



In recent years, a number of data professionals have independently arrived at a hierarchical model of data-related business needs. Like Maslow’s famous hierarchy of psychological and emotional well-being, the needs are organized from the most basic to the most rarefied, with higher needs essentially dependent on lower ones.

While there are several versions of this model, sometimes also referred to as the data science hierarchy of needs, they all feature a progression from the collection of raw data at the bottom to artificial intelligence and machine learning at the top. The activities in the upper levels of the hierarchy are difficult or impossible without a solid foundation in data collection and management. Yet many organizations do not explicitly understand this progression and prematurely hire data professionals before they have established a strong foundation of tools, technologies and processes.
As a result, highly qualified analysts, data engineers and data scientists who are eager to test models or delve into machine learning often find themselves collecting and managing data instead. It is well-known that 80 percent of the average data scientist’s time is consumed by data wrangling. Companies spend, on average, $520,000 every year paying data engineers to manually build and maintain data pipelines, according to Wakefield Research. More importantly, 72 percent of enterprises find that building and maintaining data pipelines displaces high-value analytics activities such as creating new data models, promoting data literacy, growing the organization’s data infrastructure and building internal tools.
Read about the data hierarchy of needs, and more, in our ultimate guide to data integration
Read it!Level 1: Data extraction and loading
The most foundational level of the hierarchy is the ability to extract, load and transform data. This is accomplished with the help of a modern data stack, a suite of tools and technologies that consists of:
- Data pipeline – a data integration tool used to connect data sources with a destination
- Destination – typically a data warehouse, the destination serves as a central repository of record or “single source of truth” from which analysts can build data models.
- Transformation tool – used to construct data models from raw data, ideally using SQL within the data warehouse
- Business intelligence platform – essential for making data legible to end users in the form of data products such as visualizations, reports and dashboards
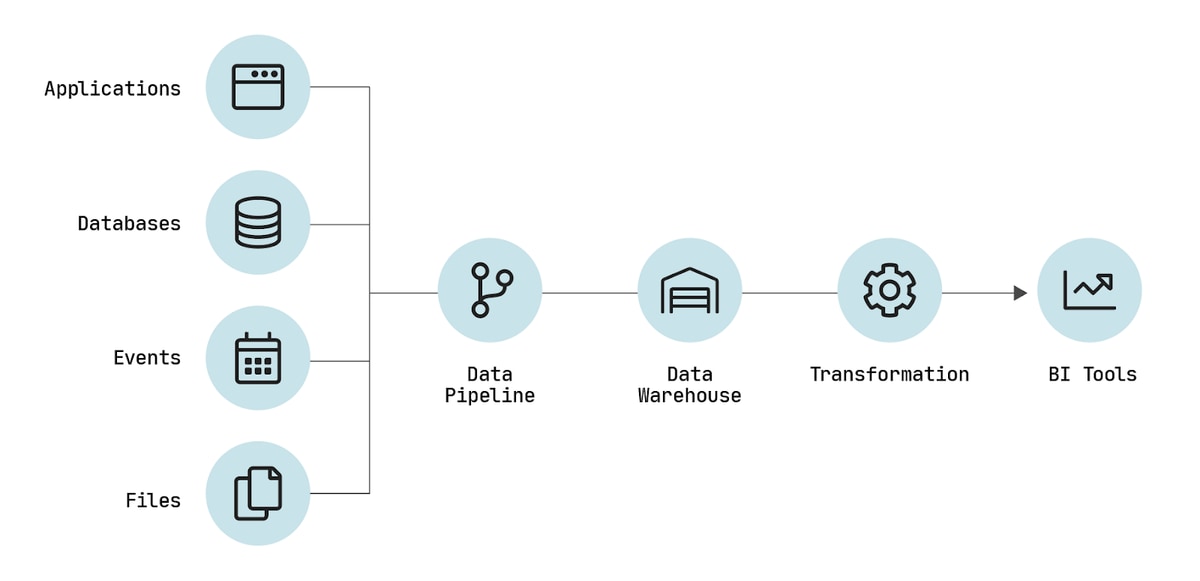
As you build a modern data stack, make sure the different elements are all compatible with each other, cloud-based and easy to use.
Level 2: Data modeling and transformation
Once your modern data stack is in place, your analysts will need to transform raw data into data models that can directly feed into visualizations, reports and dashboards. This requires a solid understanding of what the data actually stands for and a plan for ensuring data quality and integrity, i.e. data governance.
At this stage, your data team may grow as you continue to add more data sources and your users’ data modeling needs become more complicated. A good approach to organizing a data team as it grows is to use a hub-and-spoke model. Maintain a core analytics team that reports directly to leadership and produces data products for users across the organization, but also assign some analysts to specific functional teams so that they can develop expertise in those functional areas and better serve your data users.
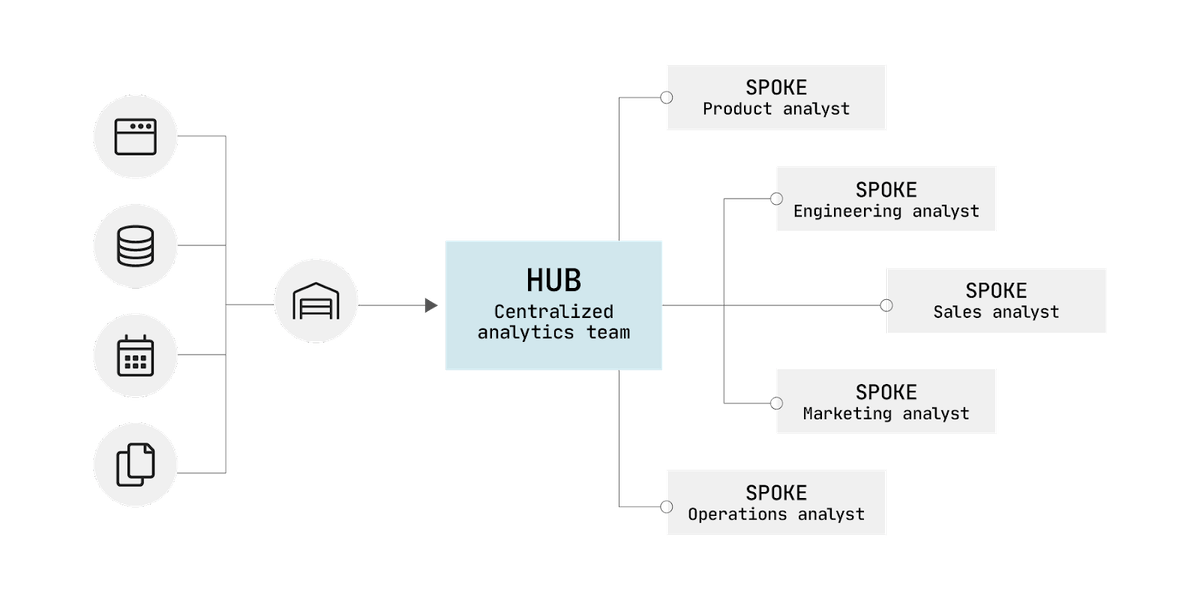
Level 3: Visualization and decision support
Treat visualizations, reports and dashboards as products in their own right. Analytics projects benefit from product thinking and practices such as agile methodology. It is usually a good idea to begin with low effort, high impact metrics such as those concerning sales, marketing, product and revenue analytics.
Decision support is the use of data to influence behaviors and decisions. With the proliferation of data products, you will also need to promote data literacy throughout your organization in order to leverage decision support. At a minimum, make sure everyone from the C-suite to the most junior individual contributor can interpret and intelligently react to the visualizations, reports and dashboards produced by analysts.
Level 4: Business process automation
As your company depends more and more on data-driven decision support, you will also need to close the loop by feeding analytics data directly back into operational systems using processes such as reverse ETL. A simple example is copying sales analytics data back into payroll to automatically award commissions and bonuses. Another is to embed dashboards and visualizations into operational systems to give employees real-time insight into the effects of their activities.
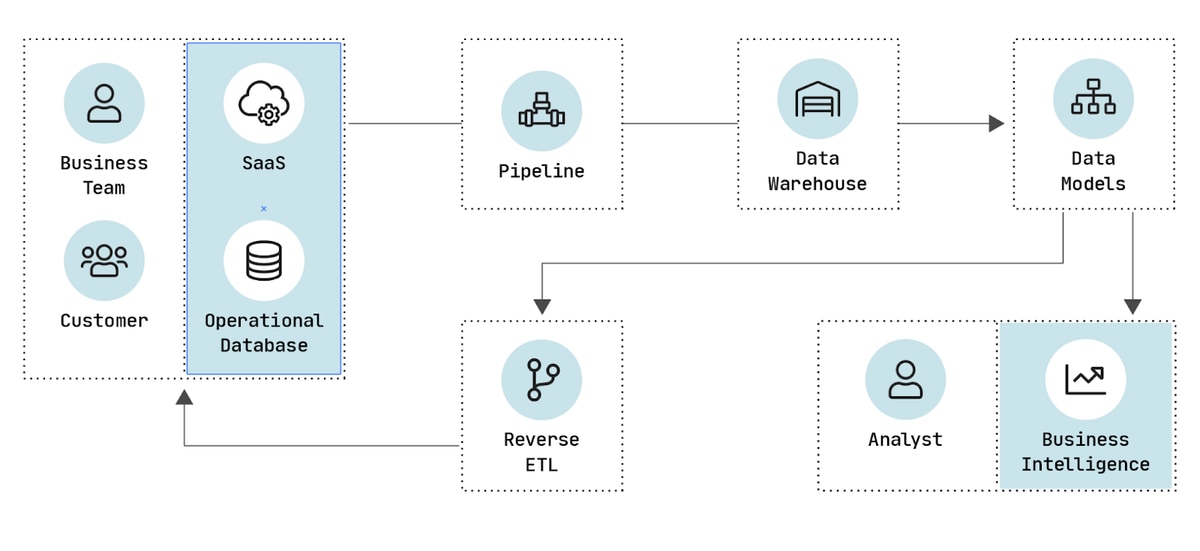
To support increased operational use of data, you will need to build a robust data architecture. This means automating as many processes as possible and exercising programmatic control over your entire data stack. You are likely to need data engineers to support this effort.
Level 5: AI/ML
Broadly speaking artificial intelligence and machine learning can be divided into the following kinds of predictive modeling:
- Supervised learning – Data scientists use a training set of known outputs and inputs to produce a predictive model. A simple example is drawing a regression line through some points on a graph. The equation that describes the regression line can be used to predict future values based on known inputs.
- Unsupervised learning – Data scientists uncover patterns within a data set using a pattern recognition algorithm without any previously known outputs and inputs. A common example is dividing data points into clusters based on similar characteristics.
- Reinforcement learning – An artificial agent gradually improves its ability to act intelligently through trial and error. Self-driving vehicles are a well-known example (don’t worry, the initial training is conducted in simulations, not real traffic), as are game-playing bots such as AlphaStar and AlphaGo.
Artificial intelligence and machine learning are the purviews of data scientists, who combine heavy skills in applied statistics with a working knowledge of engineering. A successful machine learning implementation depends on the capabilities previously described – a modern data stack, mature analytics operations and robust infrastructure to support the efforts of your data scientists.
Build automated data pipelines with Fivetran
Fivetran is an automated ELT pipeline, providing your organization with the tools and technologies to rapidly build and scale a foundation for analytics pursuits. With the help of data connectors for over 180 common data sources, your data team can effortlessly fulfill the first level of needs, extracting and loading data. With the help of Fivetran data models, you can also surmount the second level, modeling and transforming data into forms suitable for reports and dashboards. With Fivetran, you can begin to systematically modernize your analytics. Let your data team up make sense of data and use it to drive innovation.






