

ETL means “extract, transform, and load” and refers to the process of moving data to a place where you can do data analysis. ETL tools make that possible for a wide variety of data sources and data destinations. But how do you decide which ETL tool — or ELT tool — you need?
The first step to making full use of your data is getting it all together in one place — a data warehouse or a data lake. From that repository you can create reports that combine data from multiple sources and make better decisions based on a more complete picture of your organization’s operations.
Theoretically, you could write your own software to replicate data from your sources to your destination — but generally it’s ill-advised to build your own data pipeline.
Fortunately, you don’t have to write those tools, because data warehouses are accompanied by a whole class of supporting software to feed them, including open source ETL tools, free ETL tools, and a variety of commercial options. A quick look at the history of analytics helps us zero in on the top ETL tools to use today.
The key criteria for choosing an ETL tool include:
- Environment and architecture: Cloud native, on premises, or hybrid?
- Automation: You want to move data with as little human intervention as possible. Important facets of automation include:
- Programmatic control
- Automated schema migration
- Support for slowly changing dimensions (SCD)
- Incremental update options
- Reliability
- Repeatability, or idempotence
We’ll cover each of these in detail below. But first, here’s a short background on how ETL tools came about and why you need an ETL tool.
The rise of ETL
In the early days of data warehousing, if you wanted to replicate data from your in-house applications and databases, you’d write a program to do three things:
- extract the data from the source,
- change it to make it compatible with the destination, then
- load it onto servers for analytic processing.
The process is called ETL — extract, transform, and load.

Traditional data integration providers such as Teradata, Greenplum, and SAP HANA offer data warehouses for on-premise machines. Analytics processing can be CPU-intensive and involve large volumes of data, so these data-processing servers have to be more robust than typical application servers — and that makes them a lot more expensive and maintenance-intensive.
Moreover, the ETL workflow is quite brittle. The moment data models either upstream (at the source) or downstream (as needed by analysts) change, the pipeline must be rebuilt to accommodate the new data models.
These challenges reflect the key tradeoff made under ETL, conserving computation and storage resources at the expense of labor.
Cloud computing and the change from ETL to ELT
In the mid-aughts, Amazon Web Services began ramping up cloud computing. By running analytics on cloud servers, organizations can avoid high capital expenditures for hardware. Instead, they can pay for only what they need in terms of processing power or storage capacity. That also means a reduction in the size of the staff needed to maintain high-end servers.
Nowadays, few organizations buy expensive on-premises hardware. Instead, their data warehouses run in the cloud on AWS Redshift, Google BigQuery, Microsoft Azure Synapse Analytics, or Snowflake. With cloud computing, workloads can scale almost infinitely and very quickly to meet any level or processing demand. Businesses are limited only by their budgets.
An analytics repository that scales means you no longer have to limit data warehouse workloads to analytics tasks. Need to run transformations on your data? You can do it in your data warehouse — which means you don’t need to perform transformations in a staging environment before loading the data.
Instead, you load the data straight from the source, faithfully replicating it to your data warehouse, and then transform it. ETL has become ELT — although a lot of people are so used to the old name that they still call it ETL.
We go into more detail in ETL vs. ELT: Choose the Right Approach for Data Integration.
Which is the best ETL tool for you?
Now that we have some context, we can start answering the question: Which ETL tool or ETL solution is best for you? The four most Important factors to consider include environment, architecture, automation, and reliability.
Environment
As we saw in our discussion about the history of ETL, data integration tools and data warehouses were traditionally housed on-premise. Many older, on-premise ETL tools are still around today, sometimes adapted to handle cloud data warehouse destinations.
More modern approaches leverage the power of the cloud. If your data warehouse runs on the cloud, you want a cloud-native data integration tool that was architected from the start for ELT.
Architecture
Speaking of ELT, another important consideration is the architectural difference between ETL and ELT. As we have previously discussed, ETL requires high upfront monetary and labor costs, as well as ongoing costs in the form of constant revision.
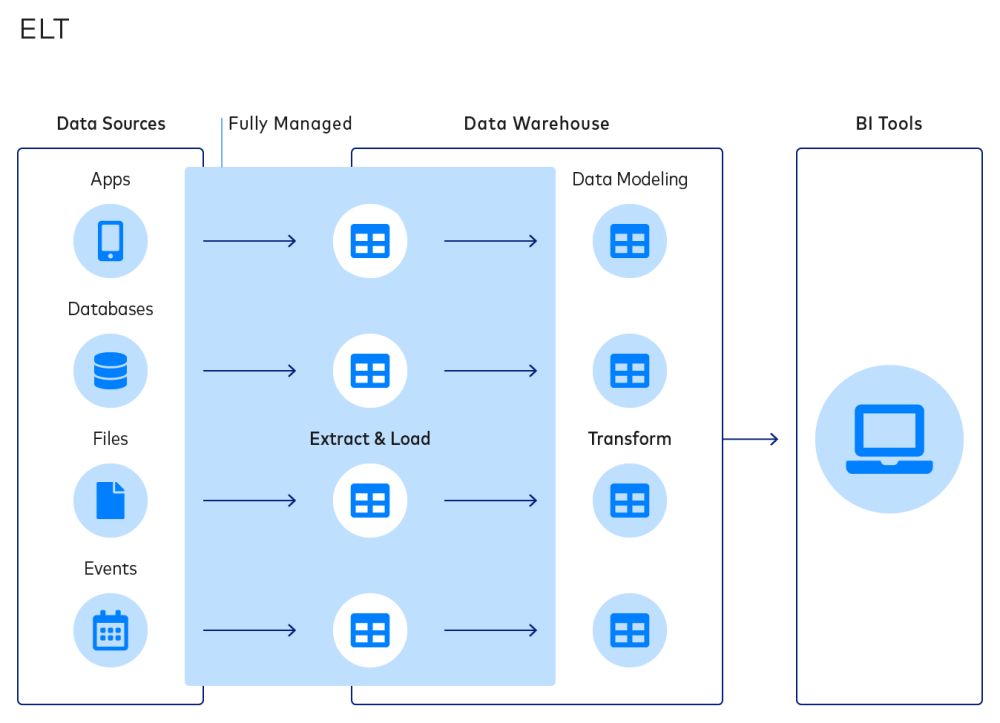
By contrast, ELT radically simplifies data integration by decoupling extraction and loading from transformations, making data modeling a more analyst-centric rather than engineering-centric activity.
Automation
Ultimately, the goal is to make things as simple as possible, which leads us right to automation. You want a tool that lets you specify a source and then copy data to a destination with as little human intervention as possible.
The tool should be able to read and understand the schema of the source data, know the constraints of the destination platform, and make any necessary adaptations to move the data from one to the other. Those adaptations might, for example, include de-nesting source records if the destination doesn’t support nested data structures.
All of that should be automatic. The point of an ETL tool is to avoid coding. The advantages of ELT and cloud computing are significantly diminished if you have to involve skilled DBAs or data engineers every time you replicate new data.
Reliability
Of course all this simplicity is of limited use if your data pipeline is unreliable. A reliable data pipeline has high uptime and delivers data with high fidelity.
One design consideration that enhances reliability is repeatability, or idempotence. The platform should be able to repeat any sync if it fails, without producing duplicate or conflicting data.
We all know that failure happens: Networks go down, storage devices fill up, natural disasters take whole data centers offline. Part of the reason you choose an ETL tool is so you don’t have to worry about how your data pipeline will recover from failure. Your provider should be able to route around problems and redo replications without incurring data duplication or (maybe worse) missing any data.
How Ritual replaced their brittle ETL pipeline with a modern data stack
With a modern data stack, Ritual saw a 95% reduction in data pipeline issues, a 75% reduction in query times, and a threefold increase in data team velocity.
LEARN MORE
ETL automation explained
Automation means expending a minimum of valuable engineering time, and deserves further discussion. The most essential things an automated data pipeline can offer are plug-and-play data connectors that require no effort to build or maintain. Automation also encompasses features like programmatic control, automated schema migration, and efficient incremental updates. Let’s look at each of those in turn.
Programmatic control
Besides automated data connectors, you might want fine control over setup particulars, such as field selection, replication type, and process orchestration. Fivetran provides that by offering a REST APIs for Standard and Enterprise accounts. They let you do things like create, edit, remove, and manage subsets of your connectors automatically, which can be far more efficient than managing them through a dashboard interface.
Learn more about how they work from our documentation, and see a practical use of the API in a blog post we wrote about building a connector status dashboard.
Automated schema migration
Changes to a source schema don’t automatically modify a corresponding destination schema in a data warehouse. That can mean you need to do twice as much work so you can keep your analytics up to date.
With Fivetran, we automatically, incrementally, and comprehensively propagate schema changes from source tables to your data warehouse. We wrote a blog post that explains how we implement automatic schema migration, but the key takeaway is: less work for you.
Slowly changing dimensions
Slowly changing dimensions (SCD) describes data in your data warehouse that changes pretty infrequently — customers’ names, for instance, or business addresses or medical billing codes. But this data does change from time to time, on an unpredictable basis. How can you efficiently capture those changes?
You could take and store a snapshot of every change, but your logs and your storage might quickly get out of hand.
Fivetran lets you track SCDs in Salesforce and a dozen other connectors on a per-table basis. When you enable History Mode, Fivetran adds a new timestamped row for every change made to a column. This allows you to look back at all your changes, including row deletions.
You can use your transaction history to do things like track changes to subscriptions over time, track the impact of your customer success team on upsells, or any time-based process.
Incremental update options
Copying data wholesale from a source wastes precious bandwidth and time, especially if most of the values haven’t changed since the last update.
One solution is change data capture (CDC), which we talk about in detail in a recent blog post. Many databases create changelogs that contain a history of updates, additions, and deletions. You can use the changelog to identify exactly which rows and columns to update in the data warehouse.
Pricing
Beyond the top factors of environment, architecture, automation, and reliability are a few other considerations, including security, compliance, and support for your organization’s data sources and destinations.
Finally, if an ETL provider has ticked all of those boxes, you have to consider pricing. ETL providers vary in how they charge for their services. Some are consumption-based. Others factor in things like the number of integrations used. Some put their ETL tool prices right on their websites. Others force you to speak with a sales rep to get a straight answer. Pricing models may be simple or complicated.
When you’ve done your due diligence, you’ll find Fivetran excels at all the key factors we’ve covered, and we have several consumption-based pricing plans that suit a range of businesses, from startups to the enterprise. Take a free trial, or talk to our sales team.







