Hybrid Deployment with Kubernetes Setup Guide
Follow our setup guide to set up the Hybrid Deployment model with Kubernetes.
Prerequisites
To use Hybrid Deployment with Kubernetes, ensure your environment meets the requirements outlined in the following sections.
Software requirements
- Kubernetes v1.29.x or above.
- Helm CLI (v3.16.1 or above) to deploy the Hybrid Deployment Agent Helm chart.
- Any on-premises Kubernetes service or one of the following cloud-based Kubernetes services:
- We do not support AWS Fargate for Hybrid Deployment.
- If you use AKS, we recommend the Standard tier instead of Automatic, as it provides greater flexibility for Hybrid Deployment configuration.
- If you use an auto-scaling cluster (for example, with Karpenter), install the Hybrid Deployment Helm chart v0.24.0 or above. Depending on your setup, Karpenter may require additional annotations. For more information, see our Troubleshooting documentation.
System requirements
CPU architecture requirements
A system with a native x86_64 (AMD64) CPU architecture.
Hybrid Deployment does not support the following:
- ARM64 architectures, including Apple Silicon
- ARM-based systems, including configurations that use x86_64 emulation or translation layers
Compute, memory, and storage requirements
The compute (CPU), memory (RAM), and storage requirements for your environment depend on the number of concurrent pipeline processes and the volume of data to sync. Before reviewing the table below, see our Sizing guidelines for detailed guidance on how to estimate resources based on connection type and deployment scale.
The following table provides the minimum CPU and RAM requirements for the host, along with estimated storage requirements, based on the number of concurrent connections running on the same host:
| Deployment Size | Number of Connections | vCPUs (x86-64) | RAM | Estimated Disk Space |
|---|---|---|---|---|
| Small | 1-2 | 8 | 32 GB | More than 50 GB |
| Medium | 2-6 | 8-16 | 32 GB | More than 300 GB |
| Large | 6-12 | 16-24 | 64 GB | More than 500 GB |
If you want to use more than 12 connections, we recommend distributing the load across multiple Medium or Large deployments.
- The default memory allocation for the pipeline processing jobs is 4 GB, where the Java heap size uses 70% of the total allocated memory. However, you can increase the memory allocation based on your requirements. For connections with complex schemas and large datasets, we recommend allocating 8 GB. You can increase the memory allocation by modifying the values of the agent configuration parameters.
- The disk space required depends on your data volume. In Kubernetes, the nodes share the available disk space.
Kubernetes requirements
A Persistent Volume Claim (PVC) with ReadWriteMany access mode. To create a PVC, you need a Storage Class and Persistent Volume with appropriate permissions. For more information, see your cloud service providers' documentation. For more information about checking the status of your PVC, see our Troubleshooting documentation.
(Optional) A dedicated namespace for your deployment. If you do not have a dedicated namespace, we will use the
defaultnamespace.You can only run one agent per namespace.
Network requirements
In addition to connecting to your source and destination, Hybrid Deployment requires outbound TCP connections over port 443 to the following Fivetran services and supporting infrastructure:
- mTLS connection to the Fivetran Orchestration Service
- Host:
ldp.orchestrator.fivetran.com - IP addresses:
35.188.225.82,136.107.81.248/29, and34.143.64.0/29
- Host:
- HTTPS with a secure token to the Fivetran Public API
- Host:
api.fivetran.com - IP addresses:
35.236.237.87,136.107.81.248/29, and34.143.64.0/29
- Host:
- Fivetran Orchestration Gateway
- Host:
hdt.orchestrator.fivetran.com - IP addresses:
136.107.81.248/29and34.143.64.0/29
- Host:
- Google Artifact Registry
- Host:
us-docker.pkg.dev - To determine the applicable IP range, run
nslookup us-docker.pkg.devfrom your Hybrid Deployment machine and use the returned IP address to identify the corresponding IP range through ICANN
- Host:
- Fivetran Platform Connector logs
- Host:
storage.googleapis.com/fivetran-metrics-log-sr
- Host:
- Unless specified otherwise, all HTTPS-based outbound connections use port
443. - If your firewall supports domain-based allowlisting, Fivetran recommends allowing hostnames instead of IP ranges wherever possible.
Setup instructions
Create agent
Log in to your Fivetran account.
Go to the Destinations page and click Add destination.
Select your destination type.
Enter a Destination name of your choice.
Click Add.
In the destination setup form, choose Hybrid Deployment as your deployment model.
Click Select Hybrid Deployment Agent.
Click Create new agent.
Read the Fivetran On-Prem Software License Addendum, and select the I have read and agree to the terms of the License Addendum and the Software Specific Requirements checkbox.
Click Next.
Choose Kubernetes as the environment for your deployment.
Click Next.
Enter an Agent name.
Click Generate agent token to generate the token and installation command for your agent.
Each Hybrid Deployment Agent has a unique token and installation command.
Make a note of the agent token. You will need it to install and start the agent.
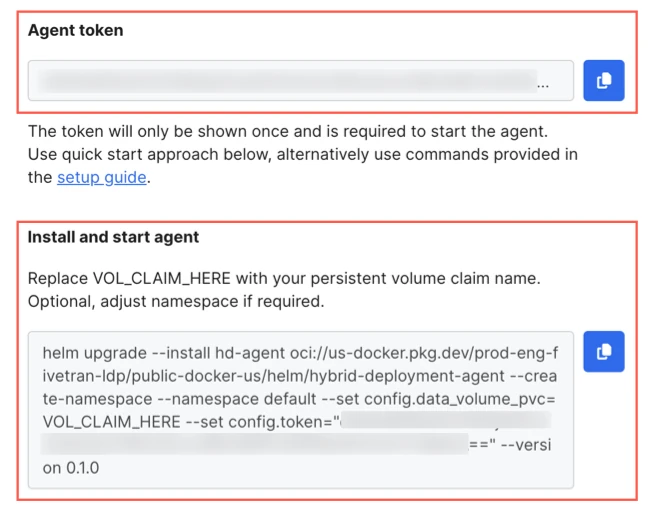
Copy the installation command and paste it in a separate file where you can edit it, and then make the following changes to the command:
- (Optional) Replace the default deployment name (
hd-agent) with a name of your choice. - (Optional) Replace the default deployment namespace (
default) with the namespace you want to use for your agent. - Set the value of the
data_volume_pvcparameter to your Persistent Volume Claim name. By default, this parameter contains a dummy value (VOL_CLAIM_HERE). - Update the Helm chart version by replacing the current value of
versionwith a version that meets your requirements. For more information about the latest version, see the latest releases.
- (Optional) Replace the default deployment name (
Make a note of the updated command. You will need it to install and start the agent.
Go back to the Fivetran dashboard and click Save.
You must install and start the agent before completing the destination setup.
Install and start agent
Log in to the environment where kubectl and Helm are configured to connect to your Kubernetes cluster.
You can test the connectivity to your cluster using
kubectl cluster-infoandhelm list --all-namespaces.Run the agent installation command to install the Helm chart and start the agent.
You must run the command only after you update it with your specifications, not the default command that you copied from the Fivetran dashboard.
Example:
$ helm upgrade --install hd-agent \ oci://us-docker.pkg.dev/prod-eng-fivetran-ldp/public-docker-us/helm/hybrid-deployment-agent \ --create-namespace \ --namespace default \ --set config.data_volume_pvc=VOL_CLAIM_HERE \ --set config.token="YOUR_TOKEN_HERE" \ --set config.namespace=default \ --version 0.24.0The installation command does the following:
- Creates a ConfigMap with the agent configurations
- Creates the necessary service account, role, and role bindings
- Deploys the Hybrid Deployment Agent Pod, which pulls the latest agent container image
Expand to view commonly used agent configuration parameters for the installation command
Agent configuration parameters define the characteristics of your Hybrid Deployment Agent and allow you to customize it for your environment beyond the default settings. The agent supports a comprehensive set of parameters. The following are the most commonly used parameters that you can configure during installation:
donkey_container_cpu_request: Specifies the baseline CPU resources reserved for all pipeline processing jobs in the cluster. The default value is
2.donkey_container_memory_request: Specifies the minimum memory allocated to all pipeline processing jobs in the cluster. The default value is
4Gi.donkey_container_memory_limit: Specifies the maximum memory limit for all pipeline processing jobs in the cluster. The default value is
4Gi.
Example: The following command shows how to configure these parameters during agent installation:
$ helm upgrade --install hd-agent \ oci://us-docker.pkg.dev/prod-eng-fivetran-ldp/public-docker-us/helm/hybrid-deployment-agent \ --create-namespace \ --namespace default \ --set config.data_volume_pvc=VOL_CLAIM_HERE \ --set config.token="YOUR_TOKEN_HERE" \ --set config.namespace=default \ --set config.donkey_container_memory_request="16Gi" \ --set config.donkey_container_memory_limit="8Gi" \ --version 0.24.0The parameters described above apply globally to all pipeline processing jobs in the cluster. To apply these settings to a specific connection, append the connection ID to the parameter name (for example,
donkey_container_cpu_request_<connection_id>).Verify whether the agent is up and running.
Run the following commands to verify the agent status:
kubectl get deployments -n <namespace> kubectl get pods -n <namespace>Run either of the following commands to verify the agent log:
kubectl logs -l app.kubernetes.io/name=<deployment_name> -n <namespace>or
kubectl logs pod/<pod_name> --follow -n <namespace>
- Once the agent is deployed, you can go to the Fivetran dashboard and view the agent details and status in Account Settings > General > Hybrid Deployment Agents.
- You can use
helm list -ato view the list of all Helm charts installed in your environment andhelm uninstall <deployment_name> --namespace <namespace>to uninstall a Helm chart.