

ASCII files, delimited by commas or tabs are commonly used internally within organizations to quickly and easily move data. The main advantage of files is that they are easy to create and move, especially across dissimilar platforms. Many data providers use files to share information about supply chains, financial markets and all other aspects of a business. Even though there has been a rise in purpose built data-sharing technologies by specific vendors and an increase in APIs, there is still a vast amount of data shared via files.
Modern file encodings such as Parquet and AVRO offer advanced functionality for storing text data by optimizing readability performance and including metadata, such as column names and types. By contrast, the ubiquitous Comma Separated Values (CSV) format may have column names but will never have type definitions for the columns. This results in data being quickly loaded as pure text thereby leaving common mathematical functions, such as max/min, unable to be implemented without additional development. Another hurdle is managing compression. Compression has the advantage of reducing file size to a fraction of the original, but compression also has the disadvantage of developers understanding and dealing with different compression techniques as well as provisioning extra space to decompress the file for importing.
Fivetran provides a simple interface that manages all of these problems in a couple of clicks. With a little guidance, vast amounts of file data can be loaded into ordered and fully defined tables and columns. Data is reliably loaded and ready to use in minutes. This post will outline the process. (Note: The verbiage, screenshots and examples illustrate loading files from an Amazon S3 bucket, but the same functionality is available from Google Drive, FTP(s), etc.)
In a standard CSV file the number of columns are consistent across every row. Our use case describes the default settings of ingesting standard CSV files into a Fivetran supported target environment. This could represent the export of a single database table or spreadsheet.
Part 1: Configuring the files to be loaded
Fivetran makes loading CSV files very easy. Let’s assume you’ve been asked to load CSV files from a S3 bucket. The only “knowns” are the first line contains the column names and the file format is valid (i.e. each row has the same number of fields). The files are found in the location: s3://millman-file-test/simpleCSV/. For simplicity of this post, the bucket was set up as ‘public’ to make it easily accessible and have less security configuration. You, probably, would not have a public bucket in a production setting.
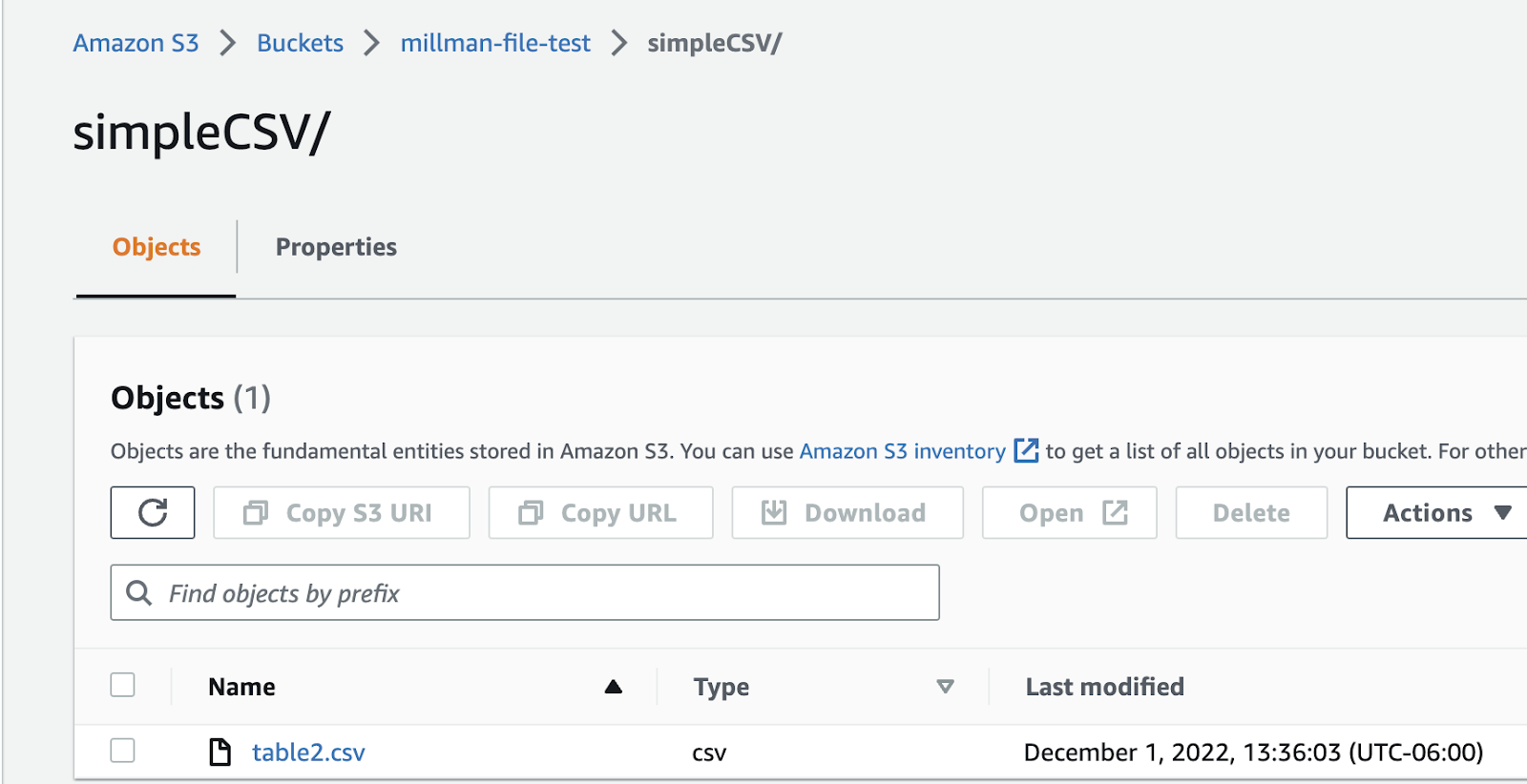
Setup and ingest of this file should take approximately 5-10 minutes. Within the Fivetran UI, select (or create and select) the required destination, then select “Add Connector” and enter “S3” in the search box. Select the “Amazon S3” connector (shown below).

Like all Fivetran connectors, a simple configuration form is presented (shown below). Enter the name of the schema and table for the target database, the name of the bucket and the folder path. Ensure “public” is selected/enabled. Note, by setting the optional folder path, any file found in the directory and sub-directories will be read into the specified destination (refer to the S3 image above). All other values are defaulted.

In the above image, file type and compression are set to “infer.” Using “infer,” the Fivetran file connector handles file types based on extensions. The following tables show the common file and compression types.
Similarly, the following compression formats are automatically inferred using “infer.” The following table shows the handled compression types.
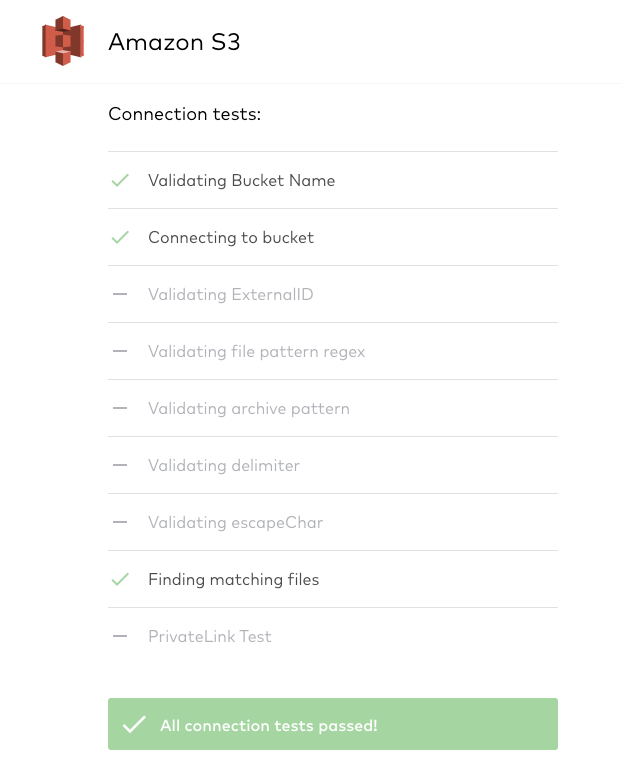
Select “Save & Test.” Fivetran will validate the configuration, including connectivity to the S3 files, file formats, etc (shown below).
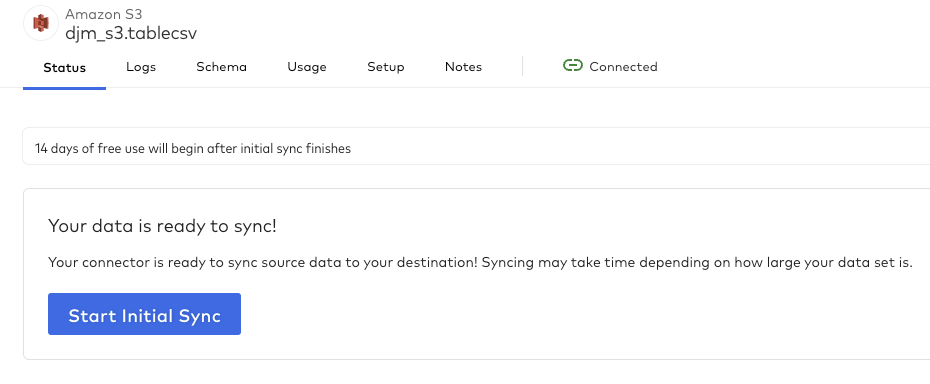
That was fast…the files are ready to be loaded! Select “Start Initial Sync” to begin the process of loading the files from the S3 bucket into the destination.
Part 2: File loading results
In traditional ETL scenarios before data is loaded, a destination admin must be involved to create the destination objects to hold the file data. But…this was not done in Part 1 …why? Simply put, the process of creating and managing schema and table definitions is handled automatically by Fivetran in the destination! See the BigQuery image below.
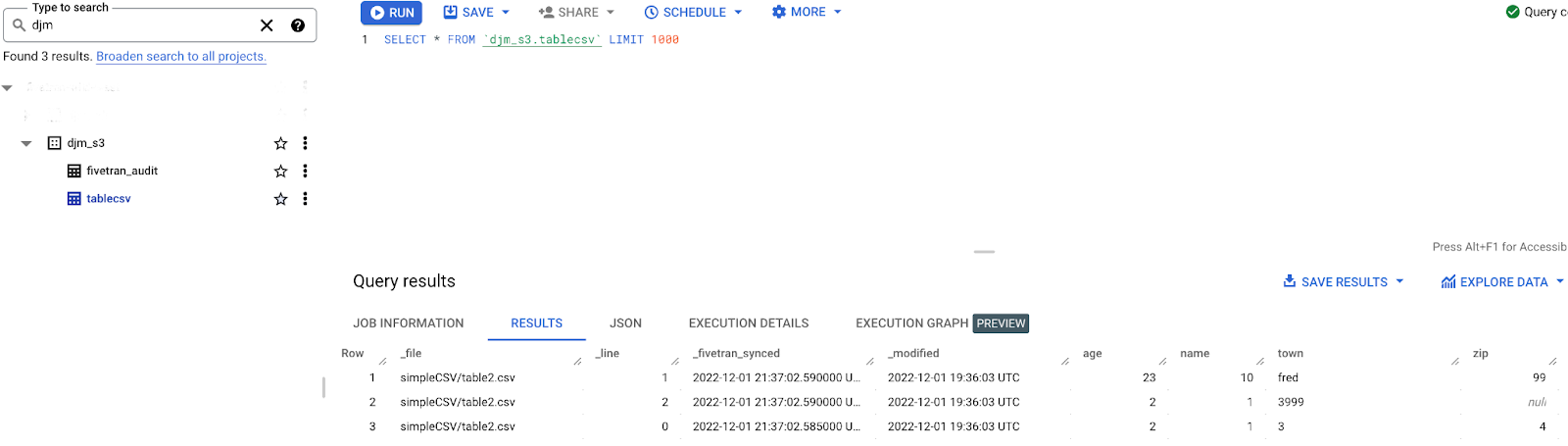
The two tables created in the schema djm_s3 are tablecsv that contains the contents of the file and fivetran_audit that contains metadata about Fivetran data loading (discussed later). The query shown displays the data loaded from the files.
There are two sets of columns in the tablecsv table. One set contains the columns from the zip files (age, name, town and zip). The second set contains columns with the Fivetran loading metadata (_file, _line, _fivetran_synced and _modified). The metadata columns are defined in the table below.
Interesting item to note: when the columns in the table DDL are reviewed, something becomes apparent. The columns age, name, town and zip, as shown below, have defined data types. At no point during configuration did we type the date; so how did this happen?
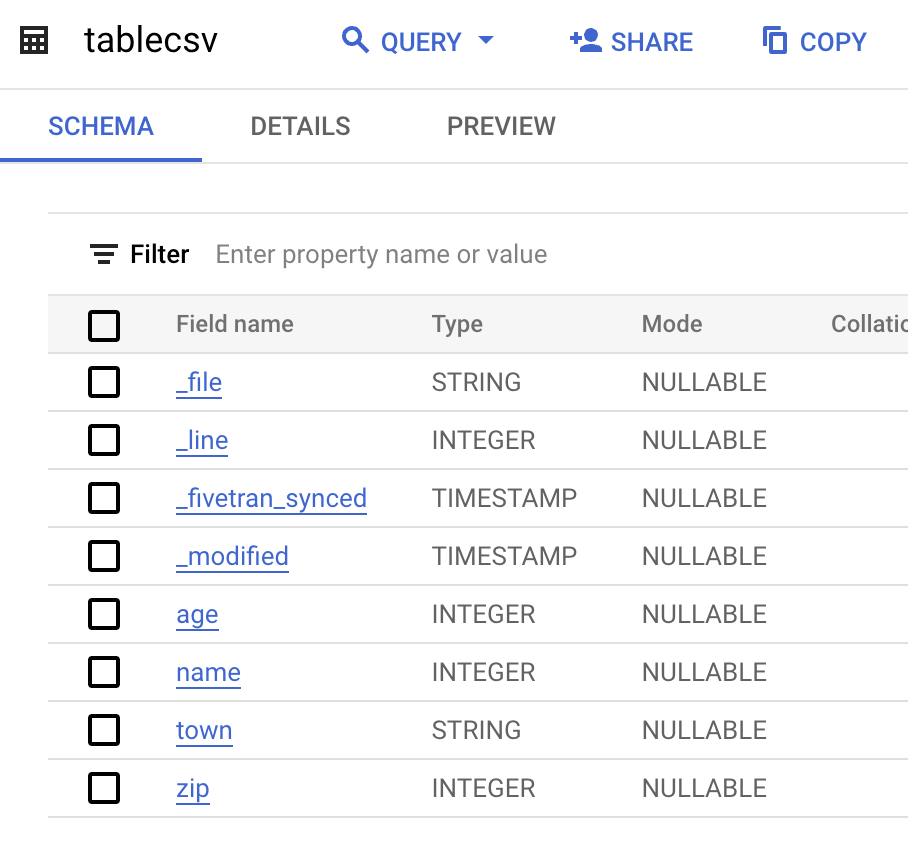
The answer is described here. For every connector, Fivetran implements an inference process on the columns/data. The inference process reviews the data and selects the type using the data type hierarchy. The town column became a string and all the other input columns became integers. The same process is used upon every ingestion iteration. If the column was an integer, for example, but now contains non-integer characters, the column DDL is automatically updated to be a string. Also, column names are determined by the file headers. So, the header row is required
Summation
In just a few minutes, a CSV file of unknown structure has been loaded from AWS S3 to Google BigQuery with the correct column data typing as well as supporting metadata. This fundamentally changes the cost of loading ASCII data trapped in files on any file system. As Fivetran treats all destinations equally, the results would be the same for Databricks, Redshift, Snowflake and Synapse all with the same amount of configuration.
In just a few minutes, it is now possible for data innovators such as data scientists and BI analysts to start rapidly deriving new insights.
[CTA_MODULE]













.png)
.svg)
.svg)
.svg)