


The following blog post is the tenth chapter in a primer series by Michael Kaminsky on databases. You can read Chapter Nine if you missed the third lesson about distributed databases, or watch the complete series.
Query planning and optimization is a critically important topic for working with databases. A query, normally written in SQL, is how we tell the database what we want. Then, the database is in charge of figuring out how to get that data out of whatever format it’s stored on disk. Sometimes, that might involve lots of intermediate computations in addition to just finding the right data.
The query plan is what the database uses to actually go and execute the query that we submitted. It turns out that we can actually review this plan for any query to see what the database is doing under the hood.
A Review – SQL
SQL stands for “structured query language” and there are two really key things to know about it.
- SQL is not a single language, but actually a standard that is implemented differently by different databases. So the SQL you use in your postgreSQL database probably won’t work in your BigQuery database. SQL syntax is generally similar across databases, but you can’t necessarily seamlessly migrate SQL code from one database to another.
- SQL is a declarative language which means that you describe the output you want to see rather than giving the computer direct instructions for how to generate that output. We’ll talk about this in more detail in a second.
As a reminder, here’s what SQL looks like:
CREATE TABLE users AS SELECT id , name , state FROM other_table WHERE attribute IS TRUE;
We’ve got a traditional query that starts with SELECT along with a WHERE clause for filtering and a CREATE TABLE command from the data description language (DDL).
Declarative Programming Languages
In a declarative programming language, like SQL, what we’re doing is describing the data we want the database to return to us, and the database itself will figure out how to execute the request computationally. That is, we don’t concern ourselves with the how, just with the what. This can be confusing for software engineers who come to SQL from an imperative programming language (like Python, Java, or C, or many others).
Only thinking about the what, not the how, makes working with SQL very convenient but can also make working with SQL feel very opaque. If a query is taking a really long time to complete, it can be difficult to determine what might be going wrong since the code itself doesn’t give many hints.
The Query Lifecycle
So let’s take a look at what happens when you are querying a database.

The first thing you do after writing the query and hitting “send” so that it goes to the database, is that the database is going to examine the query and parse it, and then use what it knows about the database to generate a query plan. The query plan is the series of steps that the database is going to follow in order to be able to return your results to you. The database will generate a plan for all of the steps in the query before it starts executing any of them.
Once the database has the plan generated, it will start executing by following all of the steps in the plan. When the steps are completed, the results are finally returned to the user.
The Query Planner
The part of the database that creates the plan is called “The Query Planner.” Query planners in modern databases are very complex and sophisticated. Unfortunately, query planners are not always optimal -- sometimes, we can help out the query planner using our knowledge of the query or the underlying data, or by making changes to the database so that certain queries can be processed more efficiently.
This is a query plan generated in a postgreSQL database:
EXPLAIN SELECT *
FROM film f
INNER JOIN film_actor fa
ON f.film_id = fa.film_id
INNER JOIN actor a
ON fa.actor_id = a.actor_id;
QUERY PLAN
------------------------------------------------------------------------------
Hash Join (cost=83.00..196.65 rows=5462 width=421)
Hash Cond: (fa.actor_id = a.actor_id)
-> Hash Join (cost=76.50..175.51 rows=5462 width=396)
Hash Cond: (fa.film_id = f.film_id)
-> Seq Scan on film_actor fa (cost=0.00..84.62 rows=5462 width=12)
-> Hash (cost=64.00..64.00 rows=1000 width=384)
-> Seq Scan on film f (cost=0.00..64.00 rows=1000 width=384)
-> Hash (cost=4.00..4.00 rows=200 width=25)
-> Seq Scan on actor a (cost=0.00..4.00 rows=200 width=25)
(9 rows)
Most databases allow you to review a query plan, and most query plans look somewhat similar.
Our example is pretty straightforward, consisting of a select and some joins. The query plan shows us the steps the database is going to take in order to execute the query.
You can immediately see, from reviewing the plan, that different parts of the query correspond with different parts of the plan. “Hash joins” tell us which way the database is going to perform the join we’ve requested, and in particular we can see that the top hash join maps to the join between the film_actor table and the actor table in our query (in blue). We see another hash join for the other join in our query between the film and the film_actor table (in red).
By comparing the query with the plan we can usually identify which parts of the plan are linked to which parts of the query. The query plan has a nested, tree structure, so the steps are processed in inside-out order. In this plan, the first step that will be executed is the Sequential scan on films since that’s the innermost step in the plan (in green).
Common Optimizations
If you’re looking at a query plan generated by a database, it’s generally because the query is very slow and you’re trying to figure out how to make it faster. The following are a few of many ways to optimize different queries or the underlying data.
Predicate Pushdown
Predicate pushdown basically just means that we want to filter as much data as possible as early as possible. Here’s a query with a pattern that’s pretty common:
WITH (...) as complex_cte_1 , (...) as complex_cte_2 , (...) as complex_cte_3 SELECT * FROM complex_cte_3 WHERE user_id = 4
It’s a complicated query with lots of complicated steps in it, but at the very end we are filtering down to look at the results for just one user.
We only need the results from user number four, but depending on the nature of the intermediate queries and how well the query planner is able to parse the query, you could end up unnecessarily processing a lot of extra data.
What we can do to make this query faster is move the filter (WHERE user_id = 4) higher into the query so that the database knows to filter the data first and then perform all of the computations that are required:
WITH (... WHERE user_id = 4 ) as complex_cte_1 , (...) as complex_cte_2 , (...) as complex_cte_3 SELECT * FROM complex_cte_3
Often, moving filters upward in the query can dramatically shorten the query time by informing the query planner that it doesn’t actually have to process all of the data.
Adding Indexes
If you’re not familiar with indexes, check out the chapter where we discuss indexes in more detail!
Our query could also benefit from indexes. Consider the following plan from earlier:
EXPLAIN SELECT *
FROM film f
INNER JOIN film_actor fa
ON f.film_id = fa.film_id
INNER JOIN actor a
ON fa.actor_id = a.actor_id ;
QUERY PLAN
------------------------------------------------------------------------------
Hash Join (cost=83.00..196.65 rows=5462 width=421)
Hash Cond: (fa.actor_id = a.actor_id)
-> Hash Join (cost=76.50..175.51 rows=5462 width=396)
Hash Cond: (fa.film_id = f.film_id)
-> Seq Scan on film_actor fa (cost=0.00..84.62 rows=5462 width=12)
-> Hash (cost=64.00..64.00 rows=1000 width=384)
-> Seq Scan on film f (cost=0.00..64.00 rows=1000 width=384)
-> Hash (cost=4.00..4.00 rows=200 width=25)
-> Seq Scan on actor a (cost=0.00..4.00 rows=200 width=25)
(9 rows)
Our database is going to perform a sequential scan on all of the tables involved in this query. This means that the database is going to read the data from disk, row-by-row, for every row in each of these tables. For big tables, this can be extremely inefficient! When we see something like this, it often means we can speed up the relevant query by adding indexes to the database so that the query planner can use a more efficient search method to perform the join.
Data Distribution
The last important consideration about optimization is data distribution. In distributed databases, how the data is distributed across the different nodes can have a big impact on how much data the database needs to process in order to execute a query.
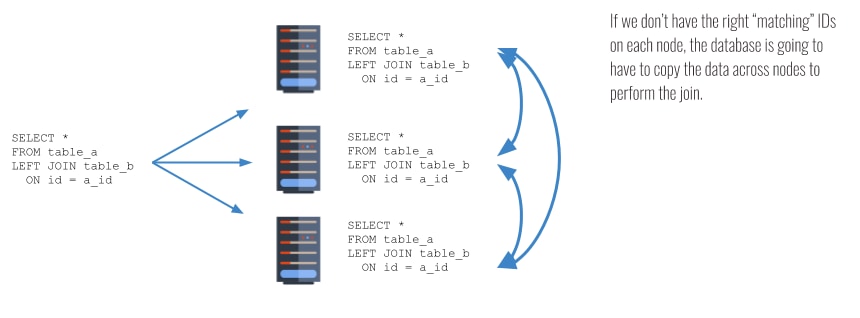
In the above example, if the data are distributed haphazardly across different nodes, then JOINs between tables can be very inefficient because the database has to move a lot of data between different nodes in order to complete the JOIN. Any time we move data between nodes, the query will slow down.
In this situation, we should either change how the data is distributed so that the database doesn’t have to shuffle any data, or add another join condition so that the query planner knows that it doesn’t need to shuffle the data in order to complete the query. A good example of this might be that if your data is distributed by user across different nodes, but you are joining on order_id, then you can speed up the query by adding a JOIN condition on user ID, so that you are joining on both order_id and user_id. This doesn’t change the logic of the query at all, but it does provide extra information to the query planner so that it can perform the join more efficiently.
Query Planning in a Nutshell
The key takeaway from this lesson is that the query planner takes a declarative input, the query, and uses that to create an imperative plan for returning results to the user. By inspecting the query plan we can make our queries faster by either changing the underlying structure of our data or re-writing our queries to give the query planner more explicit instructions.







