



At Fivetran, we use Looker as our BI and analytics platform. It enables the analytics team to ensure that internally, Fivetran is a data-driven company and that users have easy access to the data they need to turn insights into actions. As the analytics team grows and our company’s usage of Looker expands and evolves, we adopt tools and methodologies to help us easily manage our data space. One such tool is the Looker API.
The Looker API is a great asset for managing your Looker environment. At Fivetran, it’s critical to helping us easily understand the usage of fields (dimensions, measures) and filter parameters across looks and dashboards. It can also come in handy for finding and replacing fields and filters on a larger scale.
In this blog we’re going to cover how to get started with the Looker API using Python, the important end points and objects one should be familiar with, and a few use cases that warrant the use of the API. This blog is targeted towards intermediate to advanced developers / users of Looker. Familiarity with Python is also required. The Python code referenced in this blog can be found here.
Looker API requests
Below is an example of a Looker API GET request to the dashboards endpoint that returns all dashboards in your Looker environment.
import requests HEADERS = { 'Authorization': 'token 123456789abcd' } URL = 'https://[yourcompanyname].looker.com:19999/api/3.1/' def get_all_dashboards(): dashboards = requests.get(URL + 'dashboards', headers=HEADERS) return dashboards.json()
Two things to note:
- The API URL for your company’s Looker environment is required. In most cases it should have the format https://[yourcompanyname].looker.com:19999/api/3.1/ with your company’s name as the domain of the URL. The latest version of the Looker API is 3.1.
- There is an OAuth 2.0 access token that needs to be passed in the request authorization header, in order to authenticate. To obtain this access token, you need to first obtain API credentials (Client Id and Client Secret).
Getting API credentials
API credentials are tied to an individual Looker user and can be found in the Admin section of your Looker instance.
- Navigate to the Looker user settings (Admin > Users > Find user in list> Select ‘Edit’)
- In the user settings page, click on ‘Edit Keys’
- If you don’t already have API Credentials, select the option to generate a New API3 Key. A Client ID and Client Secret key will be generated and tied to the Looker user.
An access token can now be obtained by passing the client_id and client_secret to the login endpoint. These tokens expire in an hour.
def generate_auth_token(): """Generates an access token for the Looker API that can be passed in the required authorization header. These tokens expire in an hour""" data = { 'client_id': '123456789abcd', #replace me with client id 'client_secret': '123456789abcd' #replace me with client secret } auth_token = requests.post('https://[yourcompanyname].looker.com:19999/api/3.1/login', data=data) return auth_token.json().get('access_token') HEADERS = { 'Authorization': 'token {}'.format(generate_auth_token()), }
Looker objects
Now that we’ve covered the basics of Looker API requests, we will cover some key endpoints and the objects returned by those endpoints. These objects, which you must familiarize yourself with in order to understand the use cases below, include:
- queries
- looks
- dashboards
- dashboard elements
- merge_queries
Query object
When a user navigates to an Explore and starts building their visual by selecting fields and adding filters, Looker begins to automatically generate a query. In fact if you look at the URL as you explore your data, you will see that the Explore URL has been appended with a qid parameter, e.g. https://[yourcompanyname].looker.com/explore/[yourdatamodel]/[yourexplore]?qid=aogBgL6o3cKK1jN3RoZl5s and that the value of the parameter changes with each modification. This is because Looker queries are immutable and with every selection change, the query parameters are modified and a new query is generated if it does not already exist.
In this simple example, you can see how the different parts of an Explore-generated query are mapped to the different fields in the query object returned by the API.
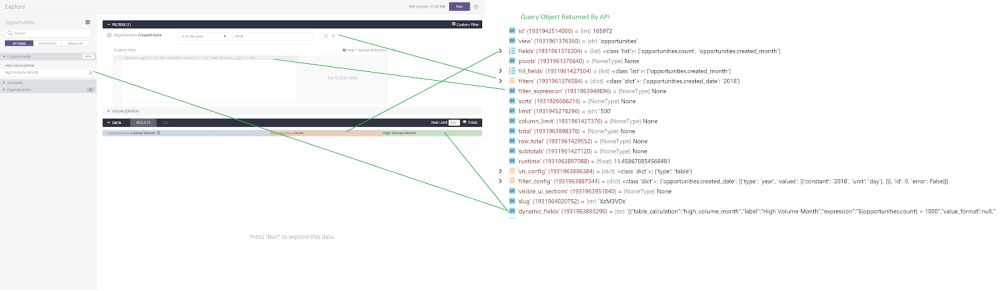
Fields, filters, custom filters, table calculations, custom dimensions, even visualization configurations are all stored in the query object.
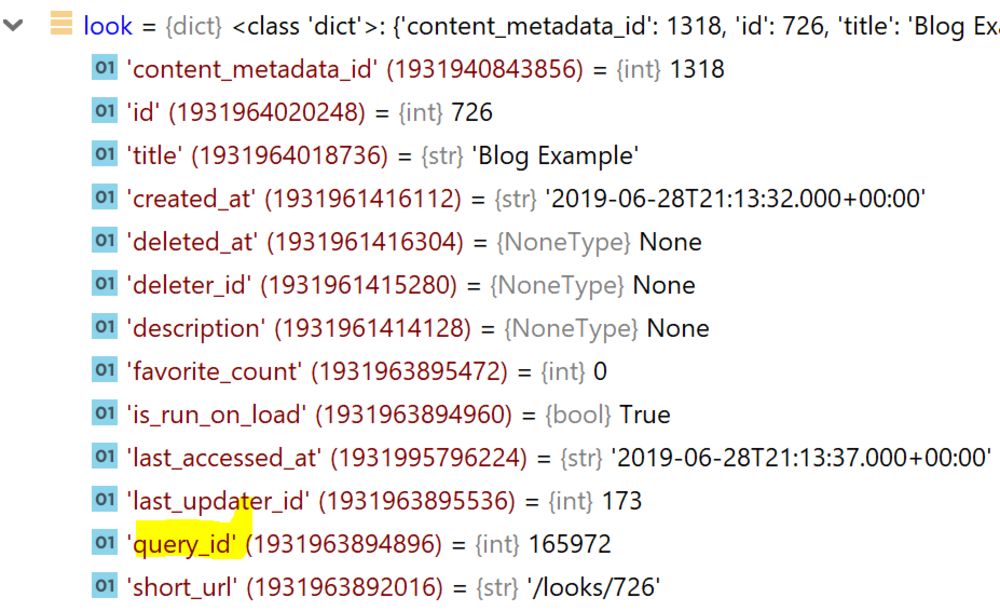
Look object
Upon saving your query to a Look, the query id will be referenced in the query_id field of the Look. As discussed in the previous section, the information needed to actually create the visualization is in the query. In fact, you can assign a different query id to a Look via the API and have a completely new visual. However, the metadata about the Look, like the title and the id, won’t have changed.
Dashboards and dashboard element objects
Just as a query is associated with a Look when you save your Explore query as a Look, when you save your query to a dashboard, the query-based dashboard tile will have the query id in the query_id field.
Please note that for the purpose of this blog, when we’re talking about dashboards, we’re referring to user-defined dashboards as opposed to LookML Dashboards.
When you get a dashboard object via the API, two items you want to pay attention to are the dashboard_filters and dashboard_elements.
Dashboard filters
Dashboard filters are relatively straight forward. Observe the following list of dashboard filters. Each filter entry contains information such as the name of the Explore, the dimension, and the default filter value.
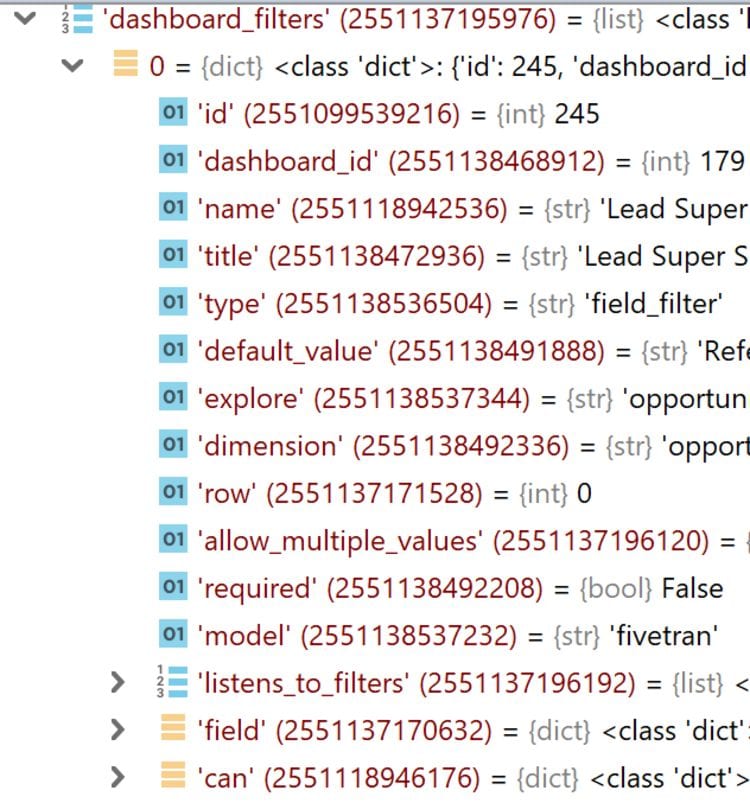
In terms of which dashboard elements are applying said filter, that information is stored in the dashboard element itself.
Dashboard elements
I like to categorize dashboard elements under 3 types:
- Looks
- Query Tiles**
- Merged Result Tiles
This Looker discourse article explains the difference between Look-linked tiles and query tiles.
When looking at a dashboard element object, you can identify the three types depending on whether a value is specified in the following fields: look_id, query_id, and merge_result_id. Tiles will have a query_id directly specified. If it’s a Look, the look_id field will be specified; if the tile is a result of saved merge results, then merge_result_id will be specified.
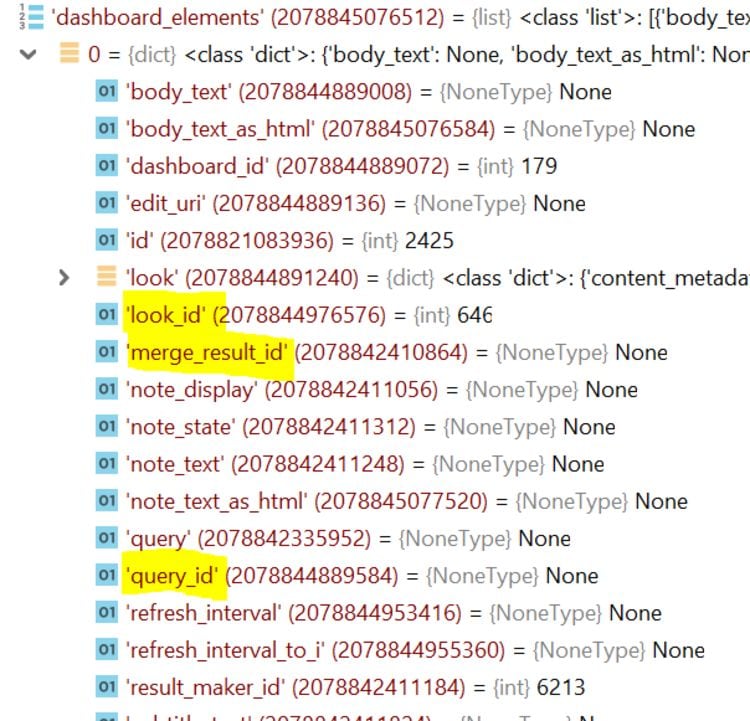
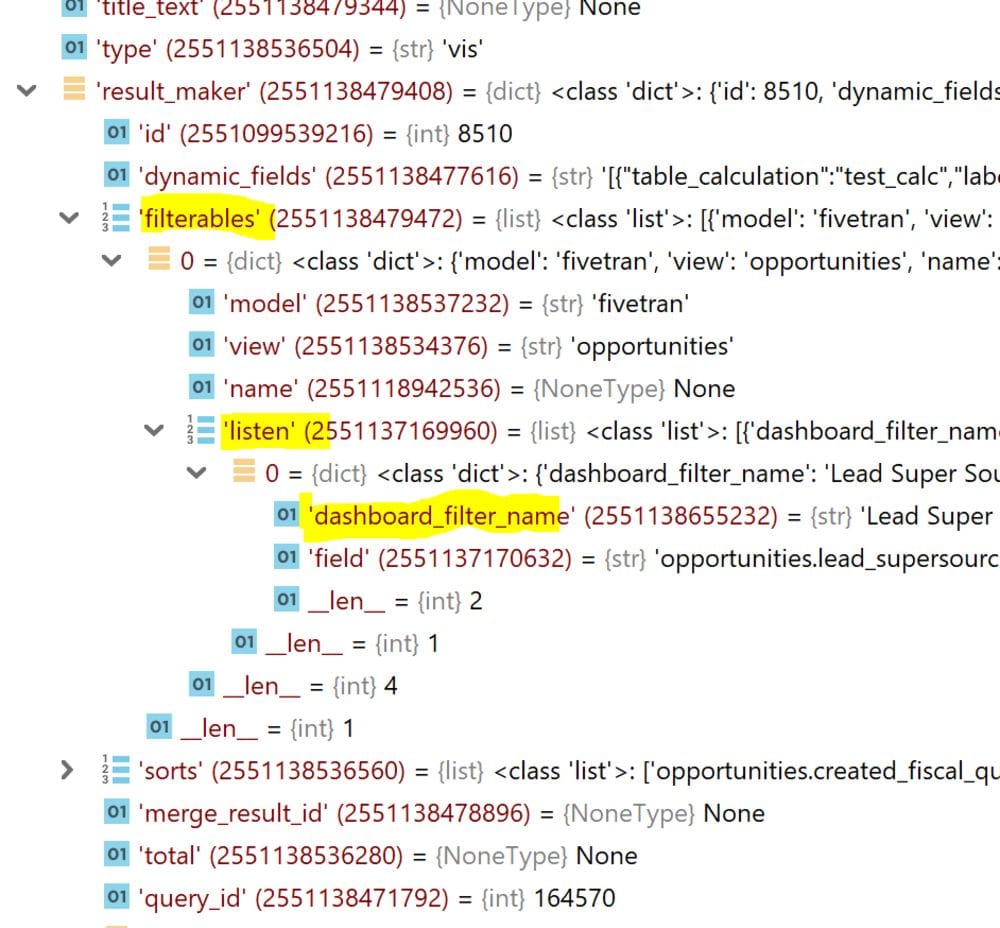
Another important object within the the dashboard element object is the result_maker. I like to think of it as sitting on top of your query or merge query. It pulls in your query, and certain settings in your query, e.g. vis_config, but also has additional information that affects the result output of the dashboard element that isn’t in the query itself, most notably inherited dashboard filters.
Merged query object
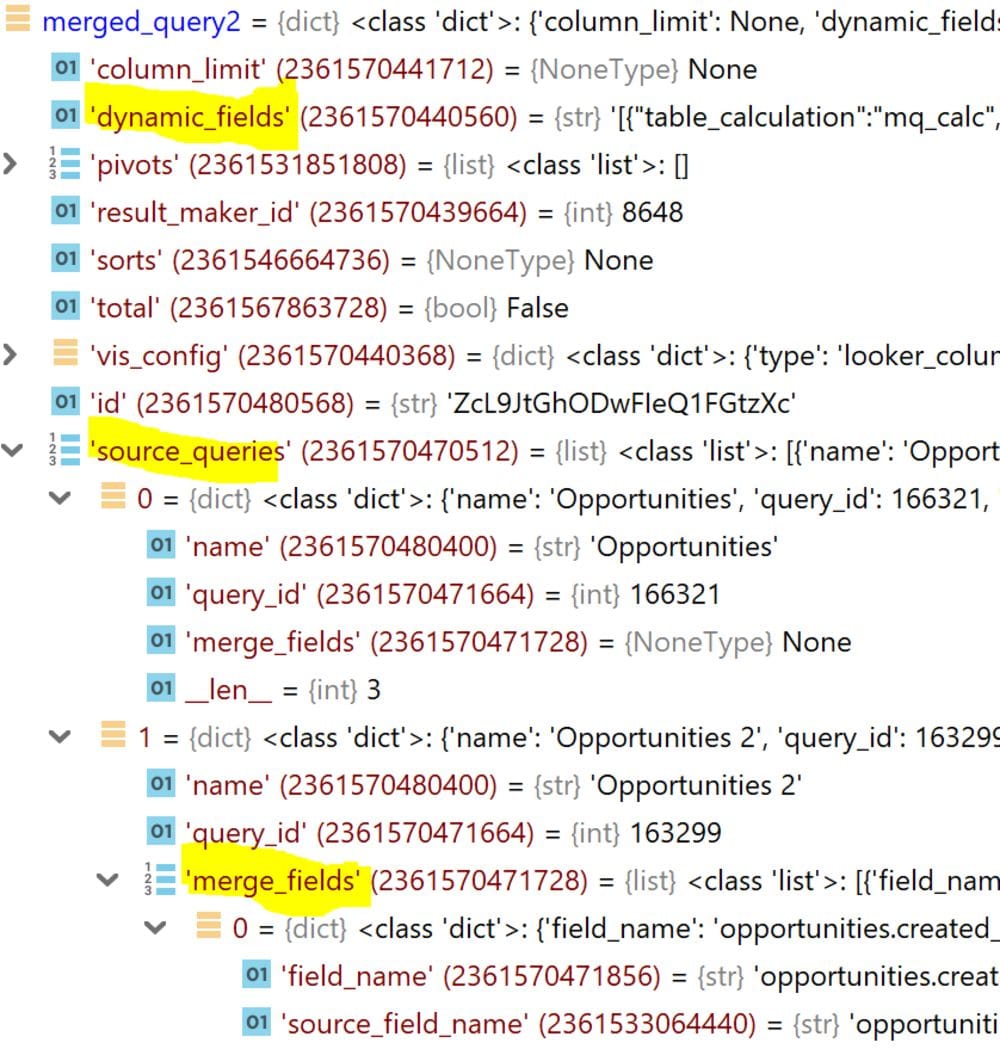
A merged query object is returned when you pass the merge_result_id to the merge query endpoint. As with the query object, the merged query object is immutable. The merge result object will contain:
- Query ids of the source queries. This will include the primary query and the secondary queries that are merged with the primary query.
- For the secondary source queries, the merge fields list will contain the list of join fields from the primary and secondary source queries for each merge rule.
- The table calculations in the merge query, returned in the dynamic_fields field.
Now let’s review some use cases.
Finding fields and filters in looks and dashboards
We once received a request to modify a value in a lookup table. It’s a simple enough request, but we had fields in a couple of explores built off this lookup table, meaning that before we could change this lookup value, we needed to check if it was being used in any filters, so that the filters could be updated after the change was made.
Looker fields and filters can be referenced in multiple locations, including dashboards (dashboard filters), queries, merge queries, and scheduled plans. If you’re checking the usage of a specific field or filter, these are the locations you should check:
- query fields
- query filters
- query customer filters (query filter_expression)
- query table calculations (query dynamic_field, also includes custom measures and dimensions if you use them)
- merge query merge fields (source_field_name and field_name)
- merge query table calculations (dynamic_fields)
- dashboard filters (also referenced in result maker filterables)
- scheduled plan filters**
**Fields and filters are also referenced in schedule plan filters, however for dashboards, the schedule plan filters will reference the filter name.
The accompanying code for these steps can be found here and the relevant code is hyperlinked in each step.
Step 1. Get all looks and dashboards
The first step is to get all Looks and Dashboards from Looker.
Step 2. Parse looks
Each Look in the list returned will reference the query_id behind the look. A request to the query endpoint, passing the query_id, will return the query object behind the Look.
Step 3. Parse dashboards
The list of dashboards returned when you get all dashboards contains higher level information regarding the dashboard, e.g. the dashboard id. Dashboard objects are, however, more complex. The dashboard object is comprised of the dashboard itself and has certain features like dashboard filters. In addition, dashboard objects also have child objects (dashboard elements) which can be Looks, tiles, or merge query tiles. In order to get the complete dashboard object, you would need to pass the dashboard id to the dashboards API endpoint.
For dashboard tiles, you would need to get the query as you would for looks. For dashboard merge query tiles, one would need to get the merge query and parse it for the source queries behind the merge query.
Step 4. Check queries and objects for usage
With the looks and dashboards parsed, you need to check the objects and queries in order to see if specified fields or filters are being referenced. The find_matching_text* )https://github.com/fivetran/analyst-recipes/blob/master/looker_api/looker_api_helpers.py) check to see if text exists in query fields, query filter fields, query filter values, merge query fields, dashboard filters etc. In the case of fields and filters, text lookup is fairly straightforward as fields are lists, and filters are dictionaries with the field and filter values in separate keys. However when dealing with expressions, as one would use in a custom filter or table calculation e.g. ‘account.status’ = “Active” you have both fields and filter values in the same text and it’s something you need to account for.
The majority of the usage of fields and filters will be in queries. For queries, if you then want to update or replace these fields and filters and you’re making these replacements on a larger scale, this can be done via the API.
Replacing fields and filters in queries
There are going to be cases where you need to replace or update a field or filter value being used in your queries. We recently had to do just that when we migrated from using calendar date quarters to fiscal date quarters. We had to find and replace all instances where quarter date fields were being used. Not only that, the usage of quarters in filters had to be adjusted to fiscal quarters, e.g. in the past 2 quarters needed to be adjusted to in the past 2 fiscal quarters. Using the API, we saw there were over 200 usages of date quarter dimensions and quarter filter values in look and tile queries.
If you have a couple of fields to replace, you could use the Find and Replace tool in the Content Validator. It does an excellent job of finding and replacing fields across the board, with the exception of scheduled plans. Keep in mind that when you do use the find and replace tool, scheduled plans built off Looks need to have the filters reconfigured.
Unfortunately, the find-and-replace endpoint is currently not available via Looker’s public API and if you’re dealing with replacing multiple fields, the process can be tedious using the web UI. Secondly, find-and-replace only applies to fields and not filter values. What you can instead do using the Looker API is to create a new query with the fields and filters updated and assign this new query id back to the look or tile. Let’s review the steps. The accompanying code for these steps can be found here and the relevant code is hyperlinked in each step.
Please note: the following workflow does not apply to merge-query tiles.
Step 1. Get queries that need to be updated
The first step would be to get the list of queries that need to be updated. The “Finding Fields and Filters In Looks and Dashboards” section covers finding which look / tile queries are using a field or filter in their query.
Step 2. Create a new updated query
As a reminder, queries are immutable and you cannot edit the existing query, so the easiest thing would be to copy the old query, make the edits, create a new query and assign the new query id to the Look or tile. One of the helpful things about using the API is if you realize that the new modified query has a mistake, you can simply reassign the old query to reverse the changes.
Things to keep in mind when creating a new query from an existing query:
- It’s important to note that the query object is fairly complex. Dimensions and measures can be referenced in multiple locations, including fields, filters, table calculations, custom filters and visualization configurations. When editing the query object, you could go through each key-value pair and make the updates. What I’ve found works best – but has to be done with caution and validated– is to convert the query dictionary into a JSON string, perform a string replacement (e.g. accoun.t.created_date_quarter > accounts.created_date_fiscal_quarter) and parse it back.
- When creating a new query, any existing read-only fields need to be removed.
- The filterconfig field also needs to be removed as per the documentation: ‘When running a query via the Looker UI, this parameter takes precedence over "filters". When creating a query or modifying an existing query, "filterconfig" should be set to null. Setting it to any other value could cause unexpected filtering behavior.’
def update_query(query, old_text, new_text): """Replaces text in a query and returns an updated query dictionary""" # In order to create a new query, read_only fields need to be removed # Filter config also needs to be removed otherwise it will override the filter options in the ui read_only_fields = ["id", "client_id", "slug", "share_url", "url", "expanded_share_url", "has_table_calculations", "can", "filter_config"] for field in read_only_fields: if field in query: query.pop(field) query_dumped = json.dumps(query) query_updated = query_dumped.replace(old_text, new_text) new_query = json.loads(query_updated) return new_query
Step 3. Assign the new query to the look/tile
Once a query has been created, a patch request (below) can be sent to the looks and dashboard_elements endpoints with a mapping of the new query id to the ‘query_id’ field in the data parameter. If you need to reverse this change, you can simply send another update request with the old query_id.
def update_look_dashboard_element_query_id(element_type, element_id, new_query_id): """Replaces the query_id value for a look or dashboard element with the new query id. Args: element_type: looks or dashboard_elements Returns the query id of the element it has updated. """ headers = HEADERS headers['content-type'] = 'application/json' try: update_request = requests.patch('{}{}/{}'.format(URL, element_type, element_id), headers=headers, data=json.dumps({'query_id': new_query_id})) #verify updated query_id get_updated_dashboard_element = requests.get('{}{}/{}'.format(URL, element_type, element_id), headers=headers) updated_element = get_updated_dashboard_element.json() updated_query_id = updated_element.get("query_id") if str(updated_query_id) != str(new_query_id): raise Exception("Failed to update query id {} with new query id {}".format(updated_query_id, new_query_id)) return updated_query_id except Exception as e: print("Exception with update query id method for {} {} and new query id {}".format(element_type, element_id, new_query_id)) print(e)
This blog covered just a few API use cases. There’s plenty more you can do with the Looker API, but hopefully this will help you get started.
Learn more about what Looker and Fivetran can do for your data team with a free demo.






