engineering, data science or analytics duties
- Frustration and exhaustion from the complexity of maintaining data integrity
- Downtime caused by continually increasing complexity
- Misguided decisions caused by lags between requests for business intelligence and delivery of actionable insights
For most data professionals, database maintenance is a chore, not an aspiration.
Learning curves
Not all APIs are tractable enough to be integrated in five weeks. Some ignore best practices, some are poorly documented, and some are just very complex.
Data from an enterprise resource planning (ERP) tool, for instance, might encompass every imaginable business activity, and contain hundreds of individual tables with complex interrelations. It can take many iterations to build a mature piece of software around such a data source, multiplying the costs above.
Complexity at scale
It is highly unlikely that your organization’s data needs will stop at five connectors. A typical company now uses more than 100 apps.[1] It’s hard to justify expanding your team’s obligations when you can cost-effectively outsource pipeline engineering.
Standardization
Connectors built by an outside party become robust through testing against dozens of corner cases from a wide range of customers. These connectors produce standardized data sets with standardized schemas.

This also allows any organization that uses the same connectors to leverage the same transformations, because the data is all structured exactly the same way. Plug-and-play recipes or templates of this kind can be written in SQL or languages specific to a BI platform, such as LookML.
Making the Case for Buying
You might encounter some resistance in your organization if you propose buying a data pipeline tool. Data engineers might find the prospect of automating some of their work threatening, and executives who are several degrees removed from the challenge might not immediately see the benefits.
Win Over Engineers
Engineers sometimes favor customization, fine-grained configurability, and control over accessibility. These talking points might help you win them to your cause:
How Building Pipelines Hurts You
- Complexity and long turnaround times produce painful bottlenecks.
- Without the ability to quickly make informed decisions, companies fail to adapt and fall behind the competition.
- Data busy work and chores are no fun.
How Outsourcing Helps You
- You’ll no longer be a bottleneck.
- Outside vendors who specialize in data connectors are far more knowledgeable and experienced at solving these problems, and have likely considered many more corner cases than you.
- ELT is a force multiplier. You can now manage a much larger range of connectors with a lot less effort.
- Fully managed ELT is incredibly intuitive and requires almost no training or instruction. You’ll have the time to do things other than learn highly tool-specific skills.
- You won’t have to keep hiring and managing more people for data engineering.
- You’ll have the opportunity to pursue highly strategic activities, e.g.:
- Custom tools and infrastructure for analysts
- Infrastructure to support AI and machine learning
- New software products
Focus on what engineers would rather spend their time doing. In practice, very few engineers aspire to write data connectors and would rather pursue higher-value projects.
Convince Your Boss
Executives who are a few degrees of separation away from data engineering may need to be convinced that the new tool justifies its premium price.
Highlight Other Companies’ Successes
Other companies’ experiences offer plenty of lessons. Work backward in stages, discussing the benefits of improved business intelligence and actionable insights first, and the prerequisites of realizing such improvements later.
Discuss Common Pain Points and Key Benefits
Common Pain Points
- Manual reporting has a very long turnaround time and is only marginally better than flying blind.
- Different business units have separate data silos and struggle to share relevant information.
- In-house tools become unsustainable as new data sources are added, data volume is increased, and performance requirements become more stringent.
- Legacy databases and on-premise data warehouses are reaching their performance and usability limits.
- Engineers have better things to do than maintain databases.
Key Benefits
- Time savings – dramatically shorter turnaround between reports
- Data gains – massive expansion of data availability and timeliness
- Quality gains – data is more comprehensive and timely
- Culture gains – data access and data-driven decisions democratized across the company
- Labor savings – less engineering time on bespoke integration tools and database maintenance; analysts don’t have to manually assemble reports
- New insights and products – relocating engineering time away from data integration means more bandwidth for exploring opportunities and developing products
Emphasize the benefits of good BI before discussing the technicalities of data warehousing and data integration.
Continue reading the next installment in the series here.
The excerpt above is from The Essential Guide to Data Integration: How to Thrive in an Age of Infinite Data. The book covers topics such as how data integration fuels analytics, the evolution from ETL to ELT to automated data integration, the benefits of automated data integration, and tips on how to evaluate data integration providers. Get your free copy of the guide today:






